

1. Introduction
Last week I needed to understand some general content of the project, but I was confused about the xml parsing section, so I Here I will record some of the knowledge I learned about xml parsing.
2. Analysis
android There are three main types of xml parsers in , DOM parser, SAX parser and pull parser
1. DOM parser
DOM(Document Object Model) is an ObjectModel for XML documents that can be used to directly access XML documents Each part. It loads the content into the memory at once and generates a tree structure. It does not involve callbacks and complex status management. The disadvantage is that it is inefficient when loading large documents, so it is generally used. DOM parsing is not recommended when parsing large documents.
Parsing this structure usually requires loading the entire document and constructing a tree structure before retrieving and updating node information. . Using the objects in the DOM, you can read, search, modify, add and delete How the DOM works: Use the DOM. When operating on an XML file, the file must first be parsed and divided into independent elements,
attributesand comments, etc., and then the XML file is processed in the memory in the form of a node tree. means that you can access the content of the document through the node tree and modify the document as needed Commonly used DOM interfaces
and classes:Document: The The interface defines a series of methods for analyzing and creating DOM documents. It is the root of the
document tree
Node: This interface provides processing and obtaining node and sub-node values. Method.
Element: This interface
inherits the
NodeList#. ##: Provides methods to obtain the number of nodes and the current node. This allows you to iteratively access each node.
DOMParser: This class is the DOM parser class in Apache's Xerces, which can directly parse XML files.
2. SAX parsing
SAX(Simple API
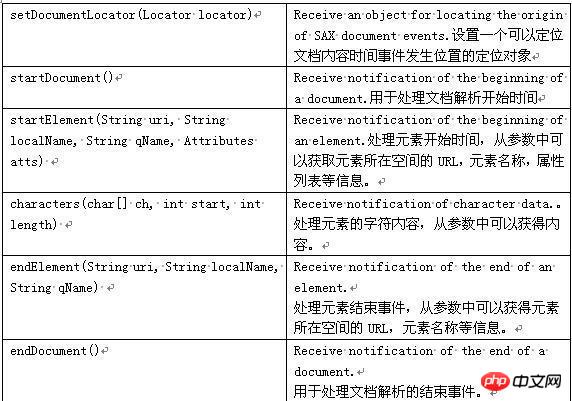
for XML) Using streaming processing, it does not record information about the content it reads. It is an XML API that uses events as driver, which has fast parsing speed and takes up less memory. Use Callback function to achieve this. The disadvantage is that it cannot be rolled back because it is event-driven. Its core is the Event processing
mode, which mainly works around event sources and event processors. When the event source generates an event, call the corresponding processing method of the event processor, and an event can be processed. When the event source calls a specific method in the event handler, it must also pass the status information of the corresponding event to the event handler, so that the event handler can decide its
based on the provided event information. The working principle of SAX: SAX will scan the document sequentially, and notify the event processing method when the start and end of the document, the start and end of the element, the content of the element (characters), etc. are scanned. Event processing Method to perform corresponding processing, and then continue scanning to guide the document scanning to end. Commonly used SAX interfaces and classes:
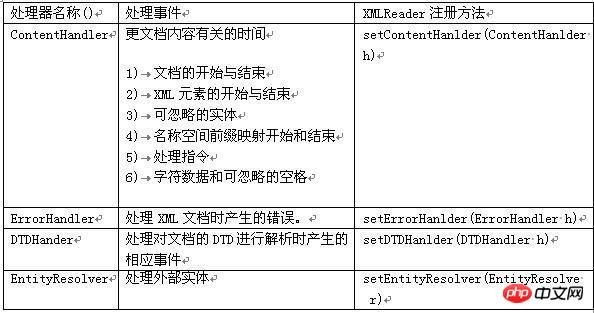
Attrbutes: used to get the number, name and value of attributes.ContentHandler: Defines events associated with the document itself (e.g., opening and closing tags). Most applications register for these events.
DTDHandler: Defines events associated with DTD. It does not define enough events to report the DTD completely. If parsing of the DTD is required, use the optional DeclHandler.
DeclHandler is an extension of SAX. Not all parsers support it.
EntityResolver: Defines events associated with loading entities. Only a few applications register for these events.
ErrorHandler: Define error events. Many applications register these events to report errors in their own way.
DefaultHandler: It provides the default implementation of these interfaces. In most cases, it is easier for an application to extend DefaultHandler and override the relevant methods than to implement an interface directly.
The following is a partial description:
3. Pull analysis
Pull is built into the Android system. It is also the official method used to parse layout files. Pull is somewhat similar to SAX, and both provide similar events, such as start elements and end elements. The difference is that the event driver of SAX is to call back the corresponding method. You need to provide the callback method, and then automatically call the corresponding method inside SAX. The Pull parser is not required to provide a triggering method. Because the event he triggered is not a method, but a number. It is easy to use and efficient. Android officially recommends developers to use Pull parsing technology. Pull parsing technology is an open source technology developed by a third party, and it can also be applied to JavaSE development. Theconstants returned by pull:
Read the declaration of xml and return START_DOCUMENT;How pull works: pull provides a start element and an end element. When an element starts, we can call parser. Commonly used XML pull interfaces and classes:
Exception: Throws a single XML pull parser related error.
Pull parsing process: start_document --> end_document --> start_tag -->end_tagThere is a fourth way in Android: android.util.Xml class (I have not used it)
In the Android API, Android. util. The Xml class can also parse XML files. The usage method is similar to SAX. You also need to write a Handler to handle XML parsing, but it is simpler to use than SAX, as shown below: With android. util. XML implements XML parsing: MyHandler myHandler=new MyHandler0; android. util. Xm1. parse(url.openC0nnection().getlnputStream(), Xml.Encoding.UTF-8, myHandler);3. Practice
1. First create a reference xml document (place it in the assets directory)
Lingqu Canal is located in Xing'an County, Guangxi Zhuang Autonomous Region. It is one of the oldest canals in the world and has the reputation of "the Pearl of Ancient Water Conservancy Architecture in the World". In ancient times, Lingqu was known as Qin Zhuoqu, Lingqu, Douhe and Xing'an Canal. It was built and opened to navigation in 214 BC. It is still functioning 2217 years ago.
jpg
& lt; INTRODUCTION & GT;
## north of Sanshan Island, flowing through Jiaoan, Jiaozhou, Pingdu, Gao Mi, Changyi, Laizhou, etc. , with a basin area of 5,400 square kilometers, runs through the Shandong Peninsula from north to south, and connects the Yellow and Bohai Seas. The Jiaolai Canal divides from the north to south at the watershed east of Pingdu Yaojia Village. The south flow flows from Mawankou into Jiaozhou Bay and is called Nanjiolai River, 30 kilometers long. The north current flows from Haicangkou into Laizhou Bay and is the Beijiaolai River, more than 100 kilometers long.8244d3c.jpg
## is located in the northern part of Jiangsu Province in the lower reaches of the Huaihe River. ), a large artificial river channel that reaches the sea from Biandang Port in the east. The total length is 168km.
## & lt; INTRODUCTION & GT;9aa8fdb7b8322e08244d3c.jpg
We need to use a River object to save data to facilitate observation of node information and abstract the River class
publicclass
River {String
name;// nameInteger
length;// length
String introduction;// introductionString Imageurl ;//
Pictureurl
public String getName() {
return
name;}public void setName(String name) {
this.name = name;
public void setLength(Integer length) {}public String getIntroduction() {
return introduction;}public void setIntroduction(String introduction) {
this.introduction = introduction;} return Imageurl;}public void setImageurl(String imageurl) {Imageurl = imageurl;}@Overridepublic String toString() {return "River [name=" + name + ", length=" + length + ", introduction="+ introduction + ", Imageurl=" + Imageurl + "]";}}The specific processing steps when using DOM parsing are:
1 First use DocumentBuilderFactory to create a DocumentBuilderFactory instance
2 Then use DocumentBuilderFactory to create DocumentBuilder
3 and then load the XML document (Document),
4 Then get the root node (Element) of the document,
5 Then get the root node The list of all child nodes (NodeList),
6 and then use it to get the node that needs to be read in the child node list.
Next we start to read the xml document object and add it to the List:
The code is as follows: Here we use river.xml in assets file, then you need to read this xml file and return the input stream. The reading method is: inputStream=this.context.getResources().getAssets().open(fileName); The parameter is the xml file path, of course the default is assets The directory is the root directory.
Then you can use the parse method of the DocumentBuilder object to parse the input stream and return the document object, and then traverse the node attributes of the document object.
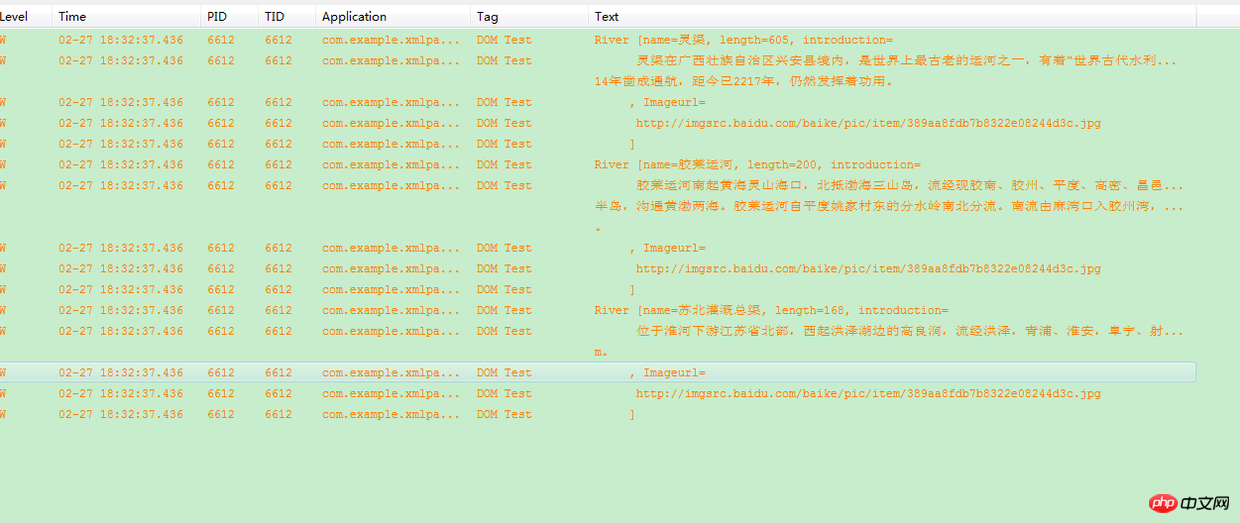
##/*** DOM parsing xml method * @param filePath * @return */ private ListDOMfromXML(String filePath) {Add them to the List here, and then we use log to print them out. As shown in the figure:ArrayListlist = new ArrayList();
DocumentBuilderFactory factory =null;
DocumentBuilder builder = null;Document document = null ;InputStream inputStream = null;//Build the parserfactory = DocumentBuilderFactory.newInstance();try {builder = factory.newDocumentBuilder();//Find the xml file and load itinputStream = this.getResources().getAssets().open(filePath);//Default after getAssets The root directory is assetsdocument = builder.parse(inputStream);//Find the root ElementElement root=document.getDocumentElement();NodeList nodes=root.getElementsByTagName(RIVER);
//Traverse all child nodes of the root node, all rivers under riversRiver river = null;for (int i = 0; i < nodes.getLength(); i++) {river = new River();//Get river element node
Element riverElement = (Element) nodes.item(i);//Set the name and length attribute values in riverriver.setName(riverElement.getAttribute("name") );river.setLength(Integer.parseInt(riverElement.getAttribute("length")));//Get sub-tagsElement introduction = (Element) riverElement.getElementsByTagName(INTRODUCTION).item(0);Element imageurl = (Element) riverElement.getElementsByTagName(IMAGEURL).item(0);//Set the introduction and imageurl attributesriver.setIntroduction(introduction.getFirstChild().getNodeValue());river.setImageurl(imageurl.getFirstChild().getNodeValue());list.add (river);}} catch (ParserConfigurationException e) {// TODO Auto-generated catch blocke.
print StackTrace();
} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();} catch (SAXException e) {// TODO Auto-generated catch blocke.printStackTrace();}for ( River river : list) {Log.w("DOM Test", river.toString());}return list; }
##XML parsing resultis parsed using SAX The specific processing steps are:
1 Create a SAXParserFactory object2 Return a SAXParser parser according to the SAXParserFactory.newSAXParser() method
3 According to SAXParser The parser obtains the event source object XMLReader
4 Instantiates a DefaultHandler object
5 Connects the event source object XMLReader to the event processing class DefaultHandler
6 Calls the parse method of XMLReader from The xml data obtained from the input source
7 returns the
data setcombination we need through DefaultHandler. The code is as follows:
##/**
* SAX parsing xml * @param filePath * @return */ private ListSAXfromXML(String filePath) { ArrayListlist = new ArrayList();//Build the parser
SAXParserFactory factory = SAXParserFactory.newInstance();SAXParser parser = null;XMLReader xReader = null;try {parser = factory.newSAXParser();//Get the data sourcexReader = parser.getXMLReader();//Set the processorRiverHandler handler = new RiverHandler();xReader.setContentHandler(handler); //Parse the xml filexReader.parse(new InputSource(this.getAssets().open(filePath)));list = handler.getList();} catch (ParserConfigurationException e) {e.printStackTrace();
} catch (SAXException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
for (River river : list) {
Log.w("DOM Test", river.toString());
}
return list;
}
The above is the detailed content of XML parsing in Android. For more information, please follow other related articles on the PHP Chinese website!
 What software is zoom?
What software is zoom?
 MySQL index
MySQL index
 Why is there no signal on the monitor after turning on the computer?
Why is there no signal on the monitor after turning on the computer?
 The role of base tag
The role of base tag
 Introduction to hard disk interface types
Introduction to hard disk interface types
 How to use googlevoice
How to use googlevoice
 The difference between JD.com's self-operated flagship store and its official flagship store
The difference between JD.com's self-operated flagship store and its official flagship store
 What does Matcha Exchange do?
What does Matcha Exchange do?








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



