

This article mainly introduces the implementation of cassandra advanced operations in JavaPaging examples (with specific project requirements), which has certain reference value. Interested friends can refer to it.
The last blog talked about cassandra paging. I believe everyone will pay attention to it: the next query depends on the previous query (all primary keys of the last record in the previous query). It is not as flexible as mysql, so it can only implement the functions of the previous page and the next page, but cannot implement the function of the first page (if it is forced to be implemented, the performance will be too low).
Let’s take a look at the driverOfficial paging method
If the number of records obtained by a query is too large and returned at once, the efficiency is very low and very It is possible to cause memory overflow and cause the entire application to crash. So, the driver paging the result set and returning the appropriate page of data.
1. Setting the fetch size
The fetch size refers to the number of records obtained from cassandra at one time , in other words, it is the number of records on each page; we can specify a default value for its fetch size when creating the cluster instance. If not specified, the default is 5000
// At initialization:
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
// Or at runtime:
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);In addition, the statement You can also set fetch size
Statement statement = new SimpleStatement("your query");
statement.setFetchSize(2000);If fetch size is set on the statement, then the fetch size of the statement will take effect, otherwise the fetch size on the cluster will take effect.
Note: Setting fetch size does not mean that cassandra always returns an accurate result set (equal to fetch size). It may return a result set that is slightly more or less than fetch size.
2. Result set iteration
fetch size limits the number of result sets returned for each page. If you iterate a certain page, The driver will automatically capture the next page of records in the background. As in the following example, fetch size = 20:
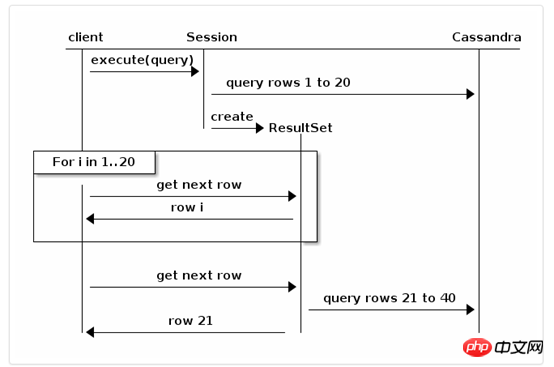
By default, background automatic fetching occurs at the last moment, that is, when the records of a certain page have been iterated. If you need better control, the ResultSet interface provides the following methods:
getAvailableWithoutFetching() and isFullyFetched() to check the current state; fetchMoreResults() to force a page fetch;
The following is how to use these methods to pre-fetch the next page in advance to avoid having to wait until a certain page is iterated. Performance degradation caused by crawling the next page:
ResultSet rs = session.execute("your query");
for (Row row : rs) {
if (rs.getAvailableWithoutFetching() == 100 && !rs.isFullyFetched())
rs.fetchMoreResults(); // this is asynchronous
// Process the row ...
System.out.println(row);
}3. Save and reuse paging Status
Yes When saving the paging state, it is very useful for future recovery. Imagine: there is a stateless web service that displays a list of results and a link to the next page. When the user clicks this link, we need to execute Exactly the same query as before, except that the iteration should start from where the previous page stopped; it is equivalent to remembering where the previous page has been iterated, and then the next page can start from here.
To do this, the driver exposes a PagingState object that represents our position in the result set when the next page is fetched.
ResultSet resultSet = session.execute("your query");
// iterate the result set...
PagingState pagingState = resultSet.getExecutionInfo().getPagingState();
// PagingState对象可以被序列化成字符串或字节数组
String string = pagingState.toString();
byte[] bytes = pagingState.toBytes();The serialized content of the PagingState object can be stored persistently, and can also be used as a parameter for paging requests in order to be used again later. Just deserialize it into an object:
PagingState.fromBytes(byte[] bytes); PagingState.fromString(String str);
Please note that paginated state can only be used repeatedly with exactly the same statement (same query, same parameters). Moreover, it is an opaque value and is used only to store a state value that can be reused. If you try to modify its content or use it on a different statement, the driver will throw an error.
Let’s look at the code specifically. The following example is a simulated page paging request to traverse all records in the teacher table:
Interface:
import java.util.Map;
import com.datastax.driver.core.PagingState;
public interface ICassandraPage
{
Map<String, Object> page(PagingState pagingState);
}Main code:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
import com.datastax.driver.core.SimpleStatement;
import com.datastax.driver.core.Statement;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.factory.SessionRepository;
import com.huawei.cassandra.model.Teacher;
public class CassandraPageDao implements ICassandraPage
{
private static final Session session = SessionRepository.getSession();
private static final String CQL_TEACHER_PAGE = "select * from mycas.teacher;";
@Override
public Map<String, Object> page(PagingState pagingState)
{
final int RESULTS_PER_PAGE = 2;
Map<String, Object> result = new HashMap<String, Object>(2);
List<Teacher> teachers = new ArrayList<Teacher>(RESULTS_PER_PAGE);
Statement st = new SimpleStatement(CQL_TEACHER_PAGE);
st.setFetchSize(RESULTS_PER_PAGE);
// 第一页没有分页状态
if (pagingState != null)
{
st.setPagingState(pagingState);
}
ResultSet rs = session.execute(st);
result.put("pagingState", rs.getExecutionInfo().getPagingState());
//请注意,我们不依赖RESULTS_PER_PAGE,因为fetch size并不意味着cassandra总是返回准确的结果集
//它可能返回比fetch size稍微多一点或者少一点,另外,我们可能在结果集的结尾
int remaining = rs.getAvailableWithoutFetching();
for (Row row : rs)
{
Teacher teacher = this.obtainTeacherFromRow(row);
teachers.add(teacher);
if (--remaining == 0)
{
break;
}
}
result.put("teachers", teachers);
return result;
}
private Teacher obtainTeacherFromRow(Row row)
{
Teacher teacher = new Teacher();
teacher.setAddress(row.getString("address"));
teacher.setAge(row.getInt("age"));
teacher.setHeight(row.getInt("height"));
teacher.setId(row.getInt("id"));
teacher.setName(row.getString("name"));
return teacher;
}
}Test code:
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.dao.impl.CassandraPageDao;
public class PagingTest
{
public static void main(String[] args)
{
ICassandraPage cassPage = new CassandraPageDao();
Map<String, Object> result = cassPage.page(null);
PagingState pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
while (pagingState != null)
{
// PagingState对象可以被序列化成字符串或字节数组
System.out.println("==============================================");
result = cassPage.page(pagingState);
pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
}
}
}Let’s take a look at the setPagingState(pagingState) method of Statement:
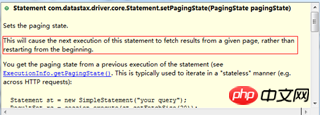
4. Offset query
Saving the paging state can ensure that moving from a certain page to the next page runs well (the previous page can also be implemented), but it does not satisfy random jumps, such as jumping directly to page 10, because we don’t know The paging status of the previous page of page 10. Features like this that require offset queries are not natively supported by cassandra. The reason is that offset queries are inefficient (performance is linearly inversely proportional to the number of skipped rows), so cassandra officially discourages the use of offsets. If we have to implement offset query, we can simulate it on the client side. However, the performance is still linearly inversely proportional, which means that the larger the offset, the lower the performance. If the performance is within our acceptance range, it can still be achieved. For example, each page displays 10 lines, and a maximum of 20 pages can be displayed. This means that when displaying the 20th page, up to 190 additional lines need to be fetched, but this will not cause a big reduction in performance. Therefore, if the amount of data is not large, it is still possible to simulate offset query.
For example, assuming that each page displays 10 records, the fetch size is 50, and we request page 12 (that is, rows 110 to 119):
1. First The query is executed once, and the result set contains rows 0 to 49. We do not need to use it, only the paging status is needed;
2. Use the paging status obtained from the first query to execute the second query;
3. Use the paging status obtained from the second query to execute the third query. The result set contains 100 to 149 rows;
4. Using the result set obtained by the third query, first filter out the first 10 records, then read 10 records, and finally discard the remaining records and read The 10 records are the records that need to be displayed on page 12.
We need to try to find the best fetch size to achieve the best balance: too small means more queries in the background; too large means returning a larger amount of information and more unnecessary OK.
In addition, cassandra itself does not support offset query. On the premise of satisfying performance, the implementation of client-side simulation offset is only a compromise. The official recommendations are as follows:
1. Use expected query patterns to test the code to ensure that the assumptions are correct
2. Set a hard limit for the highest page number to prevent malicious users from triggering large skipping Row query
5. Summary
Cassandra has limited support for paging, and the previous page and next page are easier to implement. Offset query is not supported. If you insist on implementing it, you can use client simulation. However, this scenario is best not to be used on cassandra, because cassandra is generally used to solve big data problems, and offset Once the amount of data in the query is too large, the performance cannot be complimented.
In my project, Index repair uses cassandra's paging. The scenario is as follows: the cassandra table does not have a secondary index, and elasticsearch is used to implement the secondary index of the cassandra table. Then It will involve the issue of index consistency repair. Cassandra's paging is used here to traverse the entire table of a certain table in Cassandra and match it with the data in elasticsearch one by one. If it does not exist in elasticsearch, it will be in elasticsearch. Added, if it exists but is inconsistent, fix it in elasticsearch. How elasticsearch implements the indexing function of cassandra will be specifically explained in my subsequent blog, so I won’t go into details here. When traversing the entire cassandra table, paging is needed because the amount of data in the table is too large, and it is impossible to load hundreds of millions of data into the memory at once.
The above is the detailed content of Java implements paging example of cassandra advanced operation (picture). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



