
Salvatore Sanfilippo, the author of Redis, once compared these two memory-based data storage systems:
Redis supports server-side data operations: Compared with Memcached, Redis has more data structures and supports richer data operations. Usually in Memcached, you need to get the data to the client to make similar modifications and then set it back. . This greatly increases the number of network IOs and data volume. In Redis, these complex operations are usually as efficient as regular GET/SET. Therefore, if you need the cache to support more complex structures and operations, then Redis will be a good choice.
Comparison of memory usage efficiency: If simple key-value storage is used, Memcached has a higher memory utilization. If Redis uses a Detailed explanation of the difference between Redis and Memcached structure for key-value storage, its memory utilization will be higher than Memcached due to its combined compression. .
Performance comparison: Since Redis only uses a single core, while Memcached can use multiple cores, on average, Redis has higher performance than Memcached when storing small data on each core. For data of more than 100k, the performance of Memcached is higher than that of Redis. Although Redis has recently been optimized for the performance of storing big data, it is still slightly inferior to Memcached.
Specifically why the above conclusion appears, the following is the collected information:
Unlike Memcached, which only supports data records with simple key-value structures, Redis supports much richer data types. There are five most commonly used data types: String, Hash, List, Set and Sorted Set. Redis uses a redisObject object internally to represent all keys and values. The most important information of redisObject is shown in the figure:

type represents the specific data type of a value object, and encoding is the way different data types are stored inside redis. For example: type=string represents that value is stored as an ordinary string, and the corresponding encoding can be raw or int. If it is int, it means that the actual string is stored and represented internally by redis according to the numerical class. Of course, the premise is that the string itself can be represented by numerical values, such as: "123" "456" such strings. Only when the virtual memory function of Redis is turned on will the vm field actually allocate memory. This function is turned off by default.
1) String
Commonly used commands: set/get/decr/incr/mget, etc.;
Application scenarios: String is the most commonly used data type, and ordinary key/value storage can be classified into this category;
Implementation method: String is stored in redis as a string by default, which is referenced by redisObject. When encountering incr, decr and other operations, it will be converted into a numerical value for calculation. At this time, the encoding field of redisObject is int.
2) Hash
Commonly used commands: hget/hset/hgetall, etc.
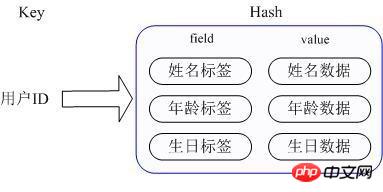
Application scenario: We want to store a user information object data, which includes user ID, user name, age and birthday. Through the user ID we hope to obtain the user's name, age or birthday;
Implementation method: Redis's Hash actually stores the value internally as a HashMap, and provides an interface for direct access to the members of this Map. As shown in the figure, Key is the user ID and value is a Map. The key of this Map is the attribute name of the member, and the value is the attribute value. In this way, data can be modified and accessed directly through the key of its internal Map (the key of the internal Map is called field in Redis), that is, the corresponding attribute data can be manipulated through key (user ID) + field (attribute label). There are currently two ways to implement HashMap: When there are relatively few members of HashMap, Redis will use a one-dimensional array-like method to compactly store it in order to save memory, instead of using the real HashMap structure. At this time, the encoding of the redisObject of the corresponding value is zipmap, when the number of members increases, it will automatically be converted into a real HashMap, and the encoding is ht at this time.
3) List
Commonly used commands: lpush/rpush/lpop/rpop/lrange, etc.;
Application scenarios: There are many application scenarios for Redis list, and it is also one of the most important data structures of Redis. For example, twitter's follow list, fan list, etc. can be implemented using Redis's list structure;
Implementation method: Redis list is implemented as a two-way linked list, which can support reverse search and traversal, making it more convenient to operate. However, it brings some additional memory overhead. Many implementations within Redis, including send buffer queues, etc., are also used. of this data structure.
4)Set
Commonly used commands: sadd/spop/smembers/sunion, etc.;
Application scenarios: The external functions provided by Redis set are similar to those of list. The special feature is that set can automatically eliminate duplicates. When you need to store a list of data and do not want duplicate data to appear, set is a very useful tool. A good choice, and set provides an important interface for determining whether a member is in a set collection, which list cannot provide;
Implementation method: The internal implementation of set is a HashMap whose value is always null. In fact, it is quickly sorted by calculating Detailed explanation of the difference between Redis and Memcached. This is why set can provide a way to determine whether a member is in the set.
5) Sorted Set
Commonly used commands: zadd/zrange/zrem/zcard, etc.;
Application scenarios: The usage scenario of Redis sorted set is similar to that of set. The difference is that set is not automatically ordered, while sorted set can sort members by providing an additional priority (score) parameter by the user, and is inserted in order. That is, automatic sorting. When you need an ordered and non-duplicate set list, you can choose a sorted set data structure. For example, Twitter's public timeline can be stored with the publication time as the score, so that it will be automatically sorted by time when retrieved.
Implementation method: Redis sorted set internally uses HashMap and skip list (SkipList) to ensure the storage and ordering of data. HashMap stores the mapping from members to scores, while the skip list stores all members. The sorting basis is For scores stored in HashMap, using the jump table structure can achieve higher search efficiency and is relatively simple to implement.
In Redis, not all data is always stored in memory. This is the biggest difference compared with Memcached. When physical memory runs out, Redis can swap some values that have not been used for a long time to disk. Redis will only cache all key information. If Redis finds that the memory usage exceeds a certain threshold, the swap operation will be triggered. Redis calculates which keys correspond to the value required based on "swappability = age*log(size_in_memory)" swap to disk. Then the values corresponding to these keys are persisted to disk and cleared in memory. This feature allows Redis to maintain data that exceeds the memory size of its machine itself. Of course, the memory of the machine itself must be able to hold all keys, after all, these data will not be swapped. At the same time, when Redis swaps the data in the memory to the disk, the main thread that provides the service and the sub-thread that performs the swap operation will share this part of the memory. Therefore, if the data that needs to be swapped is updated, Redis will block the operation until the sub-thread Modifications can only be made after completing the swap operation. When reading data from Redis, if the value corresponding to the read key is not in the memory, then Redis needs to load the corresponding data from the swap file and then return it to the requester. There is an I/O thread pool problem here. By default, Redis will block, that is, it will not respond until all swap files are loaded. This strategy is more suitable when the number of clients is small and batch operations are performed. But if Redis is applied in a large website application, this obviously cannot meet the situation of large concurrency. Therefore, when running Redis, we set the size of the I/O thread pool and perform concurrent operations on read requests that need to load corresponding data from the swap file to reduce blocking time.
For memory-based database systems like Redis and Memcached, the efficiency of memory management is a key factor affecting system performance. The malloc/free function in the traditional C language is the most commonly used method to allocate and release memory, but this method has major flaws: first, for developers, mismatched malloc and free can easily cause memory leaks; second, Frequent calls will cause a large amount of memory fragments that cannot be recycled and reused, reducing memory utilization; finally, as a system call, its system overhead is much greater than that of ordinary function calls. Therefore, in order to improve memory management efficiency, efficient memory management solutions will not directly use malloc/free calls. Both Redis and Memcached use their own memory management mechanisms, but their implementation methods are very different. The memory management mechanisms of the two will be introduced separately below.
Memcached uses the Slab Allocation mechanism by default to manage memory. The main idea is to divide the allocated memory into blocks of specific lengths according to the predetermined size to store key-value data records of corresponding lengths to completely solve the memory fragmentation problem. The Slab Allocation mechanism is only designed to store external data, which means that all key-value data is stored in the Slab Allocation system, while other memory requests for Memcached are applied for through ordinary malloc/free, because the number of these requests and The frequency determines that they will not affect the performance of the entire system. The principle of Slab Allocation is quite simple. As shown in the figure, it first applies for a large block of memory from the operating system, divides it into chunks of various sizes, and divides chunks of the same size into groups of slab classes. Among them, Chunk is the smallest unit used to store key-value data. The size of each Slab Class can be controlled by specifying the Growth Factor when Memcached is started. Assume that the value of Growth Factor in the figure is 1.25. If the size of the first group of Chunks is 88 bytes, the size of the second group of Chunks is 112 bytes, and so on.
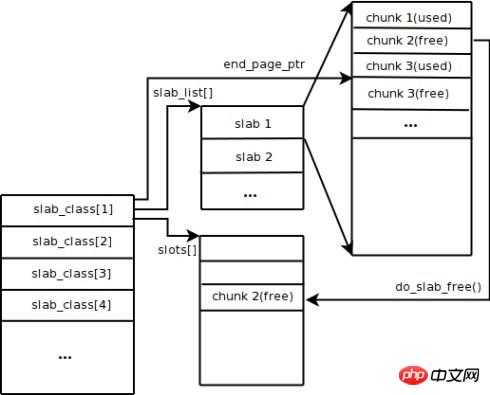
When Memcached receives the data sent by the client, it will first select the most appropriate Slab Class based on the size of the received data, and then query the list of free chunks in the Slab Class saved by Memcached to find a Slab Class that can be used to store the data. Chunk. When a database record expires or is discarded, the Chunk occupied by the record can be recycled and re-added to the free list. From the above process, we can see that Memcached's memory management system is highly efficient and will not cause memory fragmentation, but its biggest disadvantage is that it leads to a waste of space. Because each Chunk is allocated a specific length of memory space, variable-length data cannot fully utilize this space. As shown in the figure, 100 bytes of data are cached in a 128-byte Chunk, and the remaining 28 bytes are wasted.

The memory management of Redis is mainly implemented through the two files Detailed explanation of the difference between Redis and Memcached.h and Detailed explanation of the difference between Redis and Memcached.c in the source code. In order to facilitate memory management, Redis will store the size of this memory in the head of the memory block after allocating a piece of memory. As shown in the figure, real_ptr is the pointer returned by redis after calling malloc. Redis stores the size of the memory block size in the header. The memory size occupied by size is known and is the length of size_t type, and then returns ret_ptr. When memory needs to be released, ret_ptr is passed to the memory manager. Through ret_ptr, the program can easily calculate the value of real_ptr, and then pass real_ptr to free to release the memory.

Redis records all memory allocations by defining an array. The length of this array is ZMALLOC_MAX_ALLOC_STAT. Each element of the array represents the number of memory blocks allocated by the current program, and the size of the memory block is the subscript of the element. In the source code, this array is Detailed explanation of the difference between Redis and Memcached_allocations. Detailed explanation of the difference between Redis and Memcached_allocations[16] represents the number of allocated memory blocks with a length of 16 bytes. There is a static variable used_memory in Detailed explanation of the difference between Redis and Memcached.c to record the total size of currently allocated memory. Therefore, in general, Redis uses packaged mallc/free, which is much simpler than Memcached's memory management method.
Although Redis is a memory-based storage system, it itself supports the persistence of memory data and provides two main persistence strategies: RDB snapshots and AOF logs. Memcached does not support data persistence operations.
1) RDB snapshot
Redis supports a persistence mechanism that saves a snapshot of the current data into a data file, that is, an RDB snapshot. But how does a continuously writing database generate snapshots? Redis uses the copy on write mechanism of the fork command. When generating a snapshot, the current process is forked into a child process, and then all data is circulated in the child process and the data is written into an RDB file. We can configure the timing of RDB snapshot generation through Redis's save command. For example, we can configure a snapshot to be generated after 10 minutes, or a snapshot after 1,000 writes, or multiple rules can be implemented together. The definition of these rules is in the Redis configuration file. You can also set the rules while Redis is running through the Redis CONFIG SET command without restarting Redis.
Redis's RDB file will not be damaged because its writing operation is performed in a new process. When a new RDB file is generated, the sub-process generated by Redis will first write the data to a temporary file and then use it atomically. The rename system call renames the temporary file to an RDB file, so that if a failure occurs at any time, the Redis RDB file is always available. At the same time, Redis's RDB file is also a part of the internal implementation of Redis master-slave synchronization. RDB has its shortcomings, that is, once there is a problem with the database, the data saved in our RDB file is not brand new. All the data from the last RDB file generation to Redis shutdown will be lost. In some businesses, this is tolerable.
2) AOF log
The full name of AOF log is append only file, which is an append-written log file. Different from the binlog of general databases, AOF files are identifiable plain text, and their contents are Redis standard commands one by one. Only commands that will cause data to be modified will be appended to the AOF file. Each command to modify data generates a log, and the AOF file will become larger and larger, so Redis provides another function called AOF rewrite. Its function is to regenerate an AOF file. There will only be one operation on a record in the new AOF file, unlike an old file, which may record multiple operations on the same value. The generation process is similar to RDB. It also forks a process, traverses the data directly, and writes a new AOF temporary file. During the process of writing a new file, all write operation logs will still be written to the original old AOF file, and will also be recorded in the memory buffer. When the redundancy operation is completed, all logs in the buffer will be written to the temporary file at once. Then call the atomic rename command to replace the old AOF file with the new AOF file.
AOF is a file writing operation. Its purpose is to write the operation log to the disk, so it will also encounter the writing operation process we mentioned above. After calling write on AOF in Redis, use the appendfsync option to control the time it takes to call fsync to write it to the disk. The security strength of the following three settings of appendfsync gradually becomes stronger.
appendfsync no When appendfsync is set to no, Redis will not actively call fsync to synchronize the AOF log content to the disk, so all this depends entirely on the debugging of the operating system. For most Linux operating systems, fsync is performed every 30 seconds to write the data in the buffer to the disk.
appendfsync everysec When appendfsync is set to everysec, Redis will make an fsync call every second by default to write the data in the buffer to disk. But when this fsync call lasts longer than 1 second. Redis will adopt the strategy of delaying fsync and wait for another second. That is to say, fsync will be performed after two seconds. This time fsync will be performed no matter how long it takes to execute. At this time, because the file descriptor will be blocked during fsync, the current write operation will be blocked. So the conclusion is that in most cases, Redis will perform fsync every second. In the worst case, an fsync operation occurs every two seconds. This operation is called group commit in most database systems. It combines the data of multiple write operations and writes the log to the disk at one time.
appednfsync always When appendfsync is set to always, fsync will be called once for every write operation. At this time, the data is the most secure. Of course, since fsync will be executed every time, its performance will also be affected.
For general business needs, it is recommended to use RDB for persistence. The reason is that the overhead of RDB is much lower than that of AOF logs. For those applications that cannot tolerate data loss, it is recommended to use AOF logs.
Memcached is a full-memory data buffering system. Although Redis supports data persistence, full-memory is the essence of its high performance. As a memory-based storage system, the size of the machine's physical memory is the maximum amount of data that the system can accommodate. If the amount of data that needs to be processed exceeds the physical memory size of a single machine, a distributed cluster needs to be built to expand storage capabilities.
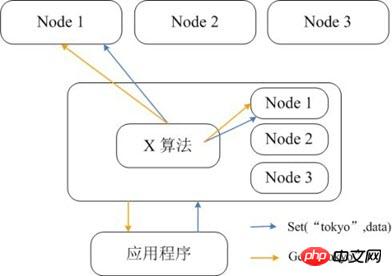
Memcached itself does not support distribution, so Memcached's distributed storage can only be implemented on the client through distributed algorithms such as consistent Detailed explanation of the difference between Redis and Memcacheding. The figure below shows the distributed storage implementation architecture of Memcached. Before the client sends data to the Memcached cluster, the target node of the data will first be calculated through the built-in distributed algorithm, and then the data will be sent directly to the node for storage. But when the client queries data, it must also calculate the node where the query data is located, and then directly send a query request to the node to obtain the data.
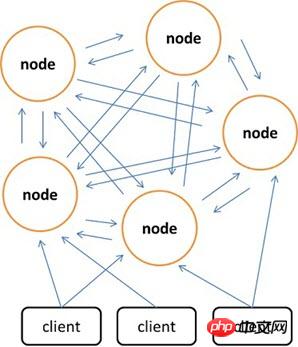
Compared with Memcached, which can only use the client to implement distributed storage, Redis prefers to build distributed storage on the server side. The latest version of Redis already supports distributed storage functions. Redis Cluster is an advanced version of Redis that implements distribution and allows single points of failure. It has no central node and has linear scalability. The figure below shows the distributed storage architecture of Redis Cluster, in which nodes communicate with each other through the binary protocol, and between nodes and clients communicate through the ascii protocol. In terms of data placement strategy, Redis Cluster divides the entire key value field into 4096 Detailed explanation of the difference between Redis and Memcached slots, and each node can store one or more Detailed explanation of the difference between Redis and Memcached slots. That is to say, the maximum number of nodes currently supported by Redis Cluster is 4096. The distributed algorithm used by Redis Cluster is also very simple: crc16(key) % HASH_SLOTS_NUMBER.
In order to ensure data availability under single point of failure, Redis Cluster introduces Master node and Slave node. In Redis Cluster, each Master node has two corresponding Slave nodes for redundancy. In this way, in the entire cluster, the downtime of any two nodes will not cause data unavailability. When the Master node exits, the cluster will automatically select a Slave node to become the new Master node.
The above is the detailed content of Detailed explanation of the difference between Redis and Memcached. For more information, please follow other related articles on the PHP Chinese website!
 The difference between static web pages and dynamic web pages
The difference between static web pages and dynamic web pages
 What is the difference between 4g and 5g mobile phones?
What is the difference between 4g and 5g mobile phones?
 The difference between k8s and docker
The difference between k8s and docker
 The difference between JD.com's self-operated flagship store and its official flagship store
The difference between JD.com's self-operated flagship store and its official flagship store
 Commonly used database software
Commonly used database software
 What are the in-memory databases?
What are the in-memory databases?
 Which one has faster reading speed, mongodb or redis?
Which one has faster reading speed, mongodb or redis?
 How to use redis as a cache server
How to use redis as a cache server








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



