

This article shares with you the method and code of using python crawler to convert "Liao Xuefeng's Python Tutorial" into PDF. Friends in need can refer to it.
It seems that there is no easier way to write a crawler than using Python. It's appropriate. There are so many crawler tools provided by the Python community that you will be dazzled. With various libraries that can be used directly, you can write a crawler in minutes. Today I am thinking about writing a crawler and crawling down Liao Xuefeng's Python tutorial. Create a PDF e-book for everyone to read offline.
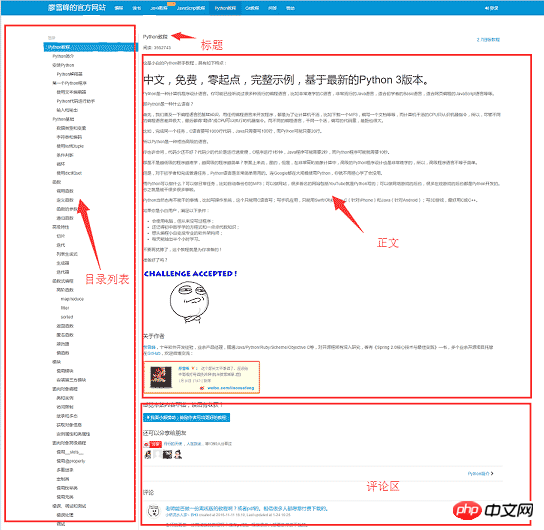
Before we start writing the crawler, let’s first analyze the page structure of the website 1. The left side of the web page is the directory outline of the tutorial. Each URL corresponds to an article on the right. The upper right side is the article’s The title, in the middle is the text part of the article. The text content is the focus of our concern. The data we want to crawl is the text part of all web pages. Below is the user's comment area. The comment area is of no use to us, so we can ignore it.
Tool preparation
After you have figured out the basic structure of the website, you can start preparing the tool kits that the crawler depends on. requests and beautifulsoup are two artifacts of crawlers, reuqests is used for network requests, and beautifusoup is used to operate html data. With these two shuttles, we can work quickly. We don’t need crawlers like scrapyframework. Using it in small programs is like killing a chicken with a sledgehammer. In addition, since you are converting html files to pdf, you must also have corresponding library support. wkhtmltopdf is a very good tool, which can convert html to pdf for multiple platforms. pdfkit is the Python package of wkhtmltopdf. FirstInstallthe following dependency packages,
Then install wkhtmltopdf
pip install requests pip install beautifulsoup pip install pdfkit
Install wkhtmltopdf
Windows platform directly on the wkhtmltopdf official website 2 Download the stable version and install it. After the installation is completed, add the execution path of the program to the system environment $PATH variable , otherwise pdfkit cannot find wkhtmltopdf and the error "No wkhtmltopdf executable found" will appear. Ubuntu and CentOS can be installed directly using the command line
$ sudo apt-get install wkhtmltopdf # ubuntu $ sudo yum intsall wkhtmltopdf # centos
Crawler implementation
After everything is ready, you can start coding, but you should sort out your thoughts before writing code . The purpose of the program is to save the html text parts corresponding to all URLs locally, and then use pdfkit to convert these files into a pdf file. Let's split the task. First, save the html text corresponding to a certain URL locally, and then find all URLs and perform the same operation.
Use the Chrome browser to find the tag in the body part of the page, and press F12 to find the p tag corresponding to the body: <p >, where p is the body content of the web page. After using requests to load the entire page locally, you can use beautifulsoup to operate the HTML dom element to extract the text content.
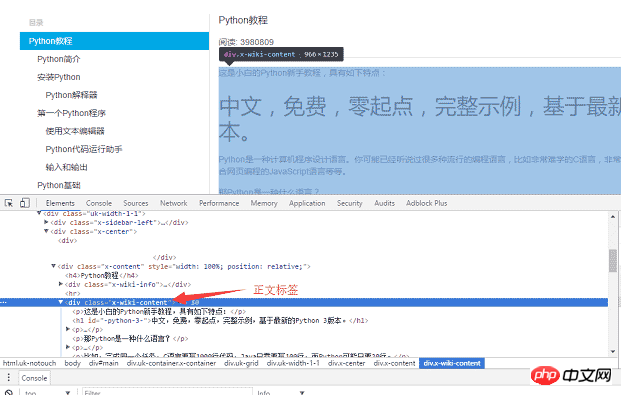
The specific implementation code is as follows: Use soup.find_all function to find the text tag, and then save the content of the text part to the a.html file.
def parse_url_to_html(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, "html5lib")
body = soup.find_all(class_="x-wiki-content")[0]
html = str(body)
with open("a.html", 'wb') as f:
f.write(html)The second step is to parse out all the URLs on the left side of the page. Use the same method to find the left menu label <ul >
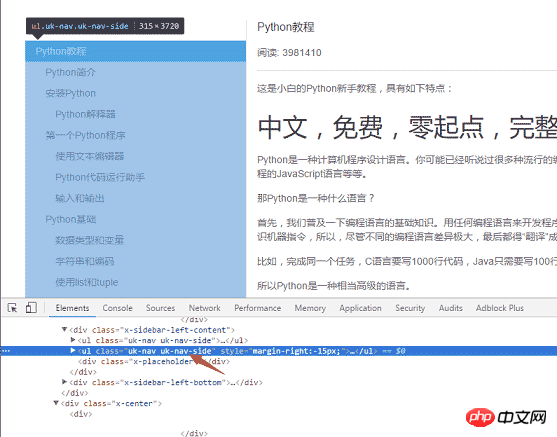
def get_url_list():
"""
获取所有URL目录列表
"""
response = requests.get("http://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000")
soup = BeautifulSoup(response.content, "html5lib")
menu_tag = soup.find_all(class_="uk-nav uk-nav-side")[1]
urls = []
for li in menu_tag.find_all("li"):
url = "http://www.liaoxuefeng.com" + li.a.get('href')
urls.append(url)
return urlsdef save_pdf(htmls):
"""
把所有html文件转换成pdf文件
"""
options = {
'page-size': 'Letter',
'encoding': "UTF-8",
'custom-header': [
('Accept-Encoding', 'gzip')
]
}
pdfkit.from_file(htmls, file_name, options=options)
Summary
The total amount of code adds up to less than 50 lines. However, wait, in fact, the code given above omits some details. , for example, how to get the title of the article, the img tag of the text content uses a relative path, if you want to display thepicture normally in the pdf, you need to change the relative path to an absolute path, and save it Temporary html files must be delete, and these details are all posted on github.
【related suggestion】2. Python Object-Oriented Video Tutorial
The above is the detailed content of Convert data captured by python crawler into PDF. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



