

Speaking of query optimization of MySQL, I believe everyone has accumulated a lot of skills: do not use SELECT *, do not use NULL fields, and create reasonably Index, choose the appropriatedata type for the field... Do you really understand these optimization techniques? Do you understand how it works? Is the performance really improved in actual scenarios? I don't think so. Therefore, it is particularly important to understand the principles behind these optimization suggestions. I hope this article will enable you to re-examine these optimization suggestions and apply them reasonably in actual business scenarios.
MySQL logicArchitecture
If you can build a picture in your mind of how the various components of MySQL work together Architecture diagram helps to understand the MySQL server in depth. The following figure shows the logical architecture diagram of MySQL.
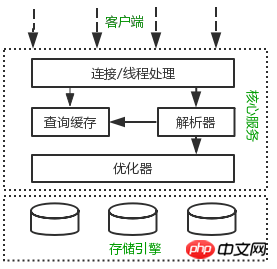
Connection processing, authorization authentication, security and other functions are all Processed at this level.
Most of MySQL’s core services are in the middle layer, including query parsing, analysis, optimization,caching, built-in functions (such as : time, mathematics, encryption and other functions). All cross-storage engine functions are also implemented in this layer: Stored procedures, Triggers, Views, etc.
The lowest layer is the storage engine, which is responsible for data storage and retrieval in MySQL. Similar to thefile system under Linux, each storage engine has its advantages and disadvantages. The intermediate service layer communicates with the storage engine through API. These APIinterfaces shield the differences between different storage engines.
MySQL query processWe always hope that MySQL can obtain higher query performance. The best way is to figure out how MySQL optimizes and executes queries. Once you understand this, you will find that a lot of query optimization work is actually just following some principles so that the MySQL optimizer can run in the expected and reasonable way. When sending a request to MySQL, what exactly does MySQL do?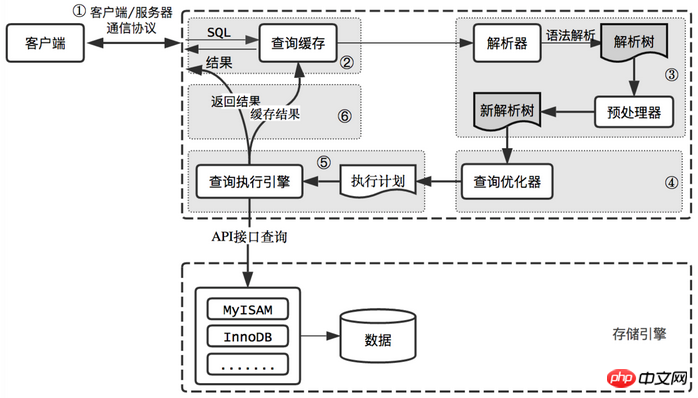
allowed_packet parameter needs to be set. However, it should be noted that if the query is too large, the server will refuse to receive more data and throw an exception.
On the contrary, the server responds to the user with usually a lot of data, consisting of multiple data packets. But when the server responds to the client's request, the client must receive the entire returned result completely, instead of simply taking the first few results and then asking the server to stop sending. Therefore, in actual development, it is a very good habit to keep queries as simple as possible and only return necessary data, and to reduce the size and number of data packets during communication. This is also the reason why we try to avoid using SELECT * and adding LIMIT restrictions in queries. one. Query CacheBefore parsing a query statement, if the query cache is turned on, MySQL will check whether the query statement hits the data in the query cache. If the current query happens to hit the query cache, the results in the cache will be returned directly after checking the user permissions once. In this case, the query will not be parsed, an execution plan will not be generated, and it will not be executed.
MySQL stores the cache in a reference table (do not understand it as a table, it can be thought of as similar to HashMap data structure), indexed by a hash value, which is calculated from the query itself, the database currently being queried, the client protocol version number, and other information that may affect the results. Therefore, any difference in characters between the two queries (for example: spaces, comments) will cause the cache to miss.
If the query contains any usercustom functions, stored functions, uservariables, temporary tables, and system tables in the mysql library, The query results
will not be cached. For example, the function NOW() or CURRENT_DATE() will return different query results due to different query times. Another example is that the query statement containing CURRENT_USER or CONNECION_ID() will return different query results due to different query times. It does not make any sense to cache such query results to return different results to different users.
Since it is a cache, it will expire. When will the query cache expire? MySQL's querycaching system will track each table involved in the query. If these tables (data or structure) change, then all cached data related to this table will be Invalid. Because of this, MySQL must invalidate all caches for the corresponding table during any write operation. If the query cache is very large or fragmented, this operation may cause a lot of system consumption and even cause the system to freeze for a while. Moreover, the additional consumption of the query cache on the system is not only for write operations, but also for read operations:
Any query statement must be checked before starting, even this SQL statement The cache will never be hit
If the query results can be cached, then after the execution is completed, the results will be stored in the cache, which will also cause additional system consumption
Based on this, we need to know that query caching will not improve system performance under all circumstances. Caching and invalidation will bring additional consumption. Only when the resource savings brought by caching are greater than the resources consumed by itself, can It will bring performance improvement to the system. However, it is very difficult to evaluate whether turning on the cache can bring about performance improvements, and it is beyond the scope of this article. If the system does have some performance problems, you can try to turn on the query cache and make some optimizations in the database design, such as:
Replace one large table with multiple small tables, be careful not to overdo it. Design
Batch insert insteadLoopSingle insert
Reasonably control the size of the cache space. Generally speaking, the size is set to Dozens of megabytes are more appropriate
You can use SQL_CACHE and SQL_NO_CACHE to control whether a certain query statement needs to be cached
The final advice is not to turn on the query cache easily, especially for write-intensive applications. If you really can't help it, you can set query_cache_type to DEMAND. At this time, only queries that add SQL_CACHE will be cached, and other queries will not. This allows you to freely control which queries need to be cached.
Of course, the query cache system itself is very complex, and what is discussed here is only a small part. Other more in-depth topics, such as: How does the cache use memory? How to control memory fragmentation? Readers can read the relevant information on their own regarding the impact of transactions on query cache, etc. This is the place to start.
Grammar parsing and preprocessing
MySQL parses SQL statements through keywords and generates a corresponding parse tree. This process parser mainly verifies and parses through grammar rules. For example, whether the wrong keywords are used in SQL or whether the order of keywords is correct, etc. Preprocessing will further check whether the parse tree is legal according to MySQL rules. For example, check whether the data table and data column to be queried exist, etc.
Query Optimization
The syntax tree generated through the previous steps is considered legal and is converted into a query plan by the optimizer. In most cases, a query can be executed in many ways, and all will return corresponding results. The role of the optimizer is to find the best execution plan among them.
MySQL uses a cost-based optimizer, which tries to predict the cost of a query using a certain execution plan and selects the one with the smallest cost. In MySQL, you can get the cost of calculating the current query by querying the value of last_query_cost of the current session.
Mysql code
The results in the example indicate that the optimizer believes that it takes about 6391 random searches of data pages to complete the above query. This result is calculated based on some column statistics, which include: the number of pages in each table or index, the cardinality of the index, the length of the index and data rows, the distribution of the index, etc.
There are many reasons why MySQL may choose the wrong execution plan, such as inaccurate statistical information and failure to consider operating costs beyond its control (user-defined functions, stored procedures ), what MySQL thinks is optimal is different from what we think (we want the execution time to be as short as possible, but MySQL chooses the value it thinks the cost is small, but the small cost does not mean the execution time is short) and so on.
MySQL’s query optimizer is a very complex component that uses a lot of optimization strategies to generate an optimal execution plan:
dl
erAPI. Each table in the query process is represented by a handler instance. In fact, MySQL creates a handler instance for each table during the query optimization phase. The optimizer can obtain table-related information based on the interfaces of these instances, including all column names of the table, index statistics, etc. The storage engine interface provides very rich functions, but there are only dozens of interfaces at the bottom layer. These interfaces are like building blocks to complete most operations of a query. Return the results to the clientThe last stage of query execution is to return the results to the client. Even if the data cannot be queried, MySQL will still return relevant information about the query, such as the number of rows affected by the query and execution time, etc. If the query cache is turned on and the query can be cached, MySQL will also store the results in the cache. Returning the result set to the client is an incremental and gradual return process. It is possible that MySQL begins to gradually return the result set to the client when it generates the first result. In this way, the server does not need to store too many results and consume too much memory, and the client can also get the returned results as soon as possible. It should be noted that each row in the result set will be sent as a data packet that meets the communication protocol described in ①, and then transmitted through the TCP protocol. During the transmission process, MySQL data packets may be cached and then sent in batches.Let’s go back and summarize the entire query execution process of MySQL. Generally speaking, it is divided into 6 steps:
The client sends a query request to the MySQL server
The server first checks the query cache. If it hits the cache, it immediately returns the results stored in the cache. Otherwise, enter the next stage
The server performs SQL parsing and preprocessing, and then the optimizer generates the corresponding execution plan
MySQL based on the execution plan , call the API of the storage engine to execute the query
Return the results to the client, and cache the query results
Performance OptimizationSuggestions
After reading so much, you may expect some optimization methods. Yes, some optimization suggestions will be given below from 3 different aspects. But wait, there is another piece of advice to give you first: Don’t believe the “absolute truth” you see about optimization, including what is discussed in this article, but verify it through testing in actual business scenarios. Assumptions about execution plans and response times.
Scheme design and data type optimization
Just follow the principle of small and simple when choosing data types. Smaller data types are usually faster and take up less space. disk, memory, and requires fewer CPU cycles for processing. Simpler data types require fewer CPU cycles during calculations. For example, integers are cheaper than character operations, so integers are used to store IP addresses, DATETIME is used to store time, and Instead of using string.
Here are some tips that may be easy to understand and make mistakes:
Generally speaking, changing a NULL column to NOT NULL will not How much does it help with performance, except that if you plan to create an index on a column, you should set the column to NOT NULL.
It is useless to specify the width of integer type, such as INT(11). INT uses 16 as storage space, so its representation range has been determined, so INT(1) and INT(20) are the same for storage and calculation.
UNSIGNED means that negative values are not allowed, which can roughly double the upper limit of positive numbers. For example, the storage range of TINYINT is generally speaking, and there is no need to use the DECIMAL data type. Even when you need to store financial data, you can still use BIGINT. For example, if you need to be accurate to one ten thousandth, you can multiply the data by one million and use TIMESTAMP to use 4 bytes of storage space, and DATETIME to use 8 bytes of storage space. Therefore, TIMESTAMP can only represent 1970 - 2038, which is a much smaller range than DATETIME, and the value of TIMESTAMP varies depending on the time zone.
In most cases there is no need to use enumerated types. One of the disadvantages is that the enumerated string list is fixed, adding and deleting strings ( Enumeration options) ALTER TABLE must be used (if you are just appending elements to the end of the list, you do not need to rebuild the table).
Don’t have too many schema columns. The reason is that when the storage engine API works, it needs to copy the data in the row buffer format between the server layer and the storage engine layer, and then decode the buffer content into each column at the server layer. The cost of this conversion process is very high. If there are too many columns and few columns are actually used, it may cause high CPU usage.
ALTER TABLE for large tables is very time-consuming. MySQL performs most Modify tableresult operations by creating an empty table with a new structure and querying it from the old table. Insert all the data into the new table and then delete the old table. Especially when there is insufficient memory and the table is large and there are large indexes, it will take longer. Of course, there are some weird and obscene techniques that can solve this problem. If you are interested, you can check them out on your own.
Creating high-performance indexes
Indexes are an important way to improve MySQL query performance, but too many indexes may lead to excessive disk usage and excessive memory usage, thereby affecting the overall performance of the application. You should try to avoid adding indexes afterward, because you may need to monitor a large amount of SQL to locate the problem afterwards, and the time to add an index is definitely much longer than the time required to initially add an index. It can be seen that adding an index is also very technical. .
The following will show you a series of strategies for creating high-performance indexes, and the working principles behind each strategy. But before that, understanding some algorithms and data structures related to indexing will help you better understand the following content.
Index-related data structures and algorithms
Usually what we call the index refers to the B-Tree index, which is currently the most commonly used and effective index for finding data in relational databases. Most storage engines support this index. The term B-Tree is used because MySQL uses this keyword in CREATE TABLE or other statements, but in fact different storage engines may use different data structures. For example, InnoDB uses B+ Tree.
The B in B+Tree refers to balance, which means balance. It should be noted that the B+ tree index cannot find a specific row with a given key value. It only finds the page where the data row being searched is located. Then the database will read the page into the memory, then search it in the memory, and finally Get the data you are looking for.
Before introducing B+Tree, let’s first understand the binary search tree. It is a classic data structure. The value of its left subtree is always less than the value of the root. The value of the subtree is always greater than the value of the root, as shown in the figure ① below. If you want to find a record with a value of 5 in this lesson tree, the general process is: first find the root, whose value is 6, which is greater than 5, so search the left subtree and find 3, and 5 is greater than 3, then find the right subtree of 3 Tree, I found it 3 times in total. In the same way, if you search for a record with a value of 8, you also need to search 3 times. Therefore, the average number of searches in the binary search tree is (3 + 3 + 3 + 2 + 2 + 1) / 6 = 2.3 times. If you search sequentially, you only need 1 time to find the record with value 2, but the search value is 8 records require 6 times, so the average number of searches for sequential search is: (1 + 2 + 3 + 4 + 5 + 6) / 6 = 3.3 times, because in most cases the average search speed of a binary search tree is Sequential search is faster.
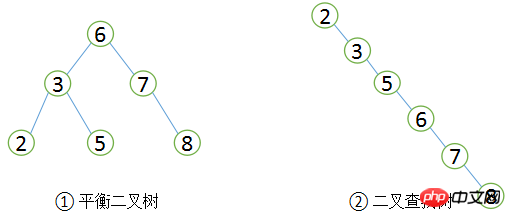
Binary search tree and balanced binary tree
Due to binary search The tree can be constructed arbitrarily. With the same value, a binary search tree as shown in Figure 2 can be constructed. Obviously, the query efficiency of this binary tree is similar to that of sequential search. If you want the query performance of binary search numbers to be the highest, you need this binary search tree to be balanced, that is, a balanced binary tree (AVL tree).
A balanced binary tree first needs to conform to the definition of a binary search tree, and secondly it must satisfy that the height difference between the two subtrees of any node cannot be greater than 1. Obviously Figure ② does not meet the definition of a balanced binary tree, while Figure ① is a balanced binary tree. The search performance of a balanced binary tree is relatively high (the best binary tree has the best performance). The better the query performance, the greater the maintenance cost. For example, in the balanced binary tree in Figure 1, when the user needs to insert a new node with a value of 9, the following changes need to be made.
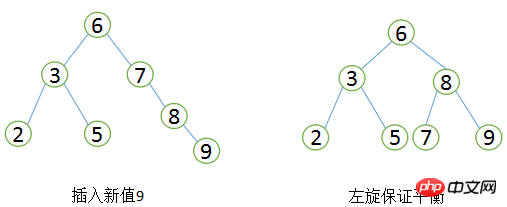
Balanced Binary Tree Rotation
After insertion, the It is the simplest case to transform the tree into a balanced binary tree. In actual application scenarios, it may need to be rotated multiple times. At this point we can consider a question. The search efficiency of balanced binary trees is quite good, the implementation is very simple, and the corresponding maintenance costs are acceptable. Why doesn't MySQL Index directly use balanced binary trees?
As the data in the database increases, the size of the index itself increases, and it is impossible to store it all in memory, so the index is often stored on disk in the form of an index file. In this case, disk I/O consumption will be incurred during the index search process. Compared with memory access, the consumption of I/O access is several orders of magnitude higher. Can you imagine the depth of a binary tree with millions of nodes? If a binary tree with such a large depth is placed on a disk, each time a node is read, an I/O read from the disk is required, and the entire search time is obviously unacceptable. So how to reduce the number of I/O accesses during the search process?
An effective solution is to reduce the depth of the tree and change the binary tree into an m-ary tree (multi-way search tree), while B+Tree It is a multi-way search tree. When understanding B+Tree, you only need to understand its two most important features: First, all keywords (can be understood as data) are stored in leaf nodes (Leaf Page), and non-leaf nodes (Index Page) are not No real data is stored, and all record nodes are stored on the same layer of leaf nodes in order of key value. Secondly, all leaf nodes are connected by pointers. The picture below shows a simplified B+Tree with a height of 2.
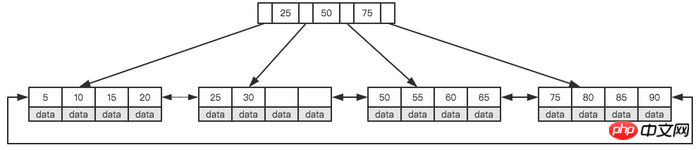
Simplified B+Tree
How to understand these two characteristics? MySQL sets the size of each node to an integer multiple of a page (the reasons will be introduced below), that is, when the node space size is certain, each node can store more internal nodes, so that each node can The range of the index is larger and more precise. The advantage of using pointer links for all leaf nodes is that interval access is possible. For example, in the figure above, if you are looking for records greater than 20 and less than 30, you only need to find node 20, and you can traverse the pointers to find 25 and 30 in sequence. If there is no link pointer, interval search cannot be performed. This is also an important reason why MySQL uses B+Tree as the index storage structure.
Why MySQL sets the node size to an integer multiple of the page, this requires understanding the storage principle of the disk. The access speed of the disk itself is much slower than that of the main memory. In addition to the mechanical movement loss (especially ordinary mechanical hard disks), the access speed of the disk is often one millionth of that of the main memory. In order to minimize disk I/O , the disk is often not read strictly on demand, but will be read in advance every time. Even if only one byte is needed, the disk will start from this position, sequentially read a certain length of data backwards and put it into the memory. The length of the pre-read Generally an integer multiple of pages.
Quote
A page is a logical block of computer management memory. Hardware and OS often divide the main memory and disk storage area into consecutive blocks of equal size. Each storage block is called a page. (In many OS, the page size is usually 4K). Main memory and disk exchange data in units of pages. When the data to be read by the program is not in the main memory, a page fault exception will be triggered. At this time, the system will send a read signal to the disk, and the disk will find the starting position of the data and read one or more pages backwards. Load into memory, then return abnormally, and the program continues to run.
MySQL cleverly uses the principle of disk read-ahead to set the size of a node equal to one page, so that each node can be fully loaded with only one I/O. In order to achieve this goal, each time a new node is created, a page of space is directly applied for. This ensures that a node is physically stored in a page. In addition, the computer storage allocation is page-aligned, thus realizing the reading of a node. Only one I/O is required. Assuming that the height of B+Tree is h, a retrieval requires at most h-1I/O (root node resident memory), and the complexity $O(h) = O(\log_{M}N)$. In actual application scenarios, M is usually large, often exceeding 100, so the height of the tree is generally small, usually no more than 3.
Finally, let’s briefly understand the operation of the B+Tree node, and have a general understanding of the maintenance of the index as a whole. Although the index can greatly improve the query efficiency, it still costs money to maintain the index. The cost is very high, so it is particularly important to create indexes reasonably.
Still taking the above tree as an example, we assume that each node can only store 4 internal nodes. First, insert the first node 28, as shown in the figure below.
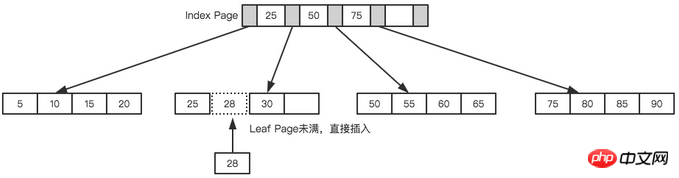
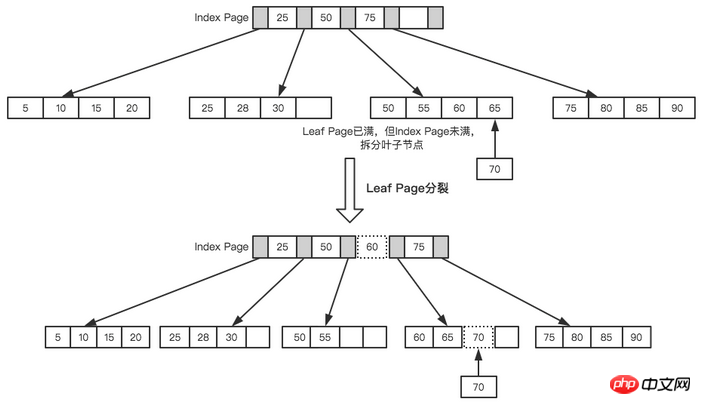
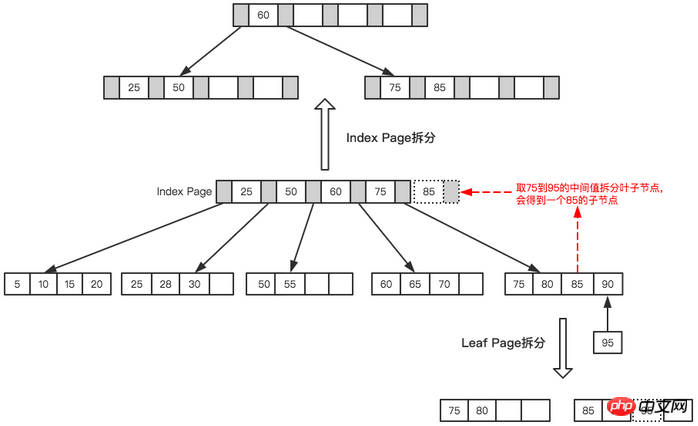
##Leaf Page and Index Page split
The final result after splitting Such a tree was formed.
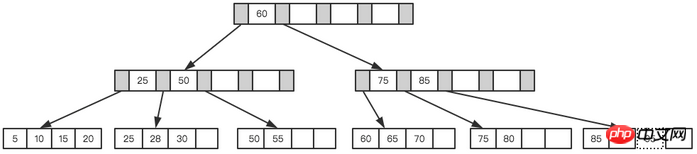
Final Tree
B+Tree In order to maintain balance, for the new The inserted value requires a lot of splitting
pagingoperations, and page splitting requires I/O operations. In order to reduce page splitting operations as much as possible, B+Tree also provides a balanced binary tree. Rotation function. When LeafPage is full but its left and right sibling nodes are not full, B+Tree is not eager to do the split operation, but moves the record to the sibling nodes of the current page. Normally, the left sibling is checked first for rotation operations. For example, in the second example above, when 70 is inserted, page splitting will not be performed, but a left-turn operation will be performed.
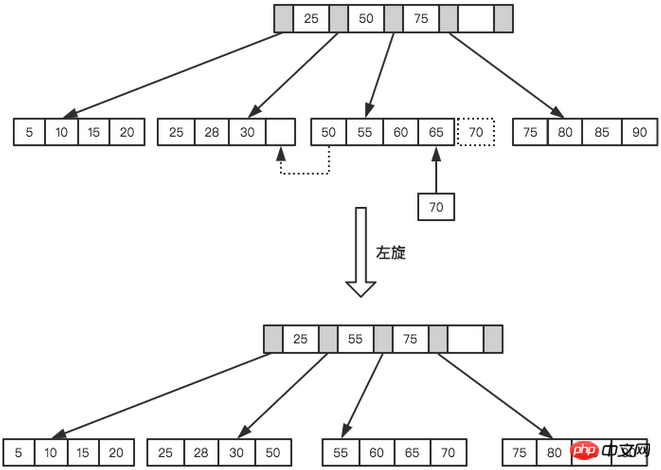
Left-rotation operation
The rotation operation can minimize the number of pages Split, thereby reducing disk I/O operations during index maintenance and improving index maintenance efficiency. It should be noted that deleting nodes and inserting node types still require rotation and splitting operations, which will not be explained here.
High Performance Strategy
Through the above, I believe you already have a general understanding of the data structure of B+Tree, but how does the index in MySQL organize the storage of data? To illustrate with a simple example, if there is the following data table:
Mysql code
CREATE TABLE People(
last_name varchar(50) not null,
For each row of data in the table, the index contains the values of the last_name, first_name, and dob columns, as follows Figure shows how indexes organize data storage.

How indexes organize data storage, from: High Performance MySQL
As you can see, the index is first sorted according to the first field. When the names are the same, it is sorted according to the third field, which is the date of birth. It is for this reason that the "leftmost principle" of the index is established.
1. MySQL will not use the index: non-independent columns
"Independent columns" means that the index column cannot be an
expression## Part of # cannot be the parameterof the function. For example: Mysql code
select * from where id + 1 = 5Using functions
is the same. 2. Prefix index If the column is very long, you can usually index some of the characters at the beginning, which can effectively save index space and improve index efficiency. 3. Multi-column indexes and index orderIn most cases, establishing independent indexes on multiple columns does not improve query performance. The reason is very simple. MySQL does not know which index to choose for better query efficiency, so in older versions, such as before MySQL 5.0, it would randomly choose an index for a column, while new versions will adopt a merged index strategy. To give a simple example, in a movie cast list, independent indexes are established on the actor_id and film_id columns, and then there is the following query: Mysql code select film_id,actor_id from film_actor where actor_id = 1 or film_id = 1When multiple indexes intersect (multiple AND conditions), generally speaking, an index containing all related columns is better than multiple independent indexes.
When multiple indexes are used for joint operations (multiple OR conditions), operations such as merging and sorting the result set require a large amount of CPU and memory resources, especially when Some indexes are not very selective, and when a large amount of data needs to be returned and merged, the query cost is higher. So in this case it is better to perform a full table scan.
Therefore, if you find that there is an index merge (Using union appears in the Extra field) when explaining, you should check whether the query and table structure are already optimal. If neither the query nor the table are optimal, problem, it only shows that the index is very poorly built, and you should carefully consider whether the index is suitable. It is possible that a multi-column index containing all relevant columns is more suitable.
We mentioned earlier how indexes organize data storage. As you can see from the figure, when a multi-column index is used, the order of the index is crucial to the query. It is obvious that it should be The more selective fields are placed at the front of the index, so that most of the data that does not meet the conditions can be filtered out through the first field.
Quote
Index selectivity refers to the ratio of unique index values to the total number of records in the data table. The higher the selectivity, the higher the query efficiency, because the higher the selectivity of the index, the more selective the index can allow MySQL to filter out more when querying. OK. The selectivity of the unique index is 1. At this time, the index selectivity is the best and the performance is the best.
After understanding the concept of index selectivity, it is not difficult to determine which field has higher selectivity. Just check it, for example:
Mysql code
SELECT * FROM payment where staff_id = 2 and customer_id = 584
should be created Should the index of (staff_id, customer_id) be reversed? Execute the following query, whichever field's selectivity is closer to 1 will be indexed first.
Mysql code
select count(distinct staff_id)/count(*) as staff_id_selectivity,
Count(distinct customer_id)/count(*) as customer_id_selectivity,
count(*) from payment
In most cases there is no problem using this principle, but still pay attention to whether there are some special cases in your data. To give a simple example, for example, if you want to query the information of users who have traded under a certain user group:
Mysql code
select user_id from trade where user_group_id = 1 and trade_amount > 0
MySQL selected the index (user_group_id, trade_amount) for this query. If special circumstances are not considered, this does not seem to have any problems, but in fact The situation is that most of the data in this table was migrated from the old system. Since the data of the new and old systems are incompatible, a default user group is assigned to the data migrated from the old system. In this case, the number of rows scanned through the index is basically the same as that of the full table scan, and the index will not play any role.
Broadly speaking, rules of thumb and inference are useful in most cases and can guide our development and design, but the actual situation is often more complicated. Some special circumstances may destroy your entire design.
4. Avoid multiple range conditions
In actual development, we will often use multiple range conditions, for example, if we want to query the users who have logged in within a certain period of time :
Mys code
Only when the column order of the index is completely consistent with the order of the ORDER BY clause, and the sorting direction of all columns is also the same, the index can be used to sort the results. If the query needs to associate multiple tables, the index can be used for sorting only if all the fields referenced by the ORDER BY clause are from the first table. The restrictions of the ORDER BY clause and the query are the same, and they must meet the requirements of the leftmost prefix (there is one exception, that is, the leftmost column is specified as a constant. The following is a simple example). In other cases, it needs to be executed. Sorting operations, and index sorting cannot be used.
Mysql code
// The leftmost column is a constant, index: (date, staff_id, customer_id)
select staff_id,customer_id from demo where date = '2015-06-01' order by staff_id,customer_id
redis.
Optimizing related queriesIn big data scenarios, tables are related through a redundant field, which has better performance than using JOIN directly. . If you really need to use related queries, you need to pay special attention to:To understand the first technique of optimizing related queries, you need to understand how MySQL performs related queries. The current MySQL association execution strategy is very simple. It performs nested loop association operations for any association, that is, it first loops out a single piece of data in one table, and then searches for matching rows in the next table in the nested loop, and so on. , until matching rows are found in all tables. Then, based on the matching rows of each table, the columns required in the query are returned.
Too abstract? Take the above example to illustrate, for example, there is such a query:
Mysql code
SELECT A.xx,B.yy
FROM A INNER JOIN B USING(c)
Assuming that MySQL performs association operations according to the association order A and B in the query, then the following pseudo code can be used to indicate how MySQL completes this query:
Mysql code
## inner_iterator = SELECT B.yy FROM B WHERE B.c = outer_row.c;
002
0 records and then Only 20 records will be returned, and the first 10,000 records will be discarded. This cost is very high.If this table is very large, then it is best to change this query to the following:
Mysql code##SELECT film.film_id, film.description
) AS tmp USING(film_id);
, such as the following query:
SELECT id FROM t WHERE id > 10000 LIMIT 10;
##
Other optimization methods include using pre-calculated summary tables, or linking to a redundant table, which only contains primary key columns and columns that need to be sorted.
Optimizing UNION
MySQL's strategy for processing UNION is to first create a temporary table, then insert each query result into the temporary table, and finally perform the query. Therefore, many optimization strategies do not work well in UNION query. It is often necessary to manually "push down" WHERE, LIMIT, ORDER BY and other clauses into each subquery so that the optimizer can make full use of these conditions to optimize first.
Unless you really need the server to deduplicate, you must use UNION ALL. If there is no ALL keyword, MySQL will add the DISTINCT option to the temporary table, which will cause the entire temporary table to be deduplicated. Data is checked for uniqueness, which is very expensive. Of course, even if the ALL keyword is used, MySQL always puts the results into a temporary table, then reads them out, and then returns them to the client. Although this is not necessary in many cases, for example, sometimes the results of each subquery can be returned directly to the client.
Conclusion
Understanding how queries are executed and where time is spent, coupled with some knowledge of the optimization process, can help everyone better understand MySQL. Understand the principles behind common optimization techniques. I hope that the principles and examples in this article can help you better connect theory and practice and apply more theoretical knowledge into practice.
There is not much else to say. I will leave you with two questions to think about. You can think about the answers in your head. This is something that everyone often talks about, but rarely Anyone wonder why?
Many programmers will throw out this point of view when sharing: try not touse stored procedures, stored procedures are very difficult to maintain, and will To increase usage costs, business logic should be placed on the client side. Since the client can do these things, why do we need stored procedures?
JOIN itself is also very convenient. Just query it directly. Why do you need a view?
[1] Written by Jiang Chengyao; MySQL Technology Insider-InnoDB Storage Engine; Machinery Industry Press , 2013
[2] Baron Scbwartz et al. Translated by Ninghai Yuanzhou Zhenxing and others; High Performance MySQL (Third Edition); Electronic Industry Press, 2013
[3] View MySQL index from B-/B+ tree structure
The above is the detailed content of MySQL optimization principles. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



