
 Backend Development
Python Tutorial
How to deal with sparse matrices? Python implementation of sparse matrix tutorial
Backend Development
Python Tutorial
How to deal with sparse matrices? Python implementation of sparse matrix tutorial
How to deal with sparse matrices? Python implementation of sparse matrix tutorial

This article mainly introduces the example code for implementing sparse matrix in python. The editor thinks it is quite good. Now I will share it with you and give it as a reference. Let’s follow the editor to take a look
In engineering practice, in most cases, large matrices are generally sparse matrices, so how to deal with sparse matrices is very important in practice. This article takes the implementation in Python as an example. First, let's explore how sparse matrices are stored and represented.
1. A preliminary study on the sparse module
In the scipy module in python, there is a module called the sparse module, which is specifically designed to solve sparse matrices. Most of the content of this article is actually based on the sparse module.
The first step is to import the sparse module
>>> from scipy import sparse
Then help, let’s take a look first
>>> help(sparse)
Find directly the part we are most concerned about:
Usage information
=================
There are seven available sparse matrix types:
1. csc_matrix: Compressed Sparse Column format
2. csr_matrix: Compressed Sparse Row format
3. bsr_matrix: Block Sparse Row format
4. lil_matrix: List of Lists format
5. dok_matrix: Dictionary of Keys format
6. coo_matrix: COOrdinate format (aka IJV, triplet format)
7. dia_matrix: DIAgonal format
To construct a matrix efficiently, use either dok_matrix or lil_matrix.
The lil_matrix class supports basic slicing and fancy
indexing with a similar syntax to NumPy arrays. As illustrated below,
the COO format may also be used to efficiently construct matrices.
To perform manipulations such as multiplication or inversion, first
convert the matrix to either CSC or CSR format. The lil_matrix format is
row-based, so conversion to CSR is efficient, whereas conversion to CSC
is less so.
All conversions among the CSR, CSC, and COO formats are efficient,
linear-time operations.Through this description, we have a general understanding of the sparse module. There are 7 ways to store sparse matrices in the sparse module. Next, we will introduce these 7 methods one by one.
2.coo_matrix
coo_matrix is the simplest storage method. Use three arrays row, col and data to store the information of non-zero elements. The three arrays have the same length, row holds the row of elements, col holds the column of elements, and data holds the value of the element. Generally speaking, coo_matrix is mainly used to create matrices, because coo_matrix cannot add, delete, or modify elements of the matrix. Once the matrix is successfully created, it will be converted into other forms of matrices.
>>> row = [2,2,3,2] >>> col = [3,4,2,3] >>> c = sparse.coo_matrix((data,(row,col)),shape=(5,6)) >>> print c.toarray() [[0 0 0 0 0 0] [0 0 0 0 0 0] [0 0 0 5 2 0] [0 0 3 0 0 0] [0 0 0 0 0 0]]
One thing to note is that when using coo_matrix to create a matrix, the same row and column coordinates can appear multiple times. After the matrix is actually created, the corresponding coordinate values will be added up to get the final result.
3.dok_matrix and lil_matrix
The scenario where dok_matrix and lil_matrix are applicable is to gradually add elements of the matrix. The strategy of doc_matrix is to use a dictionary to record the elements in the matrix that are not 0. Naturally, the key of the dictionary stores the ancestor of the position information of the recorded element, and the value is the specific value of the recorded element.
>>> import numpy as np >>> from scipy.sparse import dok_matrix >>> S = dok_matrix((5, 5), dtype=np.float32) >>> for i in range(5): ... for j in range(5): ... S[i, j] = i + j ... >>> print S.toarray() [[ 0. 1. 2. 3. 4.] [ 1. 2. 3. 4. 5.] [ 2. 3. 4. 5. 6.] [ 3. 4. 5. 6. 7.] [ 4. 5. 6. 7. 8.]]
lil_matrix uses two lists to store non-0 elements. data stores the non-zero elements in each row, and rows stores the columns in which the non-zero elements are located. This format is also great for adding elements one at a time and getting row-related data quickly.
>>> from scipy.sparse import lil_matrix >>> l = lil_matrix((6,5)) >>> l[2,3] = 1 >>> l[3,4] = 2 >>> l[3,2] = 3 >>> print l.toarray() [[ 0. 0. 0. 0. 0.] [ 0. 0. 0. 0. 0.] [ 0. 0. 0. 1. 0.] [ 0. 0. 3. 0. 2.] [ 0. 0. 0. 0. 0.] [ 0. 0. 0. 0. 0.]] >>> print l.data [[] [] [1.0] [3.0, 2.0] [] []] >>> print l.rows [[] [] [3] [2, 4] [] []]
It can be easily seen from the above analysis that the above two methods of constructing sparse matrices are generally used to construct matrices by gradually adding non-zero elements, and then convert them into other methods that can be quickly calculated. Matrix storage method.
4.dia_matrix
This is a diagonal storage method. Where columns represent diagonals and rows represent rows. If the elements on the diagonal are all 0, they are omitted.
If the original matrix is a diagonal matrix, the compression rate will be very high.
If I find a picture on the Internet, everyone can easily understand the principle.

5.csr_matrix and csc_matrix
csr_matrix, the full name is Compressed Sparse Row, is a row-based processing of matrices compressed. CSR requires three types of data: numerical values, column numbers, and row offsets. CSR is a coding method in which the meanings of numerical values and column numbers are consistent with those in coo. The row offset indicates the starting offset position of the first element of a row in values.
I also found a picture on the Internet that can better reflect the principle.
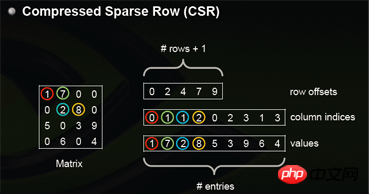
Let’s see how to use it in python: How about
>>> from scipy.sparse import csr_matrix
>>> indptr = np.array([0, 2, 3, 6])
>>> indices = np.array([0, 2, 2, 0, 1, 2])
>>> data = np.array([1, 2, 3, 4, 5, 6])
>>> csr_matrix((data, indices, indptr), shape=(3, 3)).toarray()
array([[1, 0, 2],
[0, 0, 3],
[4, 5, 6]]), is it not difficult to understand?
Let’s take a look at what the document says
Notes | ----- | | Sparse matrices can be used in arithmetic operations: they support | addition, subtraction, multiplication, pision, and matrix power. | | Advantages of the CSR format | - efficient arithmetic operations CSR + CSR, CSR * CSR, etc. | - efficient row slicing | - fast matrix vector products | | Disadvantages of the CSR format | - slow column slicing operations (consider CSC) | - changes to the sparsity structure are expensive (consider LIL or DOK)
It is not difficult to see that csr_matrix is more suitable for real matrix operations.
As for csc_matrix, it is similar to csr_matrix, but it is compressed based on columns and will not be introduced separately.
6.bsr_matrix
Block Sparse Row format, as the name suggests, compresses the matrix based on the idea of blocking.

The above is the detailed content of How to deal with sparse matrices? Python implementation of sparse matrix tutorial. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download deepseek Xiaomi
Feb 19, 2025 pm 05:27 PM
How to download DeepSeek Xiaomi? Search for "DeepSeek" in the Xiaomi App Store. If it is not found, continue to step 2. Identify your needs (search files, data analysis), and find the corresponding tools (such as file managers, data analysis software) that include DeepSeek functions.
 How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
How do you ask him deepseek
Feb 19, 2025 pm 04:42 PM
The key to using DeepSeek effectively is to ask questions clearly: express the questions directly and specifically. Provide specific details and background information. For complex inquiries, multiple angles and refute opinions are included. Focus on specific aspects, such as performance bottlenecks in code. Keep a critical thinking about the answers you get and make judgments based on your expertise.
 How to search deepseek
Feb 19, 2025 pm 05:18 PM
How to search deepseek
Feb 19, 2025 pm 05:18 PM
Just use the search function that comes with DeepSeek. Its powerful semantic analysis algorithm can accurately understand the search intention and provide relevant information. However, for searches that are unpopular, latest information or problems that need to be considered, it is necessary to adjust keywords or use more specific descriptions, combine them with other real-time information sources, and understand that DeepSeek is just a tool that requires active, clear and refined search strategies.
 How to program deepseek
Feb 19, 2025 pm 05:36 PM
How to program deepseek
Feb 19, 2025 pm 05:36 PM
DeepSeek is not a programming language, but a deep search concept. Implementing DeepSeek requires selection based on existing languages. For different application scenarios, it is necessary to choose the appropriate language and algorithms, and combine machine learning technology. Code quality, maintainability, and testing are crucial. Only by choosing the right programming language, algorithms and tools according to your needs and writing high-quality code can DeepSeek be successfully implemented.
 How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
How to use deepseek to settle accounts
Feb 19, 2025 pm 04:36 PM
Question: Is DeepSeek available for accounting? Answer: No, it is a data mining and analysis tool that can be used to analyze financial data, but it does not have the accounting record and report generation functions of accounting software. Using DeepSeek to analyze financial data requires writing code to process data with knowledge of data structures, algorithms, and DeepSeek APIs to consider potential problems (e.g. programming knowledge, learning curves, data quality)
 How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
How to access DeepSeekapi - DeepSeekapi access call tutorial
Mar 12, 2025 pm 12:24 PM
Detailed explanation of DeepSeekAPI access and call: Quick Start Guide This article will guide you in detail how to access and call DeepSeekAPI, helping you easily use powerful AI models. Step 1: Get the API key to access the DeepSeek official website and click on the "Open Platform" in the upper right corner. You will get a certain number of free tokens (used to measure API usage). In the menu on the left, click "APIKeys" and then click "Create APIkey". Name your APIkey (for example, "test") and copy the generated key right away. Be sure to save this key properly, as it will only be displayed once
 Major update of Pi Coin: Pi Bank is coming!
Mar 03, 2025 pm 06:18 PM
Major update of Pi Coin: Pi Bank is coming!
Mar 03, 2025 pm 06:18 PM
PiNetwork is about to launch PiBank, a revolutionary mobile banking platform! PiNetwork today released a major update on Elmahrosa (Face) PIMISRBank, referred to as PiBank, which perfectly integrates traditional banking services with PiNetwork cryptocurrency functions to realize the atomic exchange of fiat currencies and cryptocurrencies (supports the swap between fiat currencies such as the US dollar, euro, and Indonesian rupiah with cryptocurrencies such as PiCoin, USDT, and USDC). What is the charm of PiBank? Let's find out! PiBank's main functions: One-stop management of bank accounts and cryptocurrency assets. Support real-time transactions and adopt biospecies
 What are the current AI slicing tools?
Nov 29, 2024 am 10:40 AM
What are the current AI slicing tools?
Nov 29, 2024 am 10:40 AM
Here are some popular AI slicing tools: TensorFlow DataSetPyTorch DataLoaderDaskCuPyscikit-imageOpenCVKeras ImageDataGenerator
