

Share a MySQL multi-column index optimization example code

As the data captured by crawlers continues to increase, the database and query statements have been continuously optimized in the past two days. One of the table structures is as follows:
CREATE TABLE `newspaper_article` ( `id` varchar(50) NOT NULL COMMENT '编号', `title` varchar(190) NOT NULL COMMENT '标题', `author` varchar(255) DEFAULT NULL COMMENT '作者', `date` date NULL DEFAULT NULL COMMENT '发表时间', `content` longtext COMMENT '正文', `status` tinyint(4) DEFAULT '0', PRIMARY KEY (`id`), KEY `idx_status_date` (`status`,`date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
According to business needs, the idx_status_date index has been added, which is particularly time-consuming when executing the following SQL:
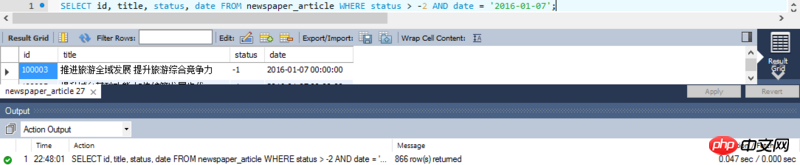
SELECT id, title, status, date FROM article WHERE status > -2 AND date = '2016-01-07';
According to observations, the number of new data added every day is approximately within 2,500. I thought that a specific date was specified here '2016-01-07', and the actual amount of data that needs to be scanned should be within 2500, but this is not the case: 
A total of 185,589 pieces of data were actually scanned, which was much higher than the estimated 2,500 pieces, and the actual execution time was nearly 3 seconds:

Why is this?
Solution
After changing idx_status_date (status, date) to idx_status (status), check the MySQL execution plan:

You can see that after changing the multi-column index to a single-column index, there is no change in the total amount of data to be scanned in the execution plan. Combined with the fact that multi-column indexes follow the leftmost prefix principle, it is speculated that the above query statement only uses the index of the leftmost status of idx_status_date.
I flipped through "High Performance MySQL" and found the following passage, which confirmed my idea:
If there is a range query for a certain column in the query, then the right side of All columns cannot be looked up using index optimization. For example, there is a query
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23'. This query can only use the first two columns of the index, because hereLIKEis a range condition (but the server can use the remaining columns for other purposes). If the number of range query column values is limited, you can replace the range condition by using multiple equal conditions.
Therefore, there are two solutions here:
You can replace the range condition by using multiple equal conditions
-
Modify
idx_status_date (status, date)to indexidx_date_status (date, status)and create a newidx_statusindex to achieve the same effect.
Optimized execution plan:

B-Tree indexes. It uses B-Tree data structure to store data. We use the term "B-Tree" because MySQL also uses this keyword in CREATE TABLE and other statements. However, the underlying storage engine may also use different storage structures. InnoDB uses B+Tree. Suppose there is the following data table:
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
- Full value matching
Full value matching refers to Match all columns in the index. For example, the index in the above table can be used to find people named Cuba Allen and born on 1960-01-01.
- Match the leftmost prefix
The index in the above table can be used to find all people with the last name of Allen, that is, only the first column of the index is used.
- Match column prefix
Only matches the beginning of the value of a column. For example, the index in the above table can be used to find all people whose last names begin with J. Only the first column of the index is used here.
- Matching range values
For example, the index in the above table can be used to find people with last names between Allen and Barrymore. Only the first column of the index is used here.
- Exactly match a certain column and range match another column
The index in the above table can also be used to find all people whose last name is Allen and whose first name starts with the letter K (such as Kim, Karl, etc.) people. That is, the first column last_name matches completely, and the second column first_name matches the range.
- Query that only accesses the index
B-Tree can usually support "query that only accesses the index", that is, the query only needs to access the index without accessing the data rows.
- If you do not start searching according to the leftmost column of the index, you cannot use the index. For example, the index in the above table cannot be used to find people named Bill, nor can it be used to find people with a specific birthday, because neither column is the leftmost data column. Similarly, there is no way to find people whose last names end with a certain letter.
Columns in the index cannot be skipped. That is, the index on the table above cannot be used to find people with the last name Smith who were born on a specific date. If you do not specify a name (first_name), MySQL can only use the first column of the index.
If there is a range query for a certain column in the query, all columns to the right of it cannot be searched using index optimization. For example, there is a query
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23'. This query can only use the first two columns of the index, because hereLIKEis a range condition (but the server can use the remaining columns for other purposes). If the number of range query column values is limited, you can replace the range condition by using multiple equal conditions.
The above is the detailed content of Share a MySQL multi-column index optimization example code. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1392
1392
 52
36
110
52
36
110

 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
How to connect to the database of apache
Apr 13, 2025 pm 01:03 PM
Apache connects to a database requires the following steps: Install the database driver. Configure the web.xml file to create a connection pool. Create a JDBC data source and specify the connection settings. Use the JDBC API to access the database from Java code, including getting connections, creating statements, binding parameters, executing queries or updates, and processing results.
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
 How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
How to start mysql by docker
Apr 15, 2025 pm 12:09 PM
The process of starting MySQL in Docker consists of the following steps: Pull the MySQL image to create and start the container, set the root user password, and map the port verification connection Create the database and the user grants all permissions to the database
