

This is my first time learning Node.js crawler, so this is a simple crawler. The advantage of Node.js is that it can be executed concurrently.
This crawler is mainly to obtain Course information on MOOC.com and store the obtained information in a file, which uses the cheerio library, which allows us to conveniently operate HTML, just like using jQ
Before starting, remember
npm install cheerio
In order to crawl concurrently, the Promise object is used
//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}
In MOOC, each course has an ID. We must write the ID of the course we want to get into an array in advance, and each The address of each course is the same address plus ID, so we only need to concatenate the address and ID to get the address of the course
const baseUrl = 'http://www.imooc.com/learn/'; const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];
In order to obtain concurrent execution when obtaining each course content, use the all method in Promise
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});
In the then method, pages is the HTML page of each course. We have to extract the information we need from it. We need to use the following function
//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}Note: In the above The number of students studying the course is set to 0 because the number of students studying the course is dynamically obtained using Ajax, so I wrote a method later to specifically obtain the number of students studying the course. The Trim() method used is to remove spaces in the text
The number of people who want to get the course:
//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}In this way, the number of people who want to get the course are added to the courseMembers array, at the end Assign the number of people studying the course to the corresponding course
//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}
Once we have obtained the data, we must put it in a certain format Save to a file
//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
}
The last data obtained:
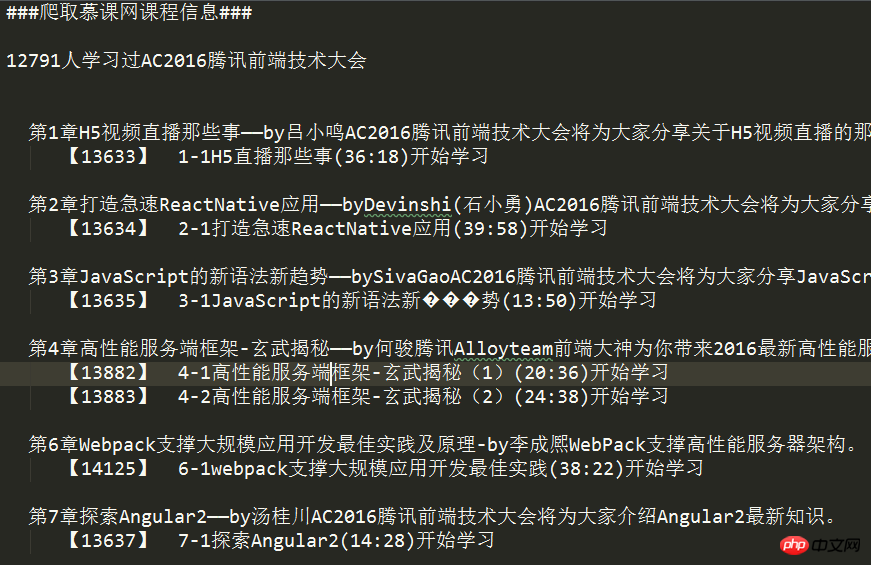
Source code:
/**
* Created by hp-pc on 2017/6/7 0007. */const http = require('http');
const fs = require('fs');
const cheerio = require('cheerio');
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];//输出的文件const outputFile = 'test.txt';//记录学习课程的人数let courseMembers = [];//去除字符串中的空格function Trim(str,is_global)
{
let result;
result = str.replace(/(^\s+)|(\s+$)/g,"");if(is_global.toLowerCase()=="g")
{
result = result.replace(/\s/g,"");
}return result;
}//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
}//所有页面爬取完后返回的Promise数组let courseArray = [];//循环所有的videosId,和baseUrl进行字符串拼接,爬取网页内容videosId.forEach((id)=>{//将爬取网页完毕后返回的Promise对象加入数组courseArray.push(getPageAsync(baseUrl + id));//获取学习的人数getNumber(baseNuUrl + id);
});
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});
The above is the detailed content of Example tutorial on crawling MOOC course information. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



