

In order to understand how Node.js works, first you need to Understand some of the key features that make Javascript suitable for server-side development. Javascript is a simple yet flexible language, and this flexibility allows it to stand the test of time. Features such as functions and closures make Javascript an ideal language for web development.
There is a prejudice that Javascript is unreliable, but this is not the case. People's prejudice against Javascript comes from DOM. DOM is an API provided by browser manufacturers for Javascript to interact with browsers. There are differences in the DOM implemented by different browser manufacturers. However, Javascript itself is a well-defined language that can run in different browsers and Node.js. In this section, I will first introduce some basics of Javascript and how Node.js uses Javascript to provide a web development platform with excellent performance.
Javascript uses the var keyword to define variables. For example, the following code creates a variable named foo and outputs it on the command line. (The following code file can be executed on the command line through node variable.js.)
var foo = 123;console.log(foo); // 123
Javascript run The environment (browser or Node.js) usually defines some global variables that we can use, such as the console object. The console object contains a member function log, logThe function can accept any number of parameters and output them. We will encounter more global objects next, and you will find that Javascript has most of the features that a good programming language should contain.
Javascript supports common arithmetic operators (+, -, *, /, %). For example, the following code:
var foo = 3; var bar = 5; console.log(foo+1); //4 console.log(foo / bar); //0.6 console.log(foo * bar); //15 console.log(foo - bar); //-2 console.log(foo % 2); //取余:1
Boolean values include true and false. You can assign a variable a value of true or false and perform Boolean operations on it. For example, the following code:
var foo = true; console.log(foo); //true//常见的布尔操作符号: &&,||, ! console.log(true && true); //true console.log(true && false); /false console.log(true || false); //true console.log(false || false); //false console.log(!true); //false console.log(!false); //true
In Javascript, we can create an array through []. Array objects contain many useful functions, as shown in the following code:
var foo = []; foo.push(1); //添加到数组末尾 console.log(foo); // [1] foo.unshift(2); //添加到数组头部 console.log(foo); // [2, 1]//数组起始位置从0开始 console.log(foo[0]); // 2
Object literal{} is usually used in Javascript to create objects, such as the following The code is shown:
var foo = {};
console.log(foo); // {}
foo.bar = 123;
console.log(foo); // {bar: 123}The above code adds object properties at runtime. We can also define object properties when creating an object:
var foo = { bar: 123
};
console.log(foo); // {bar: 123}Object literals can be nested with other object literals. , for example, as shown in the following code:
var foo = {
bar: 123,
bas: {
bas1: 'some string',
bas2: 345
}
};
console.log(foo);Of course, object literals can also contain arrays:
var foo = { bar: 123, bas: [1,2,3]
};
console.log(foo);Arrays can also contain object literals:
var foo = { bar: 123, bas: [{ qux: 1
},
{ qux: 2
},
{ qux: 3
}]
};
console.log(foo.bar); //123
console.log(foo.bas[0].qux); // 1
console.log(foo.bas[2].qux); // 2Javascript functions are very powerful. We will gradually understand it through a series of examples.
The usual Javascript function structure is as follows:
function functionName(){ //函数体
}All functions of Javascript have return values. Without an explicit return statement, the function returns undefined. For example, the following code is shown:
function foo(){return 123;}console.log(foo); // 123function bar(){ }console.log(bar()); // undefinedWe execute the function immediately after defining it, wrap and call the function through brackets (). As shown in the following code:
(function foo(){
console.log('foo was executed!');
})();The reason why the immediate execution function appears is to create a new variable scope. if, else, while will not create a new variable scope, as shown in the following code:
var foo = 123;if(true){ var foo = 456;
}console.log(foo); // 456In Javascript, we Create a new variable scope through a function, such as using an immediate execution function:
var foo = 123;if(true){
(function(){ var foo = 456;
})();
}console.log(foo); // 123In the above code, we did not name the function, which is called an anonymous function.
A function without a name is called an anonymous function. In Javascript, we can assign functions to variables. If we plan to use the function as a variable, we do not need to name the function. Two equivalent ways of writing are given below:
var foo1 = function nameFunction(){ console.log('foo1');
}
foo1(); // foo1var foo2 = function(){ console.log('foo2');
}
foo2(); // foo2fIt is said that if a programming language can treat functions as variables, it is an excellent programming language, and Javascript has achieved this.
Since Javascript allows us to assign functions to variables, we can pass functions as parameters to other functions. Functions that take functions as arguments are called higher-order functions. setTimeout is a common high-order function.
setTimeout(function(){console.log('2000 milliseconds have passed since this demo started');
}, 2000);If you run the above code in Node.js, you will see the command window outputting information after 2 seconds. In the above code, we passed an anonymous function as the first parameter of setTimeout. We can also pass a normal function:
function foo(){ console.log('2000 milliseconds have passed since this demo started');
}
setTimeout(foo, 200);Now that we have understood object literals and functions, we will understand the concept of closures.
A closure is a function that can access the internal variables of other functions. If you define another function inside a function, the inner function can access the variables of the outer function. This is a common form of closure. We'll explain with some examples.
In the code below, you can see that the inner function is able to access the variables of the outer function:
function outerFunction(arg){ var variableInOuterFunction = arg; function bar(){console.log(variableInOuterFunction);
}
bar();
}
outerFunction('hello closure!'); // hello closure!令人惊喜的是:内部函数在外部函数返回之后依然可以访问外部函数作用域中的变量。这是因为,变量仍然被绑定于内部函数,不依赖于外部函数。例如:
function outerFunction(arg){ var variableInOuterFunction = arg; return function(){console.log(variableInOuterFunction);
}
}var innerFunction = outerFunction('hello closure!');
innerFunction(); // hello closure!现在,我们已经了解了闭包,接下来,我们会探究一下使Javascript成为一门适合服务器端编程的语言的原因。
Node.js致力于开发高性能应用程序。接下来的部分,我们会介绍大规模I/O问题,并分别展示传统方式及Node.js是如何解决这个问题的。
大多数Web应用通过硬盘或者网络(例如查询另一台机器的数据库)获取数据,从硬盘或网络获取数据的速度远远慢于CPU的处理周期。当收到一个HTTP请求以后,我们需要从数据库获取数据,请求会一直等待直到获取数据完成。这些创建的连接和还未结束的请求会消耗服务器的资源(内存和CPU)。为了使同一台Web服务器能够处理大规模请求,我们需要解决大规模I/O问题。
传统的Web服务器为每一个请求创建一个新的进程,这是一种对内存和CPU开销都很昂贵的操作。PHP最开始就是采用的这种方法。在等待响应期间,进程仍然会消耗资源,并且进程的创建更慢。所以现代Web应用大多使用线程池的方法。
现代Web服务器使用线程池来处理每个请求。线程和进程相比,更加轻量级。在创建线程池以后,我们就不再需要为开始或结束进程而付出额外代价。当收到一个请求,我们为它分配一个线程。然而,线程池仍然会浪费一些资源。
我们知道为请求分别创建进程或者线程会导致系统资源浪费。与之相对,Node.js采取了单线程来处理请求。单线程服务器的性能优于线程池服务器的理念并不是Node.js首创,Nginx也是基于这种理念。Nginx是一种单线程服务器,能够处理极大数量的并发请求。
Javascript是单线程的,如果你有一个耗时操作(例如网络请求),就必须使用回调。下面的代码使用setTimeout模拟了一个耗时操作,可以用Node.js执行。
function longRunningOperation(callback){
setTimeout(callback, 3000);
}function UserClicked(){ console.log('starting a long operation');
longRunningOperation(function(){ console.log('ending a long operation');
})
}
UserClicked();让我们模拟一下Web请求:
function longRunningOperation(callback){
setTimeout(callback, 3000);
}function webRequest(request){ console.log('starting a long operation for request:', request.id);
longRunningOperation(function(){console.log('ending a long operation for request:', request.id);
});
}
webRequest({id: 1});
webRequest({id: 2});
//输出
//starting a long operation for request: 1//starting a long operation for request: 2//ending a long operation for request: 1//ending a long operation for request: 2Node.js的核心是一个event loop。event loop使得任何用户图形界面应用程序可以在任何操作系统中工作。当事件被触发时(例如:用户点击鼠标),操作系统调用程序的某个函数,程序执行函数中的代码。之后,程序准备响应已经在队列中的事件或尚未出现的事件。
通常,在GUI程序中,当由一个事件调用的函数执行期间,其它事件不会被处理。因此,当你在相关函数中执行耗时操作时,GUI会变得无响应。这种CPU资源的短缺被成为饥饿。
Node.js基于和GUI应用程序相同的event loop原则。因此,它也会面临饥饿的问题。为了帮助更好的理解,我们通过几个例子来说明:
console.time('timer');
setTimeout(function(){ console.timeEnd('timer'); //timer: 1002.615ms
}, 1000)运行这段代码,与我们期望的相同,终端显示的数字在1000ms左右。
接下来我们想写一段耗时更长的代码,例如一个未经优化的计算Fibonacci数列的方法:
console.time('timeit');function fibonacci(n){ if(n<2){return 1;
}else{return fibonacci(n-2) + fibonacci(n-1);
}
}
fibonacci(44);console.timeEnd('timeit'); //我的电脑耗时 11863.331ms,每台电脑会有差异现在我们可以模拟Node.js的线程饥饿。setTimeout用于在指定的时间以后调用函数,如果我们在函数调用以前,执行一个耗时方法,由于耗时方法占用CPU和Javascript线程,setTimeout指定的函数无法被及时调用,只能等待耗时方法运行结束以后被调用。例如下面的代码:
function fibonacci(n){ if(n<2){return 1;
}else{return fibonacci(n-2) + fibonacci(n-1);
}
}console.time('timer');
setTimeout(function(){ console.timeEnd('timer'); // 输出时间会大于 1000ms
}, 1000)
fibonacci(44);所以,如果你面临CPU密集型场景,Node.js并不是最佳选择,但也很难找到其它合适的平台。但是Node.js非常适用于I/O密集型场景。
Node.js适用于I/O密集型。单线程机制意味着Node.js作为Web服务器会占用更少的内存,能够支持更多的请求。与执行代码相比,从数据库获取数据需要花费更多的时间。下图展示了传统的线程池模型的服务器是如何处理用户请求的:

Node.js服务器处理请求的方式如下图。因为所有的工作都在单线程内完成,所以消耗更少的内存,同时因为不需要切换线程,所以CPU负载更小。
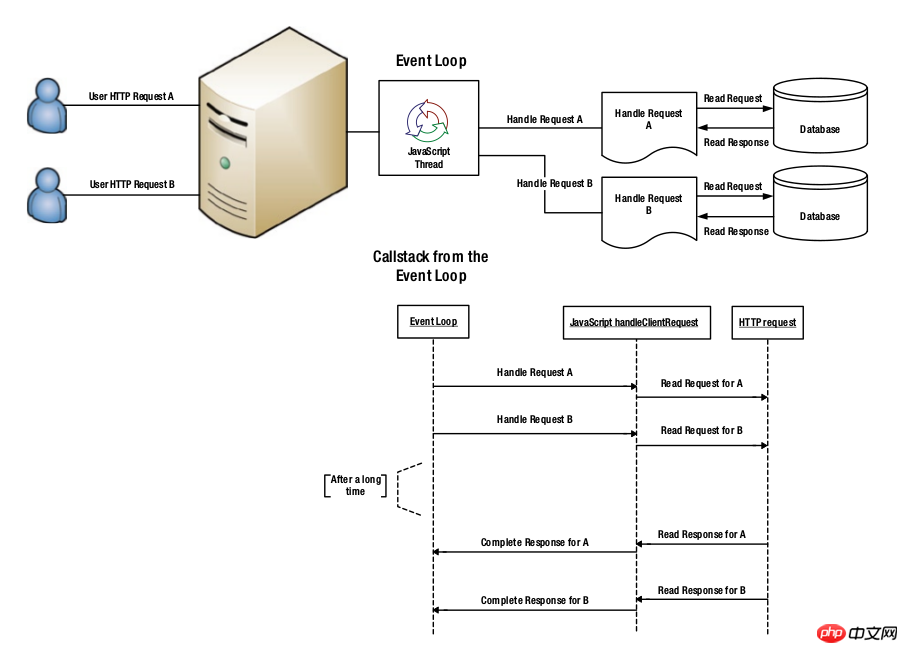
Node.js中的所有Javascript通过V8 Javascript引擎执行。V8产生于谷歌Chrome项目,V8在Chrome中用于运行Javascript。V8不仅速度更快,而且很容易被集成到其它项目。
精通Javascript使得Node.js开发者不仅能够写出更加容易维护的项目,而且能够利用到Javascript生态链的优势。
Javascript变量的默认值是undefined。如下列代码所示:
var foo;console.log(foo); //undefined
变量不存在的属性也会返回undefined
var foo = {bar: 123};
console.log(foo.bar); // 123
console.log(foo.bas); // undefined需要注意Javascript当中 ==与===的区别。==会对变量进行类型转换,===不会。推荐的用法是总是使用===。
console.log(5 == '5'); // true console.log(5 === '5'); // false
null是一个特殊的Javascript对象,用于表示空对象。而undefined用于表示变量不存在或未初始化。我们不需要给变量赋值为undefined,因为undefined是变量的默认值。
透露模块模式的关键在于Javascript对闭包的支持以及能够返回任意对象的能力。如下列代码所示:
function printableMessage(){ var message = 'hello'; function setMessage(newMessage){if(!newMessage) throw new Error('cannot set empty message');
message = newMessage;
} function getMessage(){return message;
} function printMessage(){
console.log(message);
} return {
setMessage: setMessage,
getMessage: getMessage,
printMessage: printMessage
};
}var awesome1 = printableMessage();
awesome1.printMessage(); //hellovar awesome2 = printableMessage();
awesome2.setMessage('hi');
awesome2.printMessage(); // hi
awesome1.printMessage(); //hellothisthis总是指向调用函数的对象。例如:
var foo = { bar: 123, bas: function(){console.log('inside this.bar is: ', this.bar);
}
}console.log('foo.bar is:', foo.bar); //foo.bar is: 123
foo.bas(); //inside this.bar is: 123由于函数bas被foo对象调用,所以this指向foo。如果是纯粹的函数调用,则this指向全局变量。例如:
function foo(){ console.log('is this called from globals? : ', this === global); //true
}
foo();如果我们在浏览器中执行上面的代码,全局变量global会变为window。
如果函数的调用对象改变,this的指向也会改变:
var foo = { bar: 123
};function bas(){ if(this === global){console.log('called from global');
} if(this === foo){console.log('called from foo');
}
}//指向global
bas(); //called from global//指向foo
foo.bas = bas;
foo.bas(); //called from foo如果通过new操作符调用函数,函数内的this会指向由new创建的对象。
function foo(){ this.foo = 123;
console.log('Is this global? : ', this == global);
}
foo(); // Is this global? : true
console.log(global.foo); //123var newFoo = new foo(); //Is this glocal ? : false
console.log(newFoo.foo); //123通过上面代码,我们可以看到,在通过new调用函数时,函数内的this指向发生改变。
Javascript通过new操作符及原型属性可以模仿面向对象的语言。每个Javascript对象都有一个被称为原型的内部链接指向其他对象。
当我们调用一个对象的属性,例如:foo.bar,Javascript会检查foo对象是否存在bar属性,如果不存在,Javascript会检查bar属性是否存在于foo._proto_,以此类推,直到对象不存在_proto_。如果在任何层级发现属性的值,则立即返回,否则,返回undefined。
var foo ={};
foo._proto_.bar = 123;
console.log(foo.bar); //123当我们通过new操作符创建对象时,对象的_proto_会被赋值为函数的prototype属性,例如:
function foo(){};
foo.prototype.bar = 123;var bas = new foo();console.log(bas._proto_ === foo.prototype); //trueconsole.log(bas.bar);函数的所有实例共享相同的prototype
function foo(){};
foo.prototype.bar = 123;
var bas = new foo();
var qux = new foo();
console.log(bas.bar); //123
console.log(qux.bar); //123
foo.prototype.bar = 456;
console.log(bas.bar); //456
console.log(qux.bar); //456只有当属性不存在时,才会访问原型,如果属性存在,则不会访问原型。
function foo(){};
foo.prototype.bar = 123;var bas = new foo();var qux = new foo();
bas.bar = 456;console.log(bas.bar);//456console.log(qux.bar); //123上面的代码表明,如果修改了bas.bar, bas._proto_.bar就不再被访问。
Javascript的异常处理机制类似其它语言,通过throw关键字抛出异常,通过catch关键字捕获异常。例如:
try{
console.log('About to throw an error'); throw new Error('Error thrown');
}
catch(e){
console.log('I will only execute if an error is thrown');
console.log('Error caught: ', e.message);
}finally{
console.log('I will execute irrespective of an error thrown');
}本章,我们介绍了一些Node.js及Javascript的重要概念,知道了Node.js适用于开发数据密集型应用程序。下章我们将开始介绍如何使用Node.js开发应用程序。
The above is the detailed content of Understand what Node.js is?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



