
 Java
javaTutorial
Detailed explanation of how LinkedHashMap ensures the order of element iteration
Java
javaTutorial
Detailed explanation of how LinkedHashMap ensures the order of element iteration
Detailed explanation of how LinkedHashMap ensures the order of element iteration

This article mainly introduces the relevant knowledge of LinkedHashMap in Java, which has a good reference value. Let’s take a look at it with the editor
First introduction to LinkedHashMap
In most cases, as long as there are no thread safety issues involved, Map can basically use HashMap, but There is a problem with HashMap, that is, the order in which HashMap is iterated is not the order in which HashMap is placed, which means it is out of order. This shortcoming of HashMap often causes trouble, because in some scenarios, we expect an ordered Map. At this time, LinkedHashMap makes its debut. Although it increases time and space overhead, By maintaining a doubly linked list that runs on all entries, LinkedHashMap ensures element iteration Order.
Answers to four concerns on LinkedHashMap
Attention points
| LinkedHashMap allows empty | |
| and Value both allow empty | LinkedHashMap Whether duplicate data is allowed |
| Is LinkedHashMap in order | |
| Is LinkedHashMap thread-safe | |
|
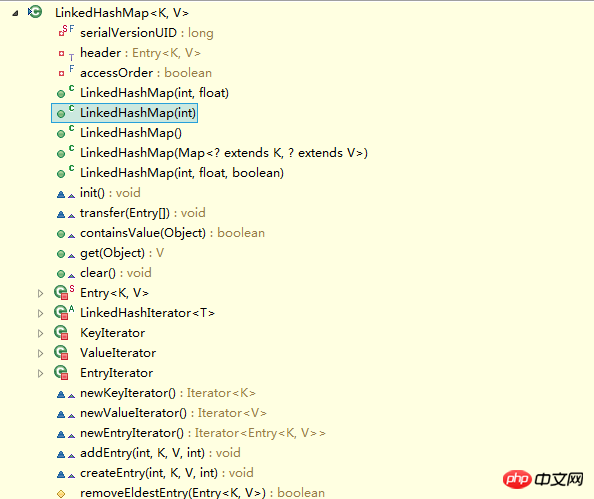
Basic structure of LinkedHashMap Regarding LinkedHashMap, let me mention two points: 1. LinkedHashMap can be considered as HashMap+Linked List, that is, it not only uses HashMap to operate the data structure, but also uses LinkedList to maintain the order of inserted elements 2. The basic implementation idea of LinkedHashMap That is----Polymorphism. It can be said that understanding polymorphism and then understanding the LinkedHashMap principle will get twice the result with half the effort; conversely, learning the LinkedHashMap principle can also promote and deepen the understanding of polymorphism. Why can we say this? First, take a look at the definition of LinkedHashMap: public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
}Copy after login See that LinkedHashMap is a subclass of HashMap. Naturally LinkedHashMap also inherits from HashMap. All non-private methods. Take another look at the methods in LinkedHashMap:
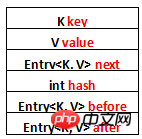
See that there are no methods for operating data structures in LinkedHashMap, which means that LinkedHashMap operates on data structures (such as putting a piece of data) , the method of operating data is exactly the same as HashMap, but there are some differences in details. The difference between LinkedHashMap and HashMap lies in their basic data structure. Take a look at the basic data structure of LinkedHashMap, which is Entry: private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}Copy after login List some of the attributes in EntryBar:
next is used to maintain the order of connected Entries at the specified table position of HashMap, and before and After are used to maintain the order of Entry insertion. Let’s use a diagram to represent it and just list the attributes:
Suppose there is such a piece of code: public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}Copy after login First of all, line 3~line 4, a new LinkedHashMap comes out, take a look at what is done: public LinkedHashMap() {
super();
accessOrder = false;
}Copy after login public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}Copy after login void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
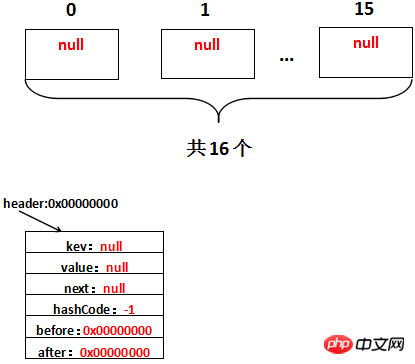
}Copy after login /** * The head of the doubly linked list. */ private transient Entry<K,V> header; Copy after login The first multiple appears here Status: init() method. Although the init() method is defined in HashMap, due to: 1, LinkedHashMap rewrites the init method 2, and the instantiated LinkedHashMap is actually called The init method is the init method overridden by LinkedHashMap. Assume that the address of the header is 0x00000000, then after initialization, it actually looks like this:
Continue to look at LinkedHashMap Adding elements, that is, what put("111","111") does, is of course calling the put method of HashMap: public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}Copy after login Copy after login Line 17 is another polymorphism, because LinkedHashMap rewrites addEntry method, so addEntry calls the rewritten method of LinkedHashMap: void addEntry(int hash, K key, V value, int bucketIndex) {
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}Copy after login Because LinkedHashMap itself maintains the order of insertion, LinkedHashMap can be used for caching, line 5 ~ Line 7 is used to support the FIFO algorithm, so you don’t need to worry about it here for the time being. Take a look at the createEntry method: void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}Copy after login private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}Copy after login Copy after login The code in lines 2 to 4 is no different from HashMap, the newly added elements When placed on table[i], the difference is that LinkedHashMap also performs the addBefore operation. The meaning of these four lines of code is to generate a doubly linked list between the new Entry and the original linked list. Assume that string 111 is placed at location table[1], and the generated Entry address is 0x00000001, then the graphic representation is as follows:
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000 2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此时是0x00000000,因此新增的Entry的before=0x00000000 3、before.after=this,新增的Entry的before此时为0x00000000即header,header的after=this,即header的after=0x00000001 4、after.before=this,新增的Entry的after此时为0x00000000即header,header的before=this,即header的before=0x00000001 这样,header与新增的Entry的一个双向链表就形成了。再看,新增了字符串222之后是什么样的,假设新增的Entry的地址为0x00000002,生成到table[2]上,用图表示是这样的:
就不细解释了,只要before、after清除地知道代表的是哪个Entry的就不会有什么问题。 总得来看,再说明一遍,LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。 利用LinkedHashMap实现LRU算法缓存 前面讲了LinkedHashMap添加元素,删除、修改元素就不说了,比较简单,和HashMap+LinkedList的删除、修改元素大同小异,下面讲一个新的内容。 LinkedHashMap可以用来作缓存,比方说LRUCache,看一下这个类的代码,很简单,就十几行而已: public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
}
protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
}
private static final long serialVersionUID = 1L;
protected int maxElements;
}Copy after login 顾名思义,LRUCache就是基于LRU算法的Cache(缓存),这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以实现LRU算法的缓存基于两点: 1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致 2、LinkedList提供了一个boolean值可以让用户指定是否实现LRU 那么,首先我们了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。 我们看一下LinkedList带boolean型参数的构造方法: public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}Copy after login 就是这个accessOrder,它表示: (1)false,所有的Entry按照插入的顺序排列 (2)true,所有的Entry按照访问的顺序排列 第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。 "访问",这个词有两层意思: 1、根据Key拿到Value,也就是get方法 2、修改Key对应的Value,也就是put方法 首先看一下get方法,它在LinkedHashMap中被重写: public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}Copy after login 然后是put方法,沿用父类HashMap的: public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}Copy after login Copy after login 修改数据也就是第6行~第14行的代码。看到两端代码都有一个共同点:都调用了recordAccess方法,且这个方法是Entry中的方法,也就是说每次的recordAccess操作的都是某一个固定的Entry。 recordAccess,顾名思义,记录访问,也就是说你这次访问了双向链表,我就把你记录下来,怎么记录?把你访问的Entry移到尾部去。这个方法在HashMap中是一个空方法,就是用来给子类记录访问用的,看一下LinkedHashMap中的实现: void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}Copy after login private void remove() {
before.after = after;
after.before = before;
}Copy after login private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}Copy after login Copy after login 看到每次recordAccess的时候做了两件事情: 1、把待移动的Entry的前后Entry相连 2、把待移动的Entry移动到尾部 当然,这一切都是基于accessOrder=true的情况下。最后用一张图表示一下整个recordAccess的过程吧:
代码演示LinkedHashMap按照访问顺序排序的效果 最后代码演示一下LinkedList按照访问顺序排序的效果,验证一下上一部分LinkedHashMap的LRU功能: public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>(16, 0.75f, true);
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
linkedHashMap.put("333", "333");
linkedHashMap.put("444", "444");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.get("111");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.put("222", "2222");
loopLinkedHashMap(linkedHashMap);
}
public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
Set<Map.Entry<String, String>> set = inkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = set.iterator();
while (iterator.hasNext())
{
System.out.print(iterator.next() + "\t");
}
System.out.println();
}Copy after login 注意这里的构造方法要用三个参数那个且最后的要传入true,这样才表示按照访问顺序排序。看一下代码运行结果: 111=111 222=222 333=333 444=444 222=222 333=333 444=444 111=111 333=333 444=444 111=111 222=2222 Copy after login 代码运行结果证明了两点: 1、LinkedList是有序的 2、每次访问一个元素(get或put),被访问的元素都被提到最后面去了 【相关推荐】 1. Java免费视频教程 2. 全面解析Java注解 3. Java教程手册 |
 If If you are familiar with the source code of LinkedList, it should not be difficult to understand. Let me explain it. Note that existingEntry represents the header:
If If you are familiar with the source code of LinkedList, it should not be difficult to understand. Let me explain it. Note that existingEntry represents the header: 

The above is the detailed content of Detailed explanation of how LinkedHashMap ensures the order of element iteration. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Square Root in Java
Aug 30, 2024 pm 04:26 PM
Square Root in Java
Aug 30, 2024 pm 04:26 PM
Guide to Square Root in Java. Here we discuss how Square Root works in Java with example and its code implementation respectively.
 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Random Number Generator in Java
Aug 30, 2024 pm 04:27 PM
Random Number Generator in Java
Aug 30, 2024 pm 04:27 PM
Guide to Random Number Generator in Java. Here we discuss Functions in Java with examples and two different Generators with ther examples.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Armstrong Number in Java
Aug 30, 2024 pm 04:26 PM
Armstrong Number in Java
Aug 30, 2024 pm 04:26 PM
Guide to the Armstrong Number in Java. Here we discuss an introduction to Armstrong's number in java along with some of the code.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
