
 Web Front-end
JS Tutorial
Detailed explanation of how to use Node.js to segment text content and extract keywords
Web Front-end
JS Tutorial
Detailed explanation of how to use Node.js to segment text content and extract keywords
Detailed explanation of how to use Node.js to segment text content and extract keywords

This article mainly introduces the use of Node.js to segment text content and extract keywords. Friends who need it can refer to
before discussing technology. Let’s be cute first, you don’t understand the world of foodies~~
Zhongcheng translated articles have tags, users can quickly filter articles of interest based on tags, and the articles are also Relevant recommendations can be made based on tag associations. But now Zhongcheng Translation’s tags are set when recommending articles, and they are all in English, and manual settings are inevitably not standardized and complete. Although articles can be manually edited after publishing, we cannot expect users or administrators to edit appropriate tags all the time, so we need to use tools to automatically generate tags.
Among the current open source word segmentation tools, jieba is a word segmentation component with powerful functions and excellent performance. Fortunately, it has a node version.
nodejieba's installation and use are very simple:
npm install nodejieba
var nodejieba = require("nodejieba");
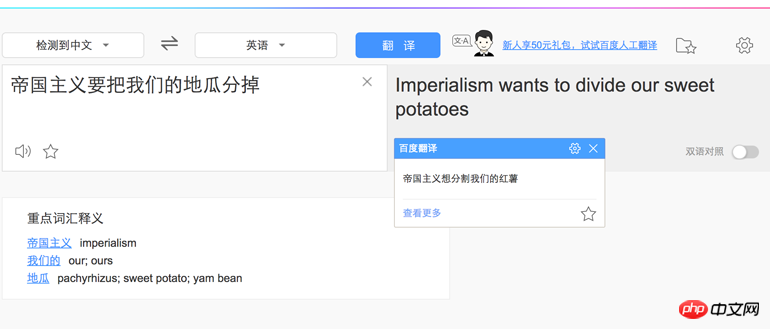
var result = nodejieba.cut("帝国主义要把我们的地瓜分掉");
console.log(result);
//[ '帝国主义', '要', '把', '我们', '的', '地', '瓜分', '掉' ]
result = nodejieba.cut('土地,俺老孙的金箍棒在哪里?');
console.log(result);
//[ '土地', ',', '俺', '老', '孙', '的', '金箍棒', '在', '哪里', '?' ]
result = nodejieba.cut('大圣,您的金箍棒就棒在特别配您的头型!');
console.log(result);
//[ '大圣',',','您','的','金箍棒','就','棒','在','特别','配','您','的','头型','!' ]We can load our own dictionary and set the weight and part of speech for each word in the dictionary:
Edit user.uft8
Sweet Potato 9999 n
Golden Hoop 9999 n
stick is great in 9999
Then load the dictionary through nodejieba.load.
var nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
var result = nodejieba.cut("帝国主义要把我们的地瓜分掉");
console.log(result);
//[ '帝国主义', '要', '把', '我们', '的', '地瓜', '分', '掉' ]
result = nodejieba.cut('土地,俺老孙的金箍棒在哪里?');
console.log(result);
//[ '土地', ',', '俺', '老', '孙', '的', '金箍棒', '在', '哪里', '?' ]
result = nodejieba.cut('大圣,您的金箍棒就棒在特别配您的头型!');
console.log(result);
//[ '大圣', ',', '您', '的', '金箍', '棒就棒在', '特别', '配', '您', '的', '头型', '!' ]In addition to word segmentation, we can use nodejieba to extract keywords:
const content = `
HTTP, HTTP/2 and Performance optimization
The purpose of this article is Through comparison, I will tell you why you should migrate from HTTP to HTTPS and why support for HTTP/2 should be added. Before comparing HTTP and HTTP/2, let’s first look at what HTTP is.
What is HTTP
HTTP is a set of rules for communication on the World Wide Web. HTTP is an application layer protocol and runs on top of the TCP/IP layer. When a user requests a web page through a browser, HTTP is responsible for processing the request and establishing a connection between the web server and the client.
With HTTP/2, performance can be improved without using sprite images, compression, or splicing. However, this does not mean that these techniques should not be used. But this has clearly demonstrated the necessity for us to move from HTTP/1.1 to HTTP/2.
`;
const nodejieba = require("nodejieba");
const result = nodejieba.extract(content, 20);
console.log(result);The output result is similar to the following:
[ { word: 'HTTP', weight: 140.8704516850025 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 },
{ word: '必要性', weight: 8.81927328699 },
{ word: '添加', weight: 8.0484751722 } ]We add some new keywords to the dictionary:
Performance
HTTP/2
The output results are as follows:
[ { word: 'HTTP', weight: 105.65283876375187 },
{ word: 'HTTP/2', weight: 58.69602153541771 },
{ word: '请求', weight: 14.23018001394 },
{ word: '应该', weight: 14.052171126120001 },
{ word: '性能', weight: 12.61259281884 },
{ word: '万维网', weight: 12.2912397395 },
{ word: 'IP', weight: 11.739204307083542 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: '1.1', weight: 11.739204307083542 },
{ word: 'TCP', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '雪碧图', weight: 11.739204307083542 },
{ word: '应用层', weight: 11.2616203224 },
{ word: '客户端', weight: 11.1926274509 },
{ word: '浏览器', weight: 10.8561552143 },
{ word: '拼接', weight: 9.85762638414 },
{ word: '比较', weight: 9.5435285574 },
{ word: '网页', weight: 9.53122979951 },
{ word: '服务器', weight: 9.41204128224 },
{ word: '使用', weight: 9.03259988558 } ]On this basis, we use the whitelist method to filter out some words that can be used as tags:
const content = `
HTTP, HTTP/2 and performance optimization
The purpose of this article is to tell you through comparison why you should migrate from HTTP to HTTPS, and why support for HTTP/2 should be added. Before comparing HTTP and HTTP/2, let’s first look at what HTTP is.
What is HTTP
HTTP is a set of rules for communication on the World Wide Web. HTTP is an application layer protocol that runs on top of the TCP/IP layer. When a user requests a web page through a browser, HTTP is responsible for processing the request and establishing a connection between the web server and the client.
With HTTP/2, performance can be improved without using sprite images, compression, or splicing. However, this does not mean that these techniques should not be used. But this has clearly demonstrated the necessity for us to move from HTTP/1.1 to HTTP/2.
`;
const nodejieba = require("nodejieba");
nodejieba.load({
userDict: './user.utf8',
});
const result = nodejieba.extract(content, 20);
const tagList = ['HTTPS', 'HTTP', 'HTTP/2', 'Web', '浏览器', '性能'];
console.log(result.filter(item => tagList.indexOf(item.word) >= 0));Finally we get:
[ { word: 'HTTP', weight: 105.65283876375187 },
{ word: 'HTTP/2', weight: 58.69602153541771 },
{ word: '性能', weight: 12.61259281884 },
{ word: 'HTTPS', weight: 11.739204307083542 },
{ word: 'Web', weight: 11.739204307083542 },
{ word: '浏览器', weight: 10.8561552143 } ]This is the result we want.
The above is the basic method of using the word segmentation library nodejieba. In the future, we can use it to automatically analyze and add corresponding tags to the translations published by Zhongcheng Translation, so as to provide translators and readers with a better user experience.
The above is the detailed content of Detailed explanation of how to use Node.js to segment text content and extract keywords. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1390
1390
 52
52

 Detailed graphic explanation of the memory and GC of the Node V8 engine
Mar 29, 2023 pm 06:02 PM
Detailed graphic explanation of the memory and GC of the Node V8 engine
Mar 29, 2023 pm 06:02 PM
This article will give you an in-depth understanding of the memory and garbage collector (GC) of the NodeJS V8 engine. I hope it will be helpful to you!
 An article about memory control in Node
Apr 26, 2023 pm 05:37 PM
An article about memory control in Node
Apr 26, 2023 pm 05:37 PM
The Node service built based on non-blocking and event-driven has the advantage of low memory consumption and is very suitable for handling massive network requests. Under the premise of massive requests, issues related to "memory control" need to be considered. 1. V8’s garbage collection mechanism and memory limitations Js is controlled by the garbage collection machine
 Let's talk about how to choose the best Node.js Docker image?
Dec 13, 2022 pm 08:00 PM
Let's talk about how to choose the best Node.js Docker image?
Dec 13, 2022 pm 08:00 PM
Choosing a Docker image for Node may seem like a trivial matter, but the size and potential vulnerabilities of the image can have a significant impact on your CI/CD process and security. So how do we choose the best Node.js Docker image?
 Let's talk in depth about the File module in Node
Apr 24, 2023 pm 05:49 PM
Let's talk in depth about the File module in Node
Apr 24, 2023 pm 05:49 PM
The file module is an encapsulation of underlying file operations, such as file reading/writing/opening/closing/delete adding, etc. The biggest feature of the file module is that all methods provide two versions of **synchronous** and **asynchronous**, with Methods with the sync suffix are all synchronization methods, and those without are all heterogeneous methods.
 Node.js 19 is officially released, let's talk about its 6 major features!
Nov 16, 2022 pm 08:34 PM
Node.js 19 is officially released, let's talk about its 6 major features!
Nov 16, 2022 pm 08:34 PM
Node 19 has been officially released. This article will give you a detailed explanation of the 6 major features of Node.js 19. I hope it will be helpful to you!
 Let's talk about the GC (garbage collection) mechanism in Node.js
Nov 29, 2022 pm 08:44 PM
Let's talk about the GC (garbage collection) mechanism in Node.js
Nov 29, 2022 pm 08:44 PM
How does Node.js do GC (garbage collection)? The following article will take you through it.
 Let's talk about the event loop in Node
Apr 11, 2023 pm 07:08 PM
Let's talk about the event loop in Node
Apr 11, 2023 pm 07:08 PM
The event loop is a fundamental part of Node.js and enables asynchronous programming by ensuring that the main thread is not blocked. Understanding the event loop is crucial to building efficient applications. The following article will give you an in-depth understanding of the event loop in Node. I hope it will be helpful to you!
 What should I do if node cannot use npm command?
Feb 08, 2023 am 10:09 AM
What should I do if node cannot use npm command?
Feb 08, 2023 am 10:09 AM
The reason why node cannot use the npm command is because the environment variables are not configured correctly. The solution is: 1. Open "System Properties"; 2. Find "Environment Variables" -> "System Variables", and then edit the environment variables; 3. Find the location of nodejs folder; 4. Click "OK".
