
 headlines
h5 in-depth optimization practical case: How to optimize and evolve the architecture of mobile QQ Hybrid?
headlines
h5 in-depth optimization practical case: How to optimize and evolve the architecture of mobile QQ Hybrid?
h5 in-depth optimization practical case: How to optimize and evolve the architecture of mobile QQ Hybrid?

h5 Deep Optimization Practical Case: How to optimize and evolve the architecture of mobile QQ Hybrid? Original title: More than 70% of the business is developed by H5. How to optimize and evolve the architecture of mobile QQ Hybrid?
With the rise of front-end development, QQ has gradually evolved into a development model that mixes Web and native terminals. While gaining the dynamic operation capabilities of the Web, QQ also faced more challenges in terms of interactive response speed, background service pressure, and bandwidth impact from a massive user set. Under the rapid pace of Web operations, it is necessary to ensure that third-party services embedded in QQ are always in a high-quality service state. In response to these problems, the QQ team not only uses full-stack methods such as dynamic CDN and background rendering to optimize the experience, but also builds a monitoring system focusing on speed, success rate, page exceptions and other dimensions to ensure service quality.
Write it in front
First of all, introduce myself. My name is Tu Qiang. I joined Tencent in 2005. At that time, mobile and hybrid development were not yet popular. I was mainly developing the PC version of QQ. Later, when I was responsible for the PC version of the QQ UI engine, I made some attempts to integrate the browser kernel on the PC client. At that time, I made some frameworks for mixed development of H5 and native. ##Sex work. After that, I joined the Tencent QQ membership team and was responsible for the technology of QQ members on mobile terminals. At the same time, I also had a very arduous task: maintaining all H5 hybrid development frameworks in mobile QQ, that is, the technical work of the WebView component.
Getting back to the subject, the current mainstream hybrid is still H5 + native. The importance of H5 development to current mobile terminals need not be mentioned, but everyone can see the obvious problems of H5 in native, such as when opening the application. The page that has been waiting for a long time to load is likely to be lost when the user sees the chrysanthemum interface during loading. This is also a situation that the product manager does not want to see. Another point is that every time you open H5, it involves network interaction andfile download. These operations will consume the user's traffic. If the traffic consumption is large, the user will be unhappy.
The content I will share with you today mainly introduces how the QQ membership team has optimized the page opening time and user traffic, corresponding to the two independent technical frameworks of sonic and reshape.Separation of dynamic and static pages in traditional pages
All technology selections and frameworks must be selected based on the business form. You may have simple questions about the business form of QQ members. learn. It can be said that more than 70% of the business in mobile QQ is developed by H5, such as the main mall for members: game distribution center, member privilege center and the personalized business mall that I am currently responsible for, etc. The characteristics of these malls are obvious. They are not pages generated by UGC. They are content configured by the product manager in the background, such as the emoticons and themes that can be seen on the page. These pages are relatively traditional. In the beginning, a traditional H5 page will do some optimization to separate dynamic and static in order to improve speed and experience, such as the banner at the top of the page and the item area below which we call item. The data in the area can be freely edited and changed by the product manager at any time. We will initiate a CGI request after loading the page, obtain the data from the dataServer, and then splice it together.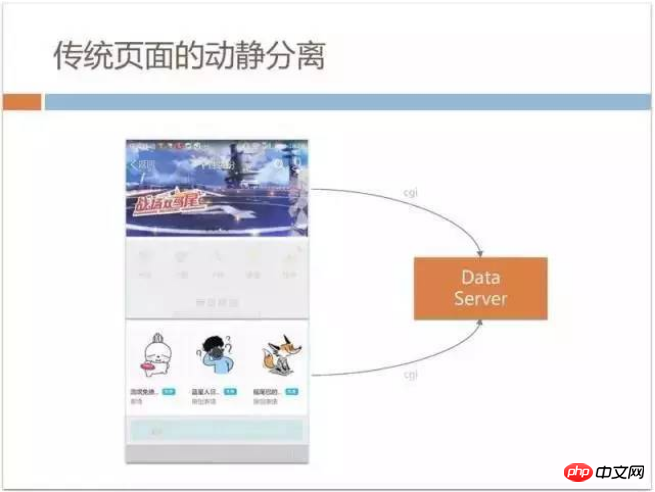
JSON, in order to speed up this process, localStroage may be used for caching. This whole process is a very traditional static page loading process, which is relatively simple.
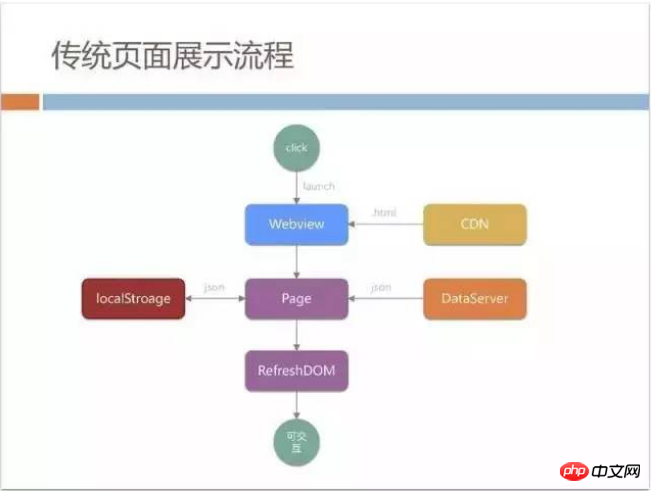
Android machine (because mobile QQ has a multi-process architecture, and WebView lives in another process. Launching WebView once is in addition to process loading. There is also the loading of the browser kernel).
Secondly, static pages published on CDN do not contain item data, so when users first see the page downloaded from CDN, the banner area and item area are blank, which is also detrimental to user experience. A lot of damage. There is another problem. When loading the page, you need to refresh the current DOM, that is, pull the JSON and then splice the DOM structure and then refresh. We found that in the low-end Android machines used by some QQ users, this execution will also Very time consuming.
Static direct out + offline pre-push
Faced with these problems, we boldly adopted some technical means, which we call the static direct out + offline pre-push model. First of all, we parallelized the loading of WebView and network requests. All our network requests were not initiated from the WebView core, but during the process of loading WebView, we established our own HTTP links through native channels, and then from CDN and us The page is obtained from a place called offlineServer. This offlineServer is also the offline package caching strategy that everyone has heard of.
We will have offlineCache in native. When initiating an HTTP request, we first check whether there is a current HTML cache in the offlineCache. This cache is isolated from the WebView cache and will not be affected by the WebView. The impact of caching policies is completely under our control.
If there is no cache in offlineCache, it will go to offlineServer to synchronize files, and it will also download updates from CDN. The HTML we store on the CDN has already typed all the data such as banner and item into the static page. At this time, as long as the WebView gets the HTML, it does not need to refresh or execute any JS. The entire page can be displayed directly, and the user can to interact.
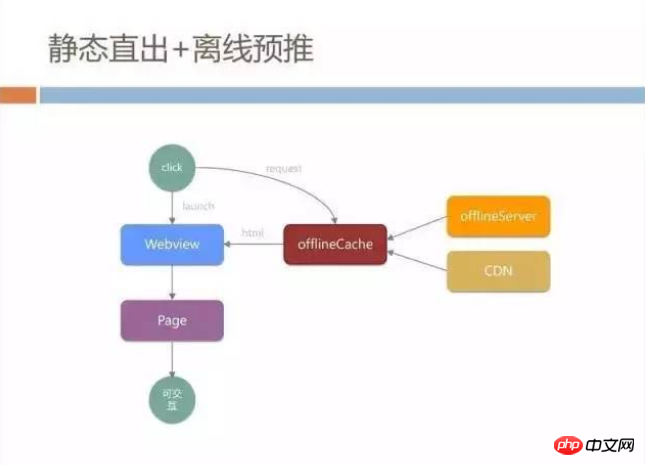
This solution will first save the time of WebView launch. During this time, it can be directly transmitted over the network. In addition, if there is a local offlineCache, there is no need for a network transmission request, which is equivalent to a complete load. A local page. But many times, just to be on the safe side, we add page loading and then perform refresh operations to prevent data inconsistency.
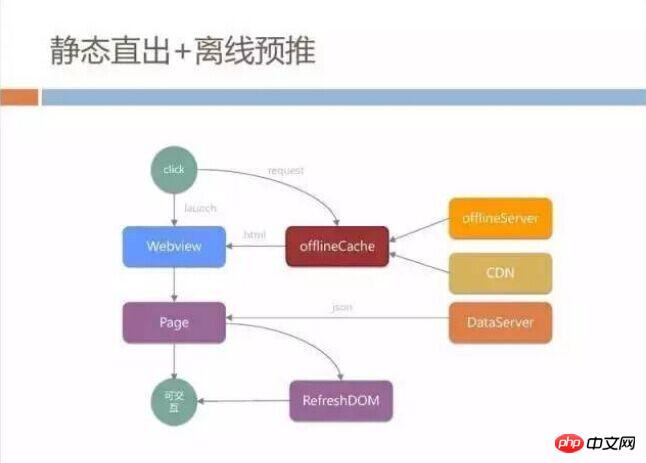
This mechanism works well after it goes online, but if you really implement this H5 loading mode, you will encounter some pitfalls, such as the banner picture# configured by the product manager. ##Slice and item data may have multiple data versions that are inconsistent.
The product manager must configure the latest data information on the dataServer, but the data built into the page on the CDN may still be in the previous version. What is even worse is that the HTML generated by the offline package server and offlineServer is another version. a version. A common cache refresh problem occurs when the user's local cache and server are not synchronized, and it is very likely that the stored data is another copy.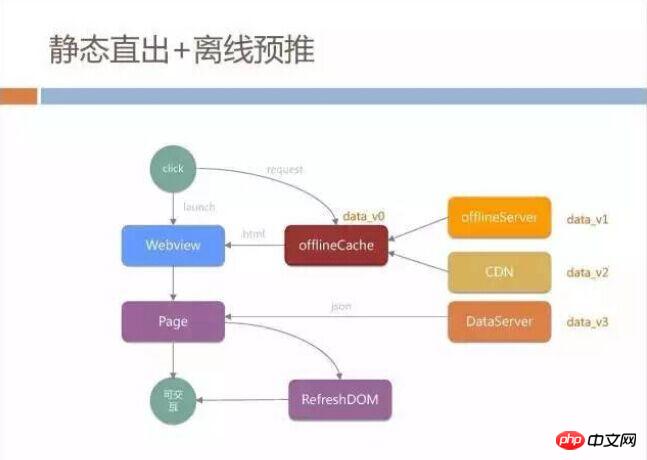
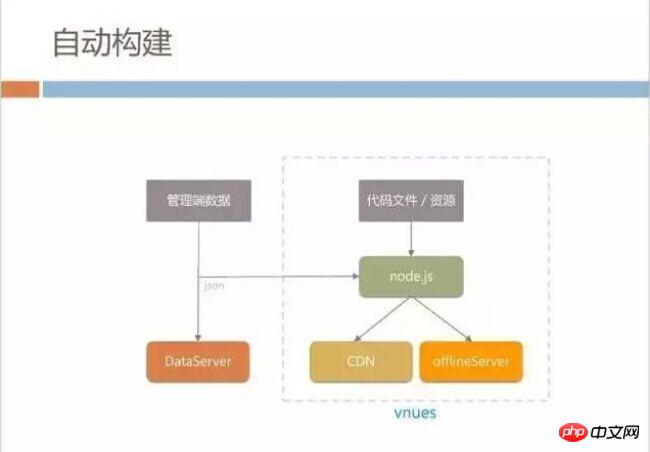
How to unify data
How to quickly unify all four versions of data? We have built a small automatic build system for the static direct-out mode. When the product manager configures data on the management side to synchronize the dataServer, we will immediately start our internal build system called vnues. This system is built based onNode.js. It will generate the latest version of HTML in real time from the code files and UI materials pictures and other data written by the development. , and then publish it to CDN and synchronize it to offlineServer, which can solve the problem of inconsistency between CDN files and the latest data.
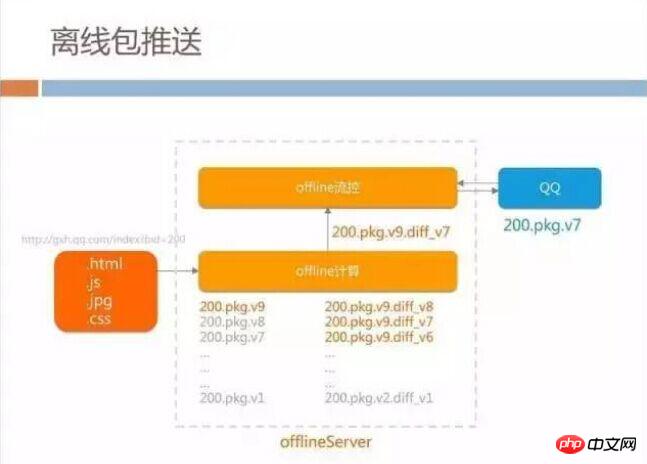
if based on the historical version and the latest version. f, that is, the difference part of each offline package.
This plan is also based on our business form, because the page data updated by the product manager each time is not too much, basically in the range of a few KB to 10+KB, so we do not need to go offline every time Package updates require users to download the full package.When a QQ user logs in , the offline flow control server will be asked every time to see if there is the latest package that can be downloaded. If the bandwidth statistics of the current flow control server are at an acceptable cost (currently tentatively set to 10GB to 20GB of space), when the bandwidth of the CDN can be sustained, the latest diff will be sent to the client, so that when the offline package is updated, the client can be refreshed at the minimum traffic cost.
Data and effects
Through this system, we only spent more than ten GB of bandwidth to own the entire BG The offline package coverage rate of H5 business remains at about 80% to 90%. From this work, we also discovered a very unconventional thing, that is, everyone thinks that offline packet pre-pushing will consume a lot of bandwidth, but in fact, only occasional pre-pushing consumes a lot of bandwidth; if it is pushed continuously for many years, it actually consumes a lot of bandwidth. Very small, because it is maintained in a state of differential distribution all the time.
After doing this work, we collected the live network data. The contrast between the two modes of static direct export and traditional page is very obvious. The time-consuming part of the page in the figure below, because the static direct-out page does not require any JS execution and only requires WebView rendering, the page static direct-out time is reduced by about 500 milliseconds to about 1 second compared with the traditional page.
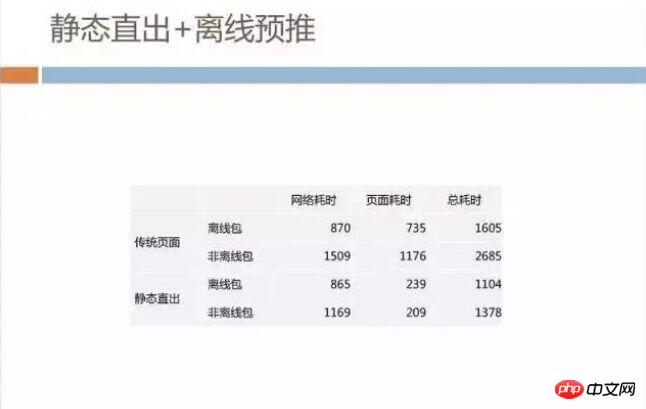
The interesting phenomenon here is the cost-effectiveness of offline packages. It can be seen that using offline packages on traditional pages can save more than 700 milliseconds in the network time-consuming part, but statically out of this Using offline packages in this mode can only save about 300 milliseconds. This is because the external CSS and JS that static export depends on during the network process have been exported to the inside of HTML, and no additional network is required. request, so the network time itself is reduced. At this time, the benefits of using offline packages begin to gradually decline.
There may be questions here, why does the static direct outgoing network time take more than 800 milliseconds in the case of offline packets? Shouldn't it be zero time if there is a local cache?
The network time we estimate is the time from the start of the WebView load URL to the first line of the page, which actually includes the loading of a paging page, the startup of the WebView kernel, network components and rendering The loading of components is relatively time-consuming.
There is definitely room for optimization here, but when our client team was about to optimize the network time-consuming part, our business shape changed. In the past, the product manager would display whatever page he configured, and all users would see the same content. Now, the product manager says that each user should see completely different content when they enter the homepage of the mall.
The following picture is an example. The content on the homepage on the left is randomly recommended. On the right, the behaviorhabits are actually calculated and matched with the items in our backend through machine learning based on the user’s past expressions. , content recommended based on user preferences and behavior.
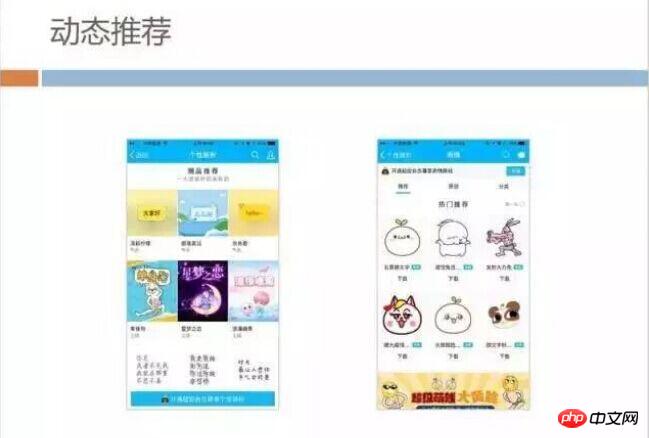
The content that each user sees when they come in is different, so the static straight-out model will not work because we cannot put all users’ pages in It is generated in the background and then sent to CDN. However, there is a very simple way to solve this model.
Dynamic direct output
We do not store HTML on CDN, but dynamically splice out the entire HTML file on the background Node.js server. The data source is from dataServer Pull.
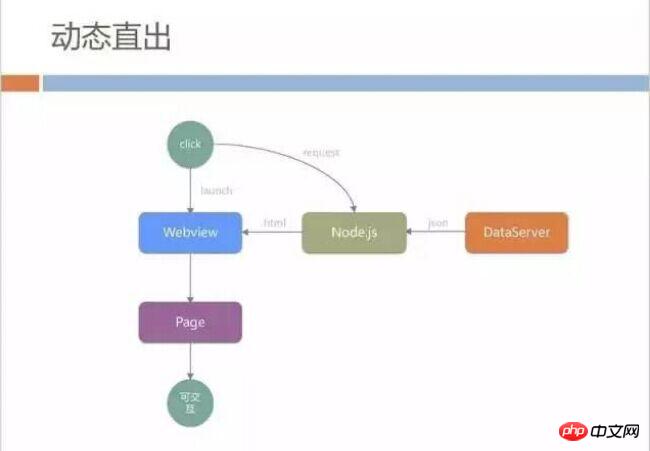
This model solves the needs of the product, but introduces new problems. WebView needs to request Node.js to obtain html, and Node.js needs to assemble background pages. The intermediate network time and background calculation time are larger than we imagined. During this process, the entire page cannot be rendered. When users enter the homepage of our mall, they see a blank page. The product manager also cannot accept it, and users do not pay for it.
In addition, in this mode, it is almost impossible to use the cache of WebView itself, because the background direct outgoing CSS/JS has all been executed on the backend, and it is difficult for WebView to cache all pure static HTML. In order to solve the above problems, we introduced a dynamic caching mechanism.
Dynamic Cache
Similarly, we do not let WebView directly access our Node.js server. We add the previously mentioned middle layer sonicBridge similar to offlineCache. , this middle layer will first download the complete HTML from the Node.js server to the WebView, and at the same time cache the downloaded content locally.
We used to cache the same HTML for all users on the entire network, but now we have corrected it so that the content cached for all users on the entire network is pages pulled back from the real server.
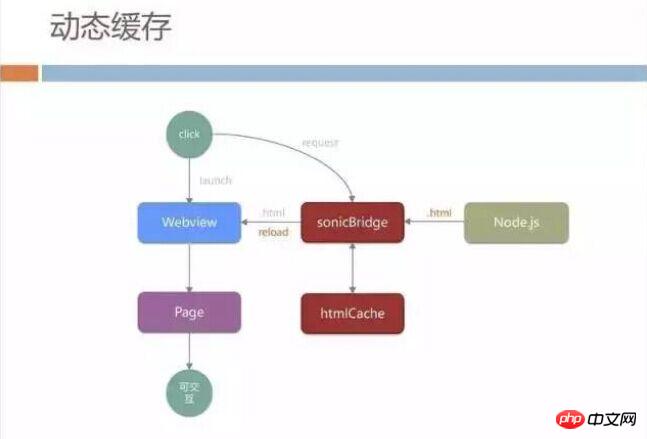
When the user enters the page for the second time, sonicBridge will give priority to submitting the locally cached page to WebView. When the user enters the page, he can see the content without waiting for the network request. This is good for the user. The experience improvement in terms of speed is relatively large, but it introduces another problem.
In fact, the content that users see is different every time they open WebView. The data returned by Node.js is the latest every time. Therefore, we must let WebView reload the data pulled back, which gives the user The experience is: I have obviously opened the locally cached HTML and saw the content, but the entire page is reloaded as soon as I operate it. WebView reload is very time-consuming on some low-end models. Users can clearly feel that the entire WebView H5 page goes blank for a while, and then the new content is refreshed.
Combined with the previously mentioned experience of static direct refresh of the partial DOM, we can reduce the amount of network transmission and the amount of data submitted to the page. The first thing we do is to reduce the amount of network transmission and avoid refreshing too late.
Reduce transmitted data
We changed the protocol of Node.js group HTML. When sonicBridge requests data for the second time, the Node.js server will not The entire HTML is returned to sonicBridge, but instead the part we call data is returned.
After getting the data data, we made an agreement with the H5 page, and the native side calls the fixed refresh function of the page and passes the data to the page. The page will partially refresh its own DOM node, so that even if the page needs to be refreshed, the entire page will not be reloaded.
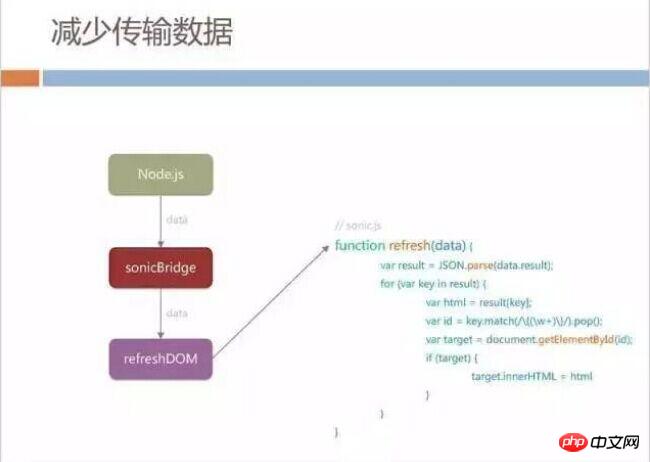
Specifically from the data content process, the first sonicBridge loading page still returns complete HTML, and at the same time, the id we call template-tag is returned. This template -tag will mark the static and unchanged part of the hash value in this page. This measure is to control caching. We will also have some tags in the returned HTML, such as sonicdiff-banner. This banner determines its refresh id.
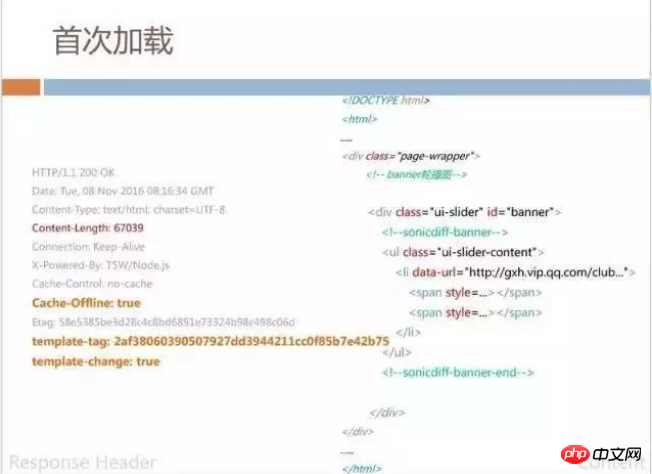
When loading for the second time, the data returned does not have the entire HTML seen earlier, and only about 37KB of data will be returned. This data is actually a JSON, but it Defines the DOM structure corresponding to the previous example sonicdiff-banner. In order to save the code executed in H5, we directly spell out the DOM node code in JSON, so that the page only needs to do id matching and refreshing.

It is difficult to avoid the 37KB transmission data here. We have observed that the amount of refresh data is different for different businesses. Can we reduce the amount of data submitted to the page for refresh? After all, the product manager does not modify a lot of data each time.
Reduce the submission of page data
In addition to the previously mentioned, we will cache the complete HTML and template at the sonicCache layer, and also extract the data for dataCache .
When the template is accessed for the first time, all variable data is removed from the remaining page frame based on the id information in sonicdiff. When the user opens it for the second time, he only needs to merge the returned data with the template locally on the client to get the complete HTML.
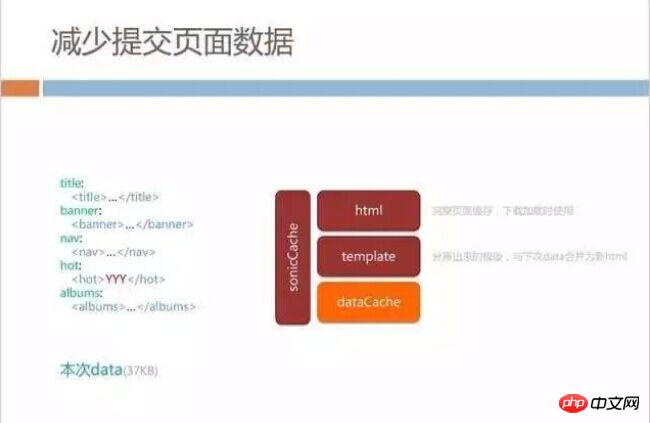
After we cache each dataCache, we also make a difference in the data. For example, this time the request returns 37KB of data, and the last cached data was also 37KB. of data, we will determine how much internal changes have actually occurred, and then only give the difference to HTML refresh. In most scenarios, our page only needs to process about 9KB of data to refresh the entire page.

With the cache, the user can open it locally very quickly. The transmission of differential data also reduces the time the user waits for refresh. Finally, this kind of data submission is added The time-consuming diff greatly reduces the page refresh range.
The entire sonic mode process is as follows. It looks complicated, but the basic principle is to cache the HTML template and data requested back through Bridge.
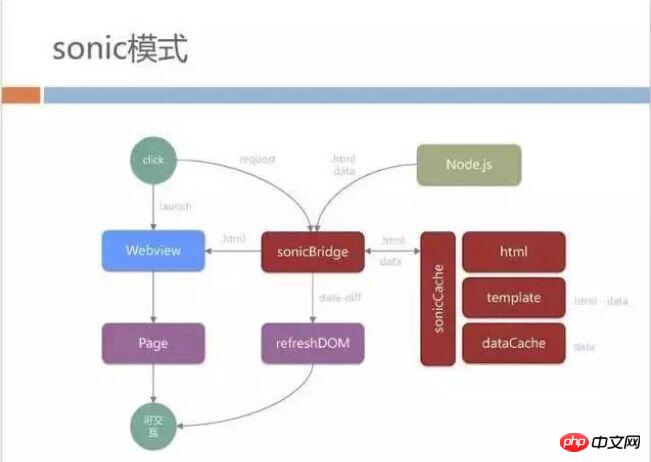
There may be questions here. Are the offlineServer and offline pre-push strategies that I spent a lot of effort on statically exporting in the past still useful here? In fact, we still use the offline caching mechanism for dynamic pages and static pages mentioned before, because our business pages also have a lot of public JS, such as the JS API package provided by QQ, and some shared CSS as well. Pre-pushed through the offline package strategy, this is also what everyone will download every time they log in.
Data and effects
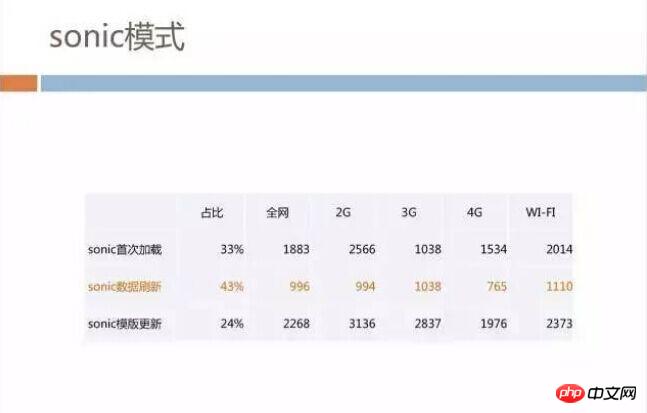
After completing this mode, the data effect is relatively obvious. The performance of the first load and the ordinary HTTP load are similar, but the user opens the page for the second time At this time, it usually only takes 1 second to see the page. This 1 second also includes the overhead of the client launch process and WebView. At the same time, our loading speed is no longer affected by the user's network environment, whether it is 2G or 4G loading speed. All close to the same.
And it also brings a benefit. If the user's network is relatively poor, such as frequent jitters and unable to connect, because we have a local cache, our page can be opened even if the user is currently disconnected.
There is no template update scenario mentioned here. Template update means that the template we extract may change dynamically in our server. The loading process at this time is different from what we mentioned earlier. , when the template changes, still follow the original process of HTML reload page. The time consumption here is relatively high, but our statistics show that most users still fall into the state of data refresh, that is, the second opening.
Whether to use persistent connections
When doing H5 speed-up optimization, it is easy for everyone to think about whether we should use persistent connections to Avoid time-consuming access to the server's connect, DNS, handshakes, etc. Clients like QQ have a persistent connection with the backend server. If you use this connection to request an HTML file from the backend server and hand it over to WebView, will it be faster than temporarily establishing a connect request? We only need to set up a reverse proxy service to access our Node.js server from the QQ messaging backend. This process can be solved, but we evaluate that this model may not be suitable for all scenarios.
There are indeed some apps that use the persistent connection channel to load pages, but it is difficult to do this on mobile QQ because the persistent connection channel between the mobile QQ client and the server is a very traditional CS architecture. It sends a socket package. Each time it needs to send a request package, it will continue to the next request after receiving the response.
This response mechanism determines that it requires a waiting process every time, and the constraintsof the socket package cause the size of each transmitted data packet to be limited, like our 30+ The KB data is likely to be split into five or six data packets. Although the persistent connection is used to save the connection time, multiple back-and-forth communications with the server increase the overall time consumption.
In addition, the data returned from the Node.js server is HTTP streaming. WebView does not need to wait for the entire HTML to be loaded before it can be rendered and displayed. It can start as long as it gets the first byte in the transmission# The parsing of ##document and the construction of DOM.
If we want to use persistent connections, we are likely to have to go through steps such as encryption, decryption and packaging on the client side, and we will have to wait until the entire HTML download is completed before it can be displayed. We think this time will slow down the performance.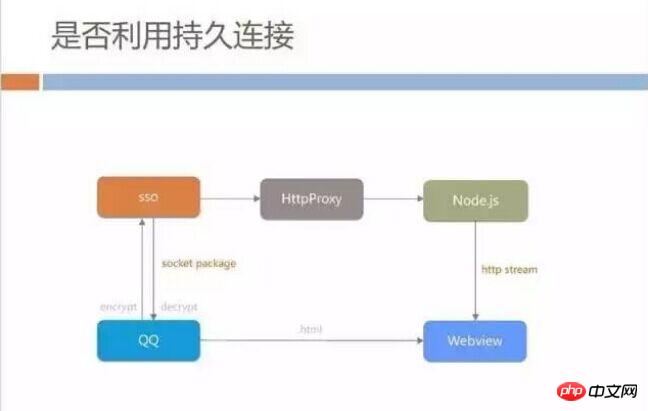
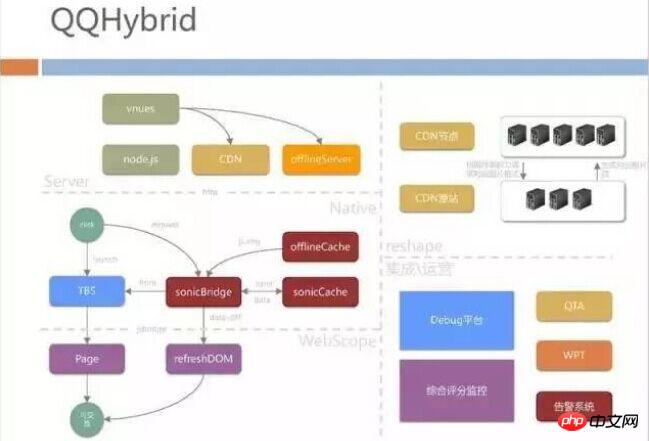
QQHybrid Architecture
After the above introduction, you may have a rough and intuitive impression of QQHybrid: 1. We are The front-end development students of WebScope did part of the work; 2. Our native layer terminal development students did the bridge bridging, and 3. Our back-end students did a lot of automatic integration and offlineServer push. The structure of this part is as follows: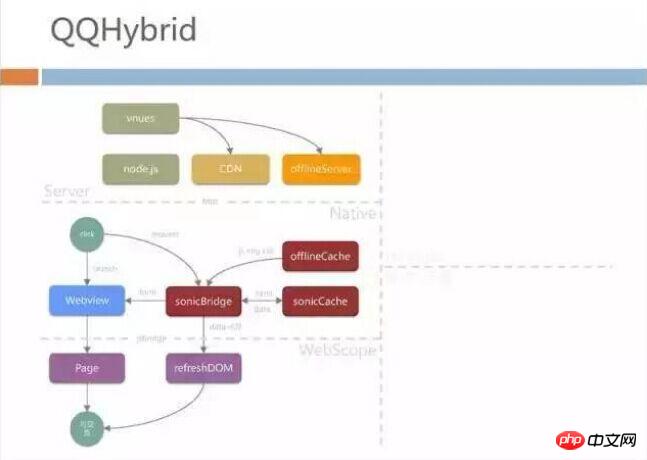
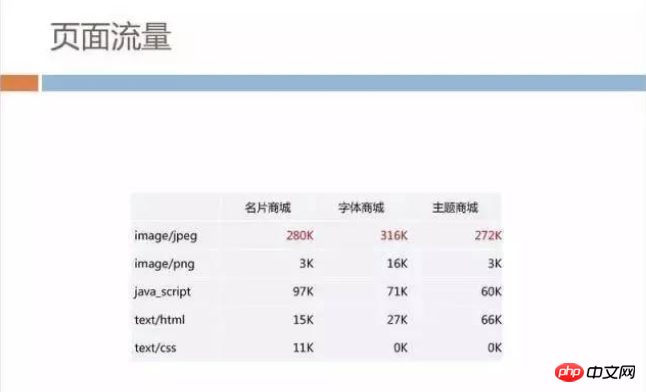
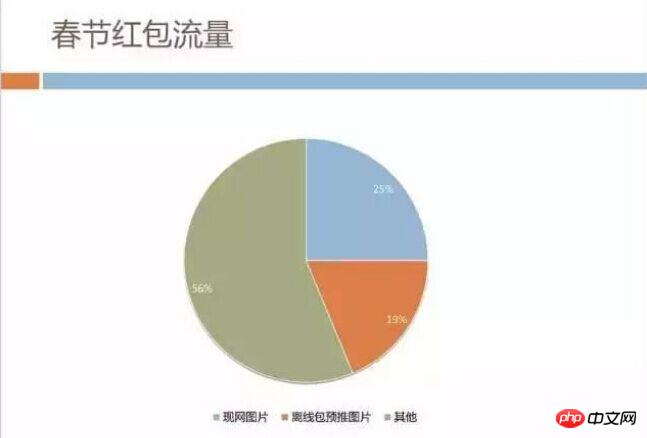
Traffic Analysis of Spring Festival Red Envelopes
We happened to have an opportunity. During the 2016 Spring Festival, Mobile QQ held an event that almost all businesses participated in - Spring Festival Red Envelopes. You may still remember the operation of constantly tapping the screen to receive red envelopes during the Spring Festival evening in 2016. This kind of national carnival has brought huge traffic pressure. About 300,000 gift packages are issued to users every second, and the web traffic that guides users is about hundreds of thousands of H5 page openings per second. It was estimated at that time Traffic peaks exceed 1TB.
We analyzed the image traffic and found that it indeed accounts for nearly half. For some of it, we have used offline package pre-push to deliver it to users’ mobile phones in advance. However, during the event, the images on the network were The traffic is still over 200GB.
Traffic is not a problem that can be solved by simply paying money to the operator. During the Spring Festival activities, we almost encountered a situation where the traffic under a single domain name was close to 200GB. At that time, the CDN architecture could no longer bear it.
#We all think there is great potential here. If image traffic can be saved, bandwidth costs can be reduced. The network traffic and mobile phone battery consumption on the user side can be better, so our team checked new things about image formats.
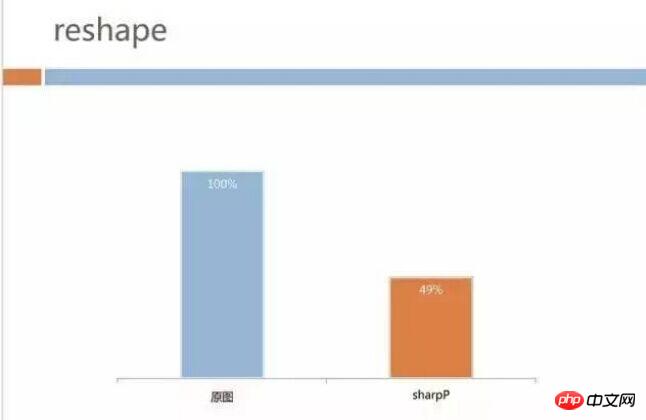
SharpP application
Everyone is familiar with WebP, and Android supports it relatively well. The QQ team has internally developed an image format called SharpP. The file size can be saved by about 10% compared to WebP. The following is a comparison of data extracted from existing images on our CDN server.
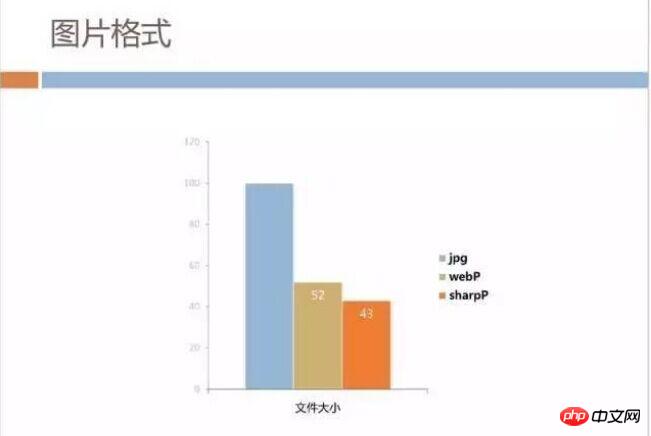
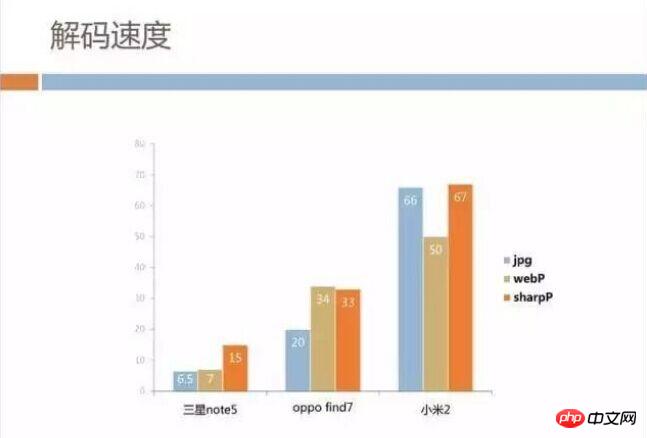
Picture size is dominant, but what about decoding speed? We used high-end, mid-range, and low-end models respectively for analysis. Unfortunately, SharpP is indeed a little slower than WebP or even JPG. But fortunately, the image size of our business is not too large. It costs dozens of dollars more on the page. Milliseconds are also acceptable, and we think this is more advantageous than saving time waiting for the network.
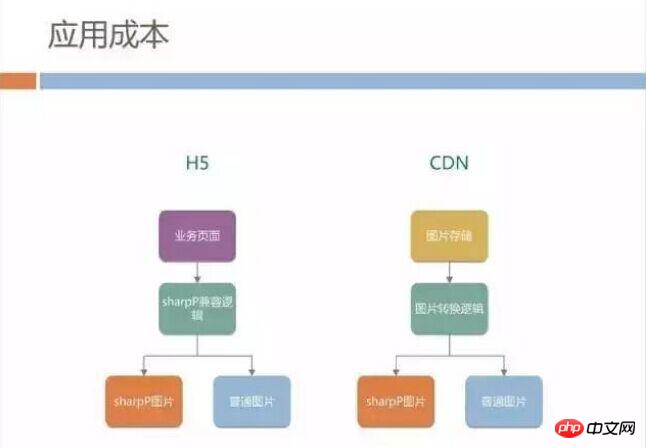
So we are planning to promote the SharpP format in the mobile QQ H5 business, but promoting the new image format will bring huge application costs. First of all, most of the image links are hard-coded, and the page does not know whether the mobile terminal has the ability to decode the SharpP format.
Does the H5 page need to prepare different HTML for different mobile QQ versions? Or when image resources are published to CDN, two links in different formats are generated, and then different links are selected based on the terminal version within H5? This development cost is certainly unacceptable.
In addition to the problem of image format, we found that different models of users will waste traffic. Our UI design is usually made for the screen size of iPhone6, and the default is 750px picture material. Mobile phones with small screens, such as 640px and 480px, also download 750px images and then reduce them during rendering.
This actually wastes a lot of bandwidth, so we are thinking about whether CDN can deliver images in different formats according to the user's mobile phone screen size.
reshape architecture
This screen adaptation strategy also faces the cost of a nearly private format, because the CDN does not know the situation of the mobile phone. Finally, we proposed the reshape architecture. Judging from the complete process of image downloading, it can be roughly divided into 4 levels:
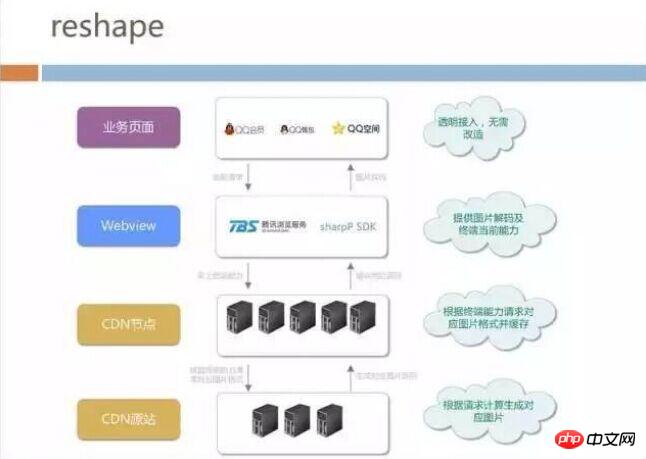
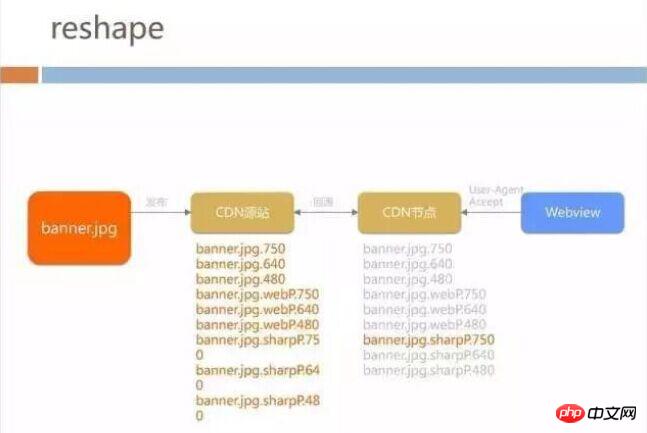
The bottom layer is called CDN source site, here we have deployed an image format conversion tool. The business side does not need to care about JPG production before generating sharpP or WebP. It only needs to publish the image on the CDN source site to automatically convert it to the corresponding format and screen resolution. ;
The top is the CDN node that the user’s mobile phone accesses, and servers are deployed across the country for accelerating and caching files.
We have cooperated with the browser team to put the sharpP decoding format in the browser kernel, so that the top-level business does not need to care whether the current browser supports WebP or sharpP .
When opening the page, WebView will automatically bring the screen size of the terminal and which image formats are supported to the CDN node. The CDN node will then obtain the latest images from the origin site. The origin site will The corresponding image may have been generated offline or in real time.
Disassemble the WebView layer. In addition to integrating the sharpP decoding library, other things are relatively simple, such as:
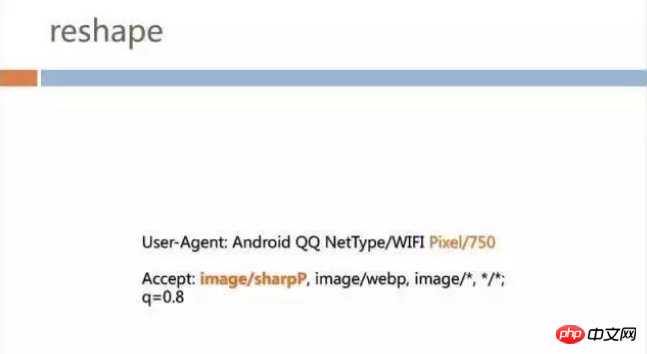
In the request header has added additional fields, for example, "Pixel/750" has been added to User-Agent. If it is a 480px machine, the value will become 480;
Added sharpP protocol header in Accept: image/sharpP
will store 3 in the source site *3 number of pictures. When each business picture is submitted to the source site for publication, 9 pictures will be generated. The CDN node will request the corresponding type of image from the CDN origin site according to the request of WebView, but for the business and WebView, the request is still the same link, so that all H5 pages of Mobile QQ do not need any line of front end By modifying the code, you can enjoy the size adaptation and traffic savings brought by the image format.
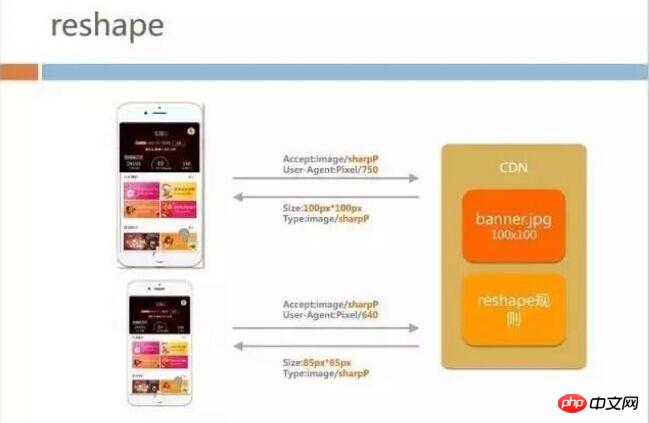
The following is a more vivid process. Add fields in Accept and then return the corresponding picture:
This technology It's not complicated. I personally don't think there is a deep technical threshold. It's more about opening up the entire chain from the client, the Web to the CDN backend. But we also encountered some pitfalls in the process: when we were working in grayscale, we found that many iOS users complained that pictures could not be displayed when the page was displayed.
This surprised us because this technology had not yet been deployed on iOS, only Android. We have checked the CDN code and there is no problem, so why are sharpP images distributed to iOS users?
Later analysis found that operators in different regions of China will provide caching services similar to CDN Cache. When an Android user requests a sharpP image for the first time, the operator's server gets the sharpP format link from our CDN. When other iOS users in the same region make requests during the cache validity period, the operator finds that the URL is the same and directly returns the image in sharpP format to the iOS user.
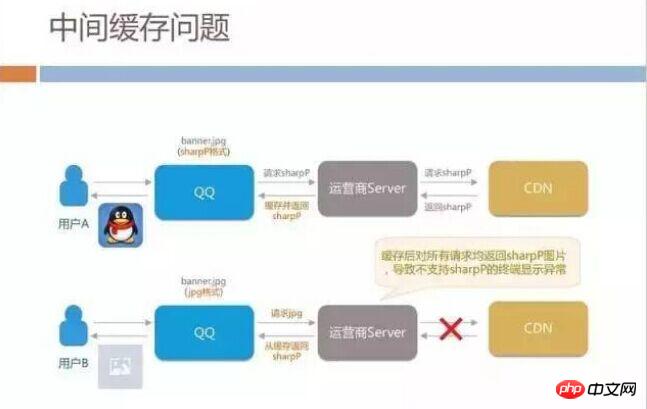
This problem is a pitfall in our overall architecture because we did not conduct a comprehensive review. HTTP has a standard convention that can solve this caching problem. When CDN distributes content, when specifying cache through the Vary field, you need to refer to the fields in Accept and User-Agent. After we add this Vary, the problem is basically solved.

This case gives us additional inspiration. In our current network, the Pixel field has three values: 480px, 640px, and 750px. We have internally discussed whether we can write the screen size directly in the User-Agent, so that when Android comes out with some new screen resolutions, we can also do better adaptation in the background and generate different formats for each model. picture.
If we really do this, it will bring huge back-to-origin overhead to the operator and our own CDN cache. Each resolution image must be cached, for example 498px. If the intermediate operator does not have the cache for this model, it will go to our service to return to the source. In this way, N screen sizes will bring N times the return to our CDN. source pressure.
Data and effects
Getting back to the subject, the final data effect is also relatively obvious. The picture below is our Android grayscale effect data. The image traffic of our H5 business dropped from 40+GB to 20+GB. For Tencent, 20+GB of bandwidth is not a particularly large cost, but in the Spring Festival event scenario, it can nearly double the business space. An additional benefit is that the time users wait to see page images is relatively reduced, and user-side traffic is also saved in half.
Stability of H5 during fast operation
When we solved the problems of page loading speed and traffic consumption, we also started to consider Stability issues of H5 under fast operation. I believe that front-end developers have all encountered situations where once the code of a certain page is changed, other functions will not work properly. When using hybrid development, it is very likely that native will provide many APIs for JS pages. Small changes on the client may cause the JS API to be affected, causing the H5 pages on the entire network to function abnormally.
In addition to functional stability, there is another big problem. We publish front-end pages every day, so how can the optimization performance of the page not be degraded? We finally spent time reducing the page loading performance to 1 second. Will there be some front-end modifications such as introducing more external link JS/CSS dependencies that will degrade the performance of the entire page? We have made some tools to solve these problems.
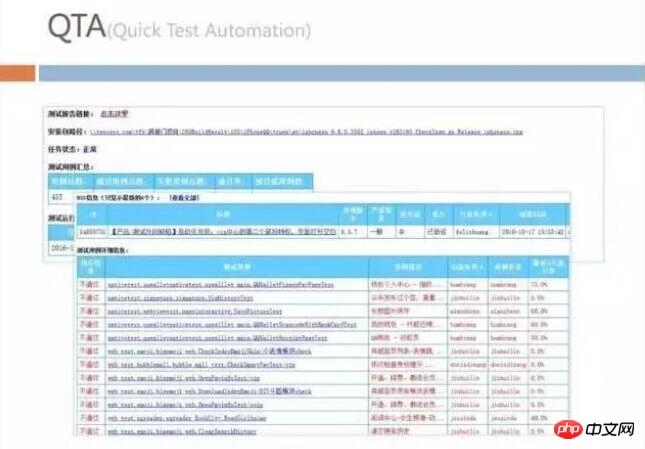
Quick Test Automation
This is what we call quick automation internally. We will write all the test case sets on the front end as automated tests, and then run all the test case sets on all pages on the entire network every day to check whether the functions are normal.
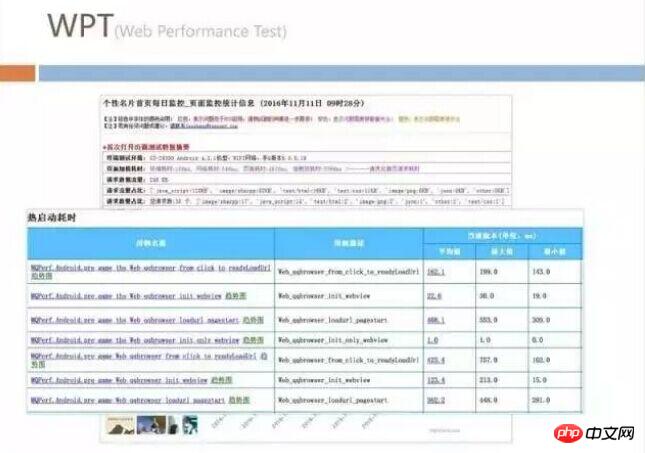
Web Performance Test
We will monitor the performance of the Web through Web Performance Test. The first thing we observe here is every time the page is opened. The traffic consumed, so we will use tools to analyze all the loaded images on the page to see if some of them can be converted to sharpP but still use JPG. With this set of monitoring, H5 developers outside our team can be prompted to optimize their pages.
The front-end often mentions the need to reduce the number of requests during optimization, etc. These can be considered military rules, and we will supervise them during testing. We have not mentioned in detail some methods of client-side optimization before, but we have also done some monitoring of the time it takes to start WebView on the client.
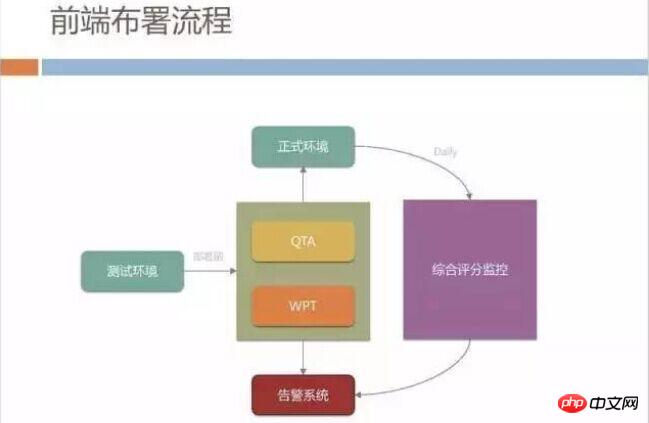
Front-end deployment process
We also have a more strict front-end release process, all written and tested in the test environment Passed code must pass QTA and WPT verification if it is to be released to the formal environment. If the automated test success rate is less than 95%, it will not be allowed to be released.
After being released to the official environment, we also have a comprehensive score monitoring system on the external network. The primary monitoring indicator is speed. We break down the page opening speed into client time-consuming and network time-consuming. and page time consumption and monitor them separately.
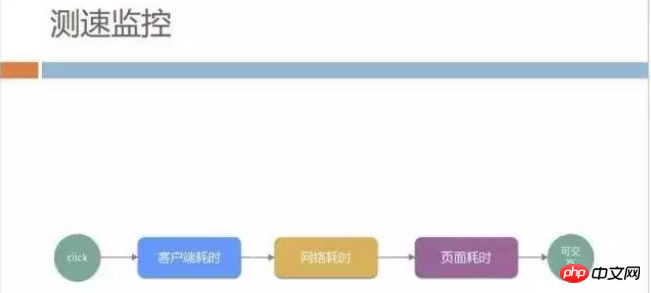
We will output the following monitoring report every day to observe the daily speed changes. Here we are not simply concerned about the performance of the entire network. , we are more concerned about the experience of slow users, such as the recent proportion of users with more than 5 seconds.
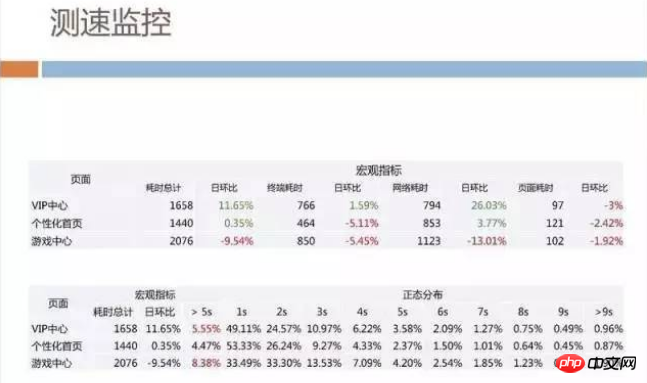
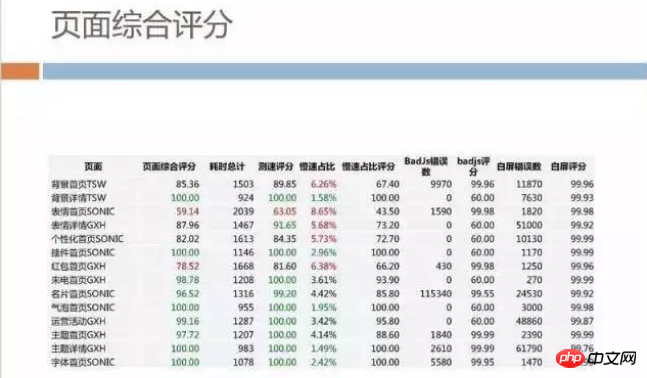
In addition to these, H5 often encounters certain JS errors that cause the page to be abnormal, loading too slowly, causing users to see a white screen for too long, etc. We have systematic monitoring of these.
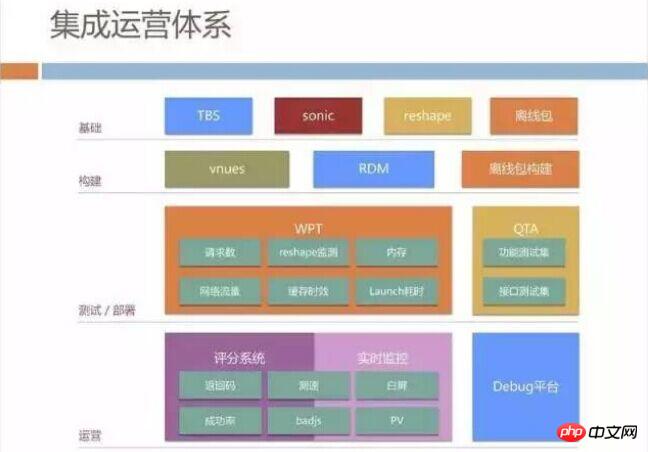
Integrated operation system
In addition to what was mentioned before, we also built a Debug platform, a lot of debugging The capability has been deployed in all mobile QQ terminals in advance. We can use remote commands to check the user's DNS resolution, which server was hit, whether the user was hijacked by the operator, etc.
Written at the end
The entire QQHybrid architecture is basically introduced. In addition to performance optimization, we also optimize the CDN The structure has been adjusted, and operational monitoring tools have also been developed. I think it is the operation monitoring system that allows our entire H5 and hybird teams to boldly modify pages and release new features while ensuring stability and reliability.
The whole process also made us feel that the hybrid architecture is not as everyone understood before. It just works well when the client and front-end work together. In the whole architecture system, the backend Technology also plays a big role. We also asked for the support of the operation and maintenance team for the CDN transformation, and the test and development team also participated in QTA and WPT. It can be said that the establishment of the entire system is the result of all positions working side by side.
Recommended related articles:
php website Practical performance optimization: Taobao homepage loading speed optimization practice
Web front-end learning route: Quick introduction to WEB front-end development

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1390
1390
 52
52

 Sony ZV-E10 II leak: 26 MP compact vlogger camera gets new release date and 2 companion lenses
Jun 29, 2024 pm 03:53 PM
Sony ZV-E10 II leak: 26 MP compact vlogger camera gets new release date and 2 companion lenses
Jun 29, 2024 pm 03:53 PM
The Sony ZV-E10 II has been leaked before as coming in the first half of 2024, and while the initial launch was seemingly set for sometime in May, it was apparently delayed. A new leak shared by prolific leaker Andrea Pizzini, supposedly originating
 In-depth interpretation: Why is Laravel as slow as a snail?
Mar 07, 2024 am 09:54 AM
In-depth interpretation: Why is Laravel as slow as a snail?
Mar 07, 2024 am 09:54 AM
Laravel is a popular PHP development framework, but it is sometimes criticized for being as slow as a snail. What exactly causes Laravel's unsatisfactory speed? This article will provide an in-depth explanation of the reasons why Laravel is as slow as a snail from multiple aspects, and combine it with specific code examples to help readers gain a deeper understanding of this problem. 1. ORM query performance issues In Laravel, ORM (Object Relational Mapping) is a very powerful feature that allows
 Decoding Laravel performance bottlenecks: Optimization techniques fully revealed!
Mar 06, 2024 pm 02:33 PM
Decoding Laravel performance bottlenecks: Optimization techniques fully revealed!
Mar 06, 2024 pm 02:33 PM
Decoding Laravel performance bottlenecks: Optimization techniques fully revealed! Laravel, as a popular PHP framework, provides developers with rich functions and a convenient development experience. However, as the size of the project increases and the number of visits increases, we may face the challenge of performance bottlenecks. This article will delve into Laravel performance optimization techniques to help developers discover and solve potential performance problems. 1. Database query optimization using Eloquent delayed loading When using Eloquent to query the database, avoid
 C++ program optimization: time complexity reduction techniques
Jun 01, 2024 am 11:19 AM
C++ program optimization: time complexity reduction techniques
Jun 01, 2024 am 11:19 AM
Time complexity measures the execution time of an algorithm relative to the size of the input. Tips for reducing the time complexity of C++ programs include: choosing appropriate containers (such as vector, list) to optimize data storage and management. Utilize efficient algorithms such as quick sort to reduce computation time. Eliminate multiple operations to reduce double counting. Use conditional branches to avoid unnecessary calculations. Optimize linear search by using faster algorithms such as binary search.
 Discussion on Golang's gc optimization strategy
Mar 06, 2024 pm 02:39 PM
Discussion on Golang's gc optimization strategy
Mar 06, 2024 pm 02:39 PM
Golang's garbage collection (GC) has always been a hot topic among developers. As a fast programming language, Golang's built-in garbage collector can manage memory very well, but as the size of the program increases, some performance problems sometimes occur. This article will explore Golang’s GC optimization strategies and provide some specific code examples. Garbage collection in Golang Golang's garbage collector is based on concurrent mark-sweep (concurrentmark-s
 Laravel performance bottleneck revealed: optimization solution revealed!
Mar 07, 2024 pm 01:30 PM
Laravel performance bottleneck revealed: optimization solution revealed!
Mar 07, 2024 pm 01:30 PM
Laravel performance bottleneck revealed: optimization solution revealed! With the development of Internet technology, the performance optimization of websites and applications has become increasingly important. As a popular PHP framework, Laravel may face performance bottlenecks during the development process. This article will explore the performance problems that Laravel applications may encounter, and provide some optimization solutions and specific code examples so that developers can better solve these problems. 1. Database query optimization Database query is one of the common performance bottlenecks in Web applications. exist
 How to optimize the startup items of WIN7 system
Mar 26, 2024 pm 06:20 PM
How to optimize the startup items of WIN7 system
Mar 26, 2024 pm 06:20 PM
1. Press the key combination (win key + R) on the desktop to open the run window, then enter [regedit] and press Enter to confirm. 2. After opening the Registry Editor, we click to expand [HKEY_CURRENT_USERSoftwareMicrosoftWindowsCurrentVersionExplorer], and then see if there is a Serialize item in the directory. If not, we can right-click Explorer, create a new item, and name it Serialize. 3. Then click Serialize, then right-click the blank space in the right pane, create a new DWORD (32) bit value, and name it Star
 Fujifilm Instax Mini Evo hybrid instant camera launches as 90th Anniversary Limited Edition
Aug 15, 2024 pm 12:02 PM
Fujifilm Instax Mini Evo hybrid instant camera launches as 90th Anniversary Limited Edition
Aug 15, 2024 pm 12:02 PM
Fujifilm was founded in Tokyo on January 20, 1934, which is why the company is currently celebrating its 90th anniversary. As part of celebrations, Fujifilm is presenting a limited 90th Anniversary Edition of the Instax Mini Evo, which is available i