

Use the xml.etree.ElementTree module as follows to parse XML files. The ElementTree module provides two classes to accomplish this purpose:
ElementTree represents the entire XML file (a tree structure)
Element represents an element (node) in the tree
We operate the following XML file: migapp.xml

We can import the ElementTree module as follows: import xml.etree.ElementTree as ET
Or we can only import the parse parser: from xml.etree.ElementTree import parse
First you need to open an xml file. For local files, use the open function. If it is an Internet file, use urlopen:
f = open( ' migapp.xml ' , ' rt ' , encoding= ' utf -8 ' )
Then parse the XML.
1.1 Parse the root element
tree = ET.parse(f) root = tree.getroot() print('root.tag =', root.tag) print('root.attrib =', root.attrib)

1.2 Parse the son of the root
for child in root: # 仅可以解析出root的儿子,不能解析出root的子孙
print(child.tag)
print(child.attrib) # attrib is a dict
1.3 Resolving descendants of the root by index
print(root[1][1].tag) print(root[1][1].text)

1.4 Iteratively parse out all specified elements
for element in root.iter('environment'):
print(element.attrib)
Several useful methods
# element.findall()解析出指定element的所有儿子
# element.find()解析出指定element的第一个儿子
# element.get()解析出指定element的属性attrib
for environment in root.findall('environment'):
first_variable = environment.find('variable')
print(first_variable.get('name')) 
for text in root.iter('text'):
text.set('size', '50')
text.text = 'Benxin Tuzi'
text.append(ET.Element('date', attrib={}, text='2016/01/16'))
tree.write('output.xml')migapp.xml:
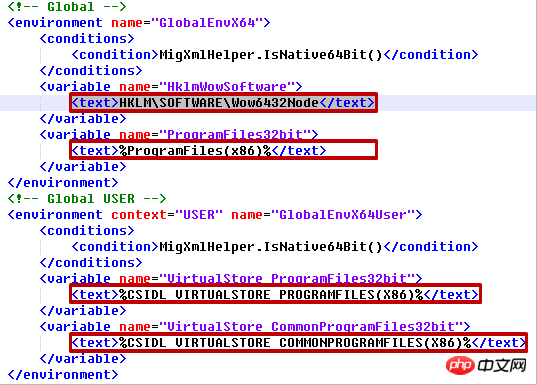
in Corresponding part:
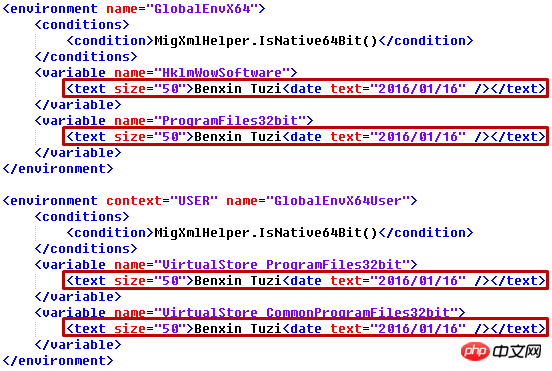 3 Notes
3 Notes
Analysis:
This is due to import It will first search in the current path, and then it is found that the xml.py module exists, and the xml.py we wrote ourselves is of course not a package
Note:
It still cannot be used after deleting xml.py Successfully explained, that is because xml.pyc is also generated in the current path, and the priority of this file is higher than xml.py, so the interpreter still looks for it in xml.pyc first, so this file must also be deleted. Solve the problem successfully.
Conclusion:
Try not to have the file name have the same name as the package name or module name, even if you do not use the module or package in the script, otherwise strange errors may occur.
The above is the detailed content of python parsing XML file example (picture). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



