
 Backend Development
XML/RSS Tutorial
Detailed introduction to using XML thinking to organize data (picture)
Backend Development
XML/RSS Tutorial
Detailed introduction to using XML thinking to organize data (picture)
Detailed introduction to using XML thinking to organize data (picture)

Preface
Times have changed.
In the past, data was mostly entered manually and transferred from terminals with dedicated network protocols to big iron boxes in "glass houses". Now information is everywhere and everywhere, but it may not always be summarized in your company. , many times we share data in a "flat" world, where there are more channels for information sources and the information itself changes more frequently. Not only that, with the emergence of a series of concepts such as Web 2.0, Enterprise 2.0 and Internet Service Bus, you find that it is far less convenient to find the warehouse address provided by the supplier from your own "glass house" than Google Map.
It seems that all the shackles that have restricted data in the past have been broken one by one under the Internet, but as IT practitioners, our job is to provide users with the data they need and the means they want to obtain information, so application It must be able to withstand various changes, including changes in the user interface that we were concerned about in the past, changes in calls between applications, changes in internal logic of applications, and the increasingly faster pace but the most fundamental change - changes in the data itself. .
RelationshipModel tells us to use two-dimensional tables to describe the information world, but this is too "un" natural. Take a look at a book or It is the home decoration plan and the task breakdown of the soon-to-be-started project. It seems that it is not appropriate to put it into a two-dimensional table. Moreover, even if it is cut down to the last detail through "entity-relationship", it will always be necessary in the rapidly changing environment. It involves a series of changes in "data-application-front-end interaction", and often affects the whole body.
It seems that many new generation applications have found a solution that is more suitable for the new trend - XML, organizing applications and user experience in a way that is closer to our own thinking. So for enterprises, can the relatively basic work of organizing data also be carried out using XML thinking? it should be OK.
Coping with changes in the data entities themselves
Data entities have always been assumed to be the most stable part of the application, whether we use design patterns or use various open source Development frameworks (including these frameworks themselves) are all trying to adapt to the changes in the application itself. So what is the actual situation?
l The data entities we need to exchange often change according to the needs of ourselves and our partners;
l The data entities given to us by our partners also often change;
l With With the introduction of SOA and Enterprise 2.0 concepts, the data entities themselves are mash up from multiple sources, and the data entities themselves are also repeatedly assembled and combined;
l As the business becomes more refined, our own employees We always hope to obtain more and more abundant and detailed information;
Therefore, in the past, the data entities that were thought to be the earliest to be fixed depending on the needs and design are becoming more and more agile in the field of technology and Business status quo requires constant adjustments. In order to adapt to this requirement, we can start from the top down and constantly adjust the flexibility of the application itself; another way is to deal with this problem from the "root" and adopt new data models that can continuously adapt to these changes, such as: XML data model and XML-related technology families.
For example, when defining a user entity, the following information is enough initially, where ICustomer is the user interface that the application will use, and CUSTOMER is the representation in relational database mode, is XML:
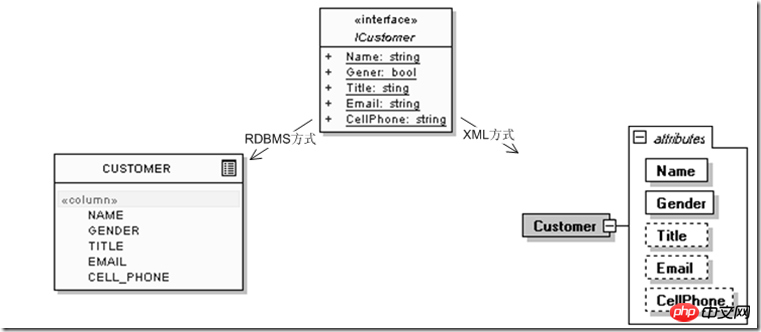
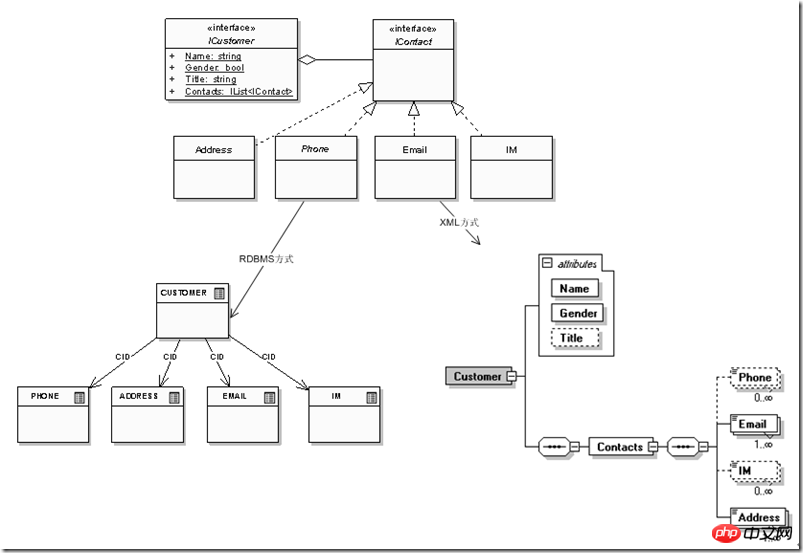
It is not difficult to see that although it is just a change in the "contact information" at the end of the "customer" data entity, there is a very big difference between the relational model and the XML model in terms of adaptability. The relational model needs to continuously expand new relational uses. To describe continuously refined data entities, the hierarchical nature of the XML model itself can provide its own continuous extension and expansion under changing conditions. In actual projects, similar problems exist with information such as "education status" and "work experience status". Under the relationship model, even if a customer wants to add the "secondment" method of work status at a certain stage, they will find that there is no such information in the design. The corresponding fields are reserved, so I have to put it as a string"rubbed" in the "work unit" field, followed by "(seconded)", which is equivalent to the rigid data model itself obliterating the data. The information included in the business semantics; the hierarchical model can describe it as a child node or attribute, so that not only can multiple relationships (customers, education status, work experience, contact information) be included under the relational model ) are concentrated inside a data entity, and the extended information of each entity itself (such as "working mode": secondment, exchange, short-term concentration), etc. can also be described inside the data entity, and at the same time, the "customer" entity itself can be viewed from external applications It is still an entity, so that using data entities that are closer to real business scenarios can more effectively adapt to external changes.
What we discussed above is only one data entity. When we further develop into specific business domain models, we often need to integrate multiple data entities at the same time to collaborate to complete business functions. What about this situation? For example: the insurance policy requires customers to provide personal health information, children, parents, and partner's main family member information in addition to the above information. At the same time, the user's credit information will be obtained from other institutions, and different data entity combinations are mainly used within the enterprise. Different application fields, so from the perspective of data usage, in order to make the application part as stable as possible, it is best for the data entity to be stable, but only the contact information part of the user information may change repeatedly. If the application is completely dependent on a combination of these changing factors As a result, it is indeed difficult to guarantee the stability of the application. So the first step from the source is to try to ensure that different applications rely only on a specific entity as much as possible. This may be the first step to effective improvement. At this time, the advantages of XML's hierarchical characteristics are shown again. comes out, for example, we can freely combine this information according to different application themes:
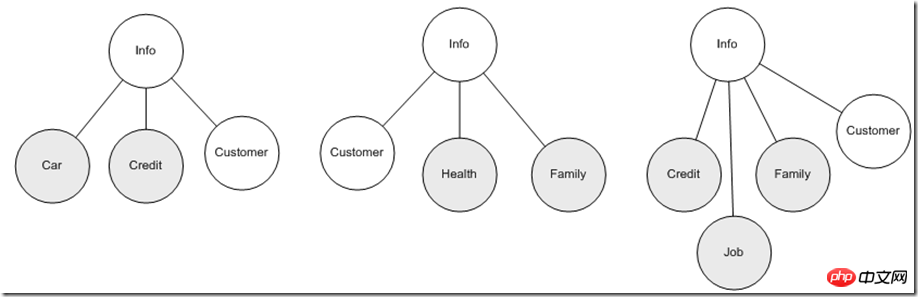
In this way, the application faces a unified
Coping with the integration of data and content
The data entities mentioned above are discussed more in a centralized context, but in addition to conceptual design, there are also A specific problem is how to "gather" them together, which is generally achieved through dataset.
(However, just as the word "architecture" is overused, "data integration" is also defined by various manufacturers as a combination of different concepts based on their own product characteristics, such as BI Vendors try to portray it as synonymous with ETL. Vendors that provide data exchange platforms describe it as products that implement BizTalk Framework. For SOA product companies , Data integration is more about how to ensure the provision of data services under the premise of effective governance. In addition, for some manufacturers, data integration also includes business semantic combination, etc.)
But as a user, data integration. What issues should we focus on?
l The mapping relationship of data entities;
l The interconnection of data sources under various exchange protocols, industry data standards, and security control constraints;
l The data exchange process Arrangement;
l Verification and reconstruction of data entities;
l Conversion of data media and data carriers;
Although in theory these tasks are not a problem to complete with coding, However, as enterprise integration logic becomes more and more complex and changes faster and faster, even if you can modify the code to cope with 1:N integration, if it is often an M:N situation, it will be insufficient. Is there a simpler way? Just speaking from the logical level of "mapping":
l Object-orientedThe idea tells us to rely on inversion, try to rely on abstraction rather than concreteness, such as relying on interfaces rather than entity types;
l Design patterns tell us that incompatible interface adapters (Adapters) are a good way;
So are there similar technologies in the data field? XML Schema + XSLTmay be an option.
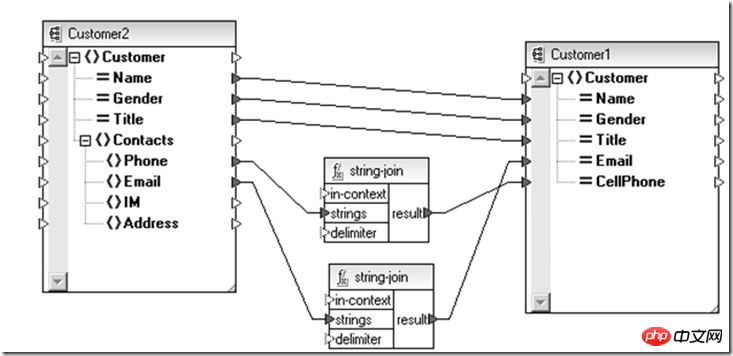
The above is a conversion done to be compatible with new and old user entities. Similarly, if you need to perform the above part of the data entity aggregation operation for different subjects, you can also use it. It is completed at the abstract data definition (Schema) level through XSLT (adaptation relationship between Schemas).
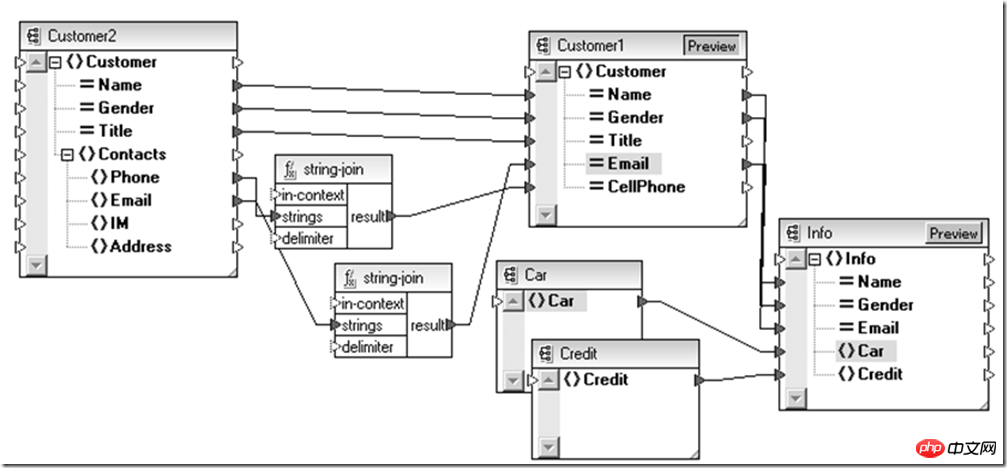
In this way, we can see how the data is aggregated at the data entity level, but there is still a problem that needs to be solved before: vehicle information, credit information and legacy systems The customer information is stored in the relational database and the partner's Web Service respectively. How to connect this data channel? From now on, XML is still a good choice.
Data on different data media can be extracted in their original form, such as plain text, relational database, EDI message or SOAP message, and passed to data integration through different information channels aggregation point, and then convert heterogeneous data sources through an adapter according to the needs of the destination data source.
At this time, if a point-to-point adapter is designed for each two types, the overall scale will develop along the N^2 level trend. For this reason, you might as well unify them into XML that is compatible with this information, and then use After the XSLT technology introduced above performs mapping between data entities, it then converts the XML into the form required by the target data source, so that the complexity of the entire adaptation system is reduced to N level.
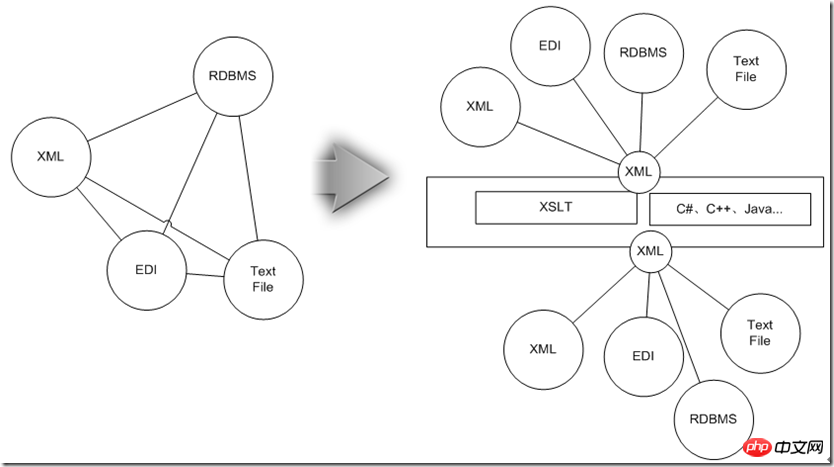
Next, let’s look at how XML technology meets the prerequisite data integration requirements:
l Mapping of data entities, data media, and data carriers Conversion, verification and reconstruction of data entities:
As above, the data is first uniformly converted into XML, and then processed using the advantages of XML hierarchy and combined with XML-specific technology.
l The interconnection of data sources under various exchange protocols, industry data standards, and security control constraints;
XML data can not only cross networks and firewalls, but can also be easily used on the Internet environment (but you can still define them as messages using the messagequeue method), the data itself will not be restricted by the exchange protocol due to special binary operations. Currently, various industry standards are basically using XML to describe their own industry DM (Data Modal). Even if the data entities of your internal system itself do not conform to these DMs due to issues such as database design and historical legacy, various The protocols and standards for unified management of XML data can facilitate conversion. Regarding security, it seems that there is no security standard family more suitable for the Internet environment than the WS-* related protocols. All standards, without exception, can use XML entities to define the combination relationship between data and additional security mechanisms.
l Orchestration of data exchange process;
For homogeneous system environments, or platforms based only on compatible middleware systems, legacy workflow mechanisms can be used For the orchestration of the data exchange process, in order to adapt to the service-oriented era, the more general BPEL standard can be adopted. At this time, XML is not only data, but also appears as a form of execution instructions. Compared with Java technology, which has always been advertised as cross-platform, In other words, the exchange process defined by XML is even more cross-language.
It seems that integration has solved a lot of problems, but an obvious problem is that we may have to do some implementation of all the work ourselves and tell the application step by step how to do it. Then when we no longer regard the Web as just "New things", when considering it as a system that serves our information content and can interact, how can we present these scattered service capabilities to ourselves? At this time, perhaps the advantages of XML's open metadata definition will really come to light.
Coping with the complexity of the semantic network
In addition to various semantic algorithms, how to aggregate various scattered services to provide us with services, one of the very key factors of XML is Find the backbone of the data clues, and clarify the relationships between entities on this backbone and the process of gradual decomposition and refinement. Data at this level are not only objects that are passively called by the application, they themselves provide support for further inferences by the application. For example:
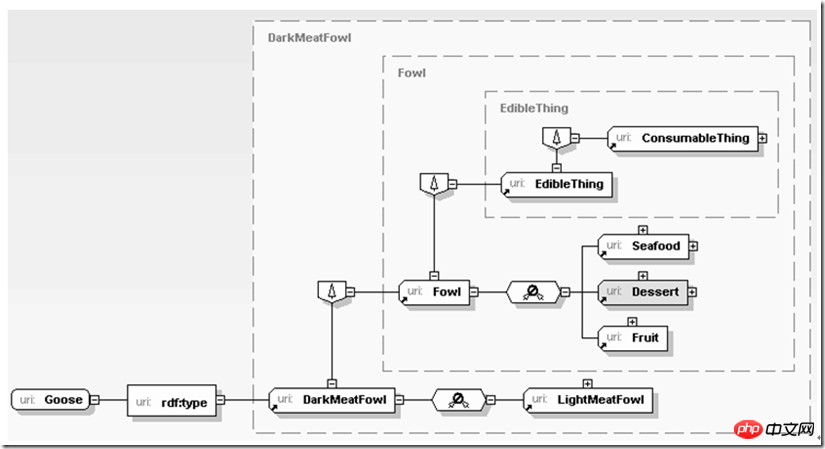
Here, the application first learns that the object currently being processed is goose meat. Since goose meat is a kind of dark meat, and dark meat is some kind of poultry meat (fowl), poultry meat is edible, so the application can gradually infer that goose meat is It is edible. The above inference process is not complicated, but if it is implemented using a relational database, it is relatively complicated. If it is written in plain text, it is even more difficult to implement. Imagine if all the relationships between poultry, vegetables, desserts, and seafood are expressed using relationships. Database or text writing is really "difficult" to use. XML is different. It can be naturally close to our thinking habits and describe our familiar semantics in an open but intertwined way, whether it is the production material preparation process in the enterprise ERP environment or preparing to cook for a birthday party. The same goes for purchasing plans.
Summary
Perhaps limited by the constraints of the two-dimensional grid for too long, our design and ideas for applications are increasingly constrained by computer processing itself, but as the business environment changes, The time between the occurrence of business requirements and the implementation and launch of applications is getting shorter and shorter. We need to withdraw our thinking from the computer. At this time, it seems more preferable to adopt a data technology that is more open and close to our divergent thinking. For organizations after the data is implemented, we can continue to use various mature technologies to complete it, but at a closer business level and closer to this more volatile environment, XML seems to be flexible and powerful.
The above is the detailed content of Detailed introduction to using XML thinking to organize data (picture). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
Use ddrescue to recover data on Linux
Mar 20, 2024 pm 01:37 PM
DDREASE is a tool for recovering data from file or block devices such as hard drives, SSDs, RAM disks, CDs, DVDs and USB storage devices. It copies data from one block device to another, leaving corrupted data blocks behind and moving only good data blocks. ddreasue is a powerful recovery tool that is fully automated as it does not require any interference during recovery operations. Additionally, thanks to the ddasue map file, it can be stopped and resumed at any time. Other key features of DDREASE are as follows: It does not overwrite recovered data but fills the gaps in case of iterative recovery. However, it can be truncated if the tool is instructed to do so explicitly. Recover data from multiple files or blocks to a single
 Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
Open source! Beyond ZoeDepth! DepthFM: Fast and accurate monocular depth estimation!
Apr 03, 2024 pm 12:04 PM
0.What does this article do? We propose DepthFM: a versatile and fast state-of-the-art generative monocular depth estimation model. In addition to traditional depth estimation tasks, DepthFM also demonstrates state-of-the-art capabilities in downstream tasks such as depth inpainting. DepthFM is efficient and can synthesize depth maps within a few inference steps. Let’s read about this work together ~ 1. Paper information title: DepthFM: FastMonocularDepthEstimationwithFlowMatching Author: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
Google is ecstatic: JAX performance surpasses Pytorch and TensorFlow! It may become the fastest choice for GPU inference training
Apr 01, 2024 pm 07:46 PM
The performance of JAX, promoted by Google, has surpassed that of Pytorch and TensorFlow in recent benchmark tests, ranking first in 7 indicators. And the test was not done on the TPU with the best JAX performance. Although among developers, Pytorch is still more popular than Tensorflow. But in the future, perhaps more large models will be trained and run based on the JAX platform. Models Recently, the Keras team benchmarked three backends (TensorFlow, JAX, PyTorch) with the native PyTorch implementation and Keras2 with TensorFlow. First, they select a set of mainstream
 Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Slow Cellular Data Internet Speeds on iPhone: Fixes
May 03, 2024 pm 09:01 PM
Facing lag, slow mobile data connection on iPhone? Typically, the strength of cellular internet on your phone depends on several factors such as region, cellular network type, roaming type, etc. There are some things you can do to get a faster, more reliable cellular Internet connection. Fix 1 – Force Restart iPhone Sometimes, force restarting your device just resets a lot of things, including the cellular connection. Step 1 – Just press the volume up key once and release. Next, press the Volume Down key and release it again. Step 2 – The next part of the process is to hold the button on the right side. Let the iPhone finish restarting. Enable cellular data and check network speed. Check again Fix 2 – Change data mode While 5G offers better network speeds, it works better when the signal is weaker
 The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
The vitality of super intelligence awakens! But with the arrival of self-updating AI, mothers no longer have to worry about data bottlenecks
Apr 29, 2024 pm 06:55 PM
I cry to death. The world is madly building big models. The data on the Internet is not enough. It is not enough at all. The training model looks like "The Hunger Games", and AI researchers around the world are worrying about how to feed these data voracious eaters. This problem is particularly prominent in multi-modal tasks. At a time when nothing could be done, a start-up team from the Department of Renmin University of China used its own new model to become the first in China to make "model-generated data feed itself" a reality. Moreover, it is a two-pronged approach on the understanding side and the generation side. Both sides can generate high-quality, multi-modal new data and provide data feedback to the model itself. What is a model? Awaker 1.0, a large multi-modal model that just appeared on the Zhongguancun Forum. Who is the team? Sophon engine. Founded by Gao Yizhao, a doctoral student at Renmin University’s Hillhouse School of Artificial Intelligence.
 Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
Tesla robots work in factories, Musk: The degree of freedom of hands will reach 22 this year!
May 06, 2024 pm 04:13 PM
The latest video of Tesla's robot Optimus is released, and it can already work in the factory. At normal speed, it sorts batteries (Tesla's 4680 batteries) like this: The official also released what it looks like at 20x speed - on a small "workstation", picking and picking and picking: This time it is released One of the highlights of the video is that Optimus completes this work in the factory, completely autonomously, without human intervention throughout the process. And from the perspective of Optimus, it can also pick up and place the crooked battery, focusing on automatic error correction: Regarding Optimus's hand, NVIDIA scientist Jim Fan gave a high evaluation: Optimus's hand is the world's five-fingered robot. One of the most dexterous. Its hands are not only tactile
 The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
The first robot to autonomously complete human tasks appears, with five fingers that are flexible and fast, and large models support virtual space training
Mar 11, 2024 pm 12:10 PM
This week, FigureAI, a robotics company invested by OpenAI, Microsoft, Bezos, and Nvidia, announced that it has received nearly $700 million in financing and plans to develop a humanoid robot that can walk independently within the next year. And Tesla’s Optimus Prime has repeatedly received good news. No one doubts that this year will be the year when humanoid robots explode. SanctuaryAI, a Canadian-based robotics company, recently released a new humanoid robot, Phoenix. Officials claim that it can complete many tasks autonomously at the same speed as humans. Pheonix, the world's first robot that can autonomously complete tasks at human speeds, can gently grab, move and elegantly place each object to its left and right sides. It can autonomously identify objects
 The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
The U.S. Air Force showcases its first AI fighter jet with high profile! The minister personally conducted the test drive without interfering during the whole process, and 100,000 lines of code were tested for 21 times.
May 07, 2024 pm 05:00 PM
Recently, the military circle has been overwhelmed by the news: US military fighter jets can now complete fully automatic air combat using AI. Yes, just recently, the US military’s AI fighter jet was made public for the first time and the mystery was unveiled. The full name of this fighter is the Variable Stability Simulator Test Aircraft (VISTA). It was personally flown by the Secretary of the US Air Force to simulate a one-on-one air battle. On May 2, U.S. Air Force Secretary Frank Kendall took off in an X-62AVISTA at Edwards Air Force Base. Note that during the one-hour flight, all flight actions were completed autonomously by AI! Kendall said - "For the past few decades, we have been thinking about the unlimited potential of autonomous air-to-air combat, but it has always seemed out of reach." However now,
