

Usage scenarios and solutions for compression in MySQL

Data distribution characteristics determine the efficiency of space compression. If the repetition rate of stored data is higher, the compression rate will be higher; usually Character typedata (CHAR, VARCHAR, TEXT or BLOB) has a higher compression rate, while the compression rate of some binary data or some already compressed data will not be very good
Introduction
Describe MySQL Compression usage scenarios and solutions, including compressed transmission protocols, compressed column solutions, and compressed table solutions.
When it comes to MySQL compression-related content, we can think of the following compression-related scenarios:
1. The amount of data transmitted between the client and the server is too large. Compression is needed to save bandwidth
2. MySQL has a large amount of data in a certain column, so only the data in a certain column is compressed
3. There is too much data in one or several MySQL tables , table data needs to be compressed and stored to reduce disk space usage
These problems have good solutions on the MySQL side. For the first problem, you can use MySQL's compression protocol to solve it; for the second problem The two problems can be perfectly solved by using MySQL's compression and decompression functions; while the third, most complex problem, can be solved at the engine level. Currently, myisam, innodb, tokudb, MyRocks and other engines support table compression. This article will discuss in detail such issues related to the MySQL compression mechanism. The following is the main content:
1. Introduction to the MySQL compression protocol
1. Applicable scenarios
The MySQL compression protocol is suitable for scenarios where the amount of data transmitted between the MySQL server and the client is large, or the available bandwidth is not high. Typical scenarios include the following two:
a. When querying a large amount of data, the bandwidth is not enough (such as when exporting data);
b. When copying, the binlog volume is too large. Enable the slave_compressed_protocol parameter for log compression and copying.
2. Introduction to compression protocol
The compression protocol is part of the MySQL communication protocol. To enable the compression protocol for data transmission, both the MySQL server and client need to support the zlib algorithm. Enabling the compression protocol causes a slight increase in CPU load. Use Enable Compression Protocol to enable the compression function of the client using the -C parameter or the --compress=true parameter. If the -C or compress=true option is enabled, then when connecting to the server segment, the server capability flag bit of 0x0020 (CLIENT_COMPRESS) will be sent. After negotiation with the server (after 3 handshakes), the compression protocol will be supported. . Due to the use of compression, the format of the data packet will change. The specific changes are as follows:
Uncompressed data packet format:

Compressed data packet Format:

You may have noticed that the compressed datagram format is divided into compressed and uncompressed formats. This is an optimization made by MySQL to reduce CPU overhead. If the content is less than 50 bytes, the content will not be compressed, but if it is greater than 50 bytes, the compression function will be enabled. The specific rules are as follows:
When the value of the third field is equal to 0x00, it means that the current packet is not compressed, so the content of n * byte is 1 * byte,n * byte, that is, request type and request content.
When the value of the third field is greater than 0x00, it means that the current package has been compressed by zlib, so when using it, n * byte needs to be decompressed, and the decompressed content is 1 * byte,n * byte, which is the request type and request content.
3. Solution practice
Add the -C or --compress=true parameter when the client connects. If you are adding compression protocol support for synchronization, you need to configure slave_compressed_protocol=1. The following is an example of using the compression protocol to connect to the MySQL server:
MySQL -h hostip -uroot -p password --compress MySQLdump -h hostip -uroot -p password -default-character-set=utf8 --compress --single-transaction dbname tablename > tablename.sql
If you need to enable compressed transmission in master-slave replication, enable the slave_compressed_protocol=1 parameter on the slave machine and it will be OK.
4. Compression effect
You can observe the effect of compression transmission by using the --compress option in MySQLdump, or you can observe the effect of compression transmission by using the slave_compressed_protocol parameter in master-slave replication. , it is easy to see the effect, no screenshots will be given here.
2. MySQL column compression solution
MySQL currently does not support direct column compression. Tencent’s TMySQL in the image can directly compress columns. . Here we mainly introduce a way to save the country, which is to use the compression and decompression functions provided by MySQL at the business level to perform compression and decompression operations on columns. That is to say, to compress a certain column, you need to call the COMPRESS function to compress the contents of that column when writing, and then store it in the corresponding column. When reading, use the UNCOMPRESSED function to decompress the compressed content.
1. Applicable scenarios
针对 MySQL 中某个列或者某几个列数据量特别大,一般都是 varchar、text、char 等数据类型。
2、压缩函数简介
MySQL 的压缩函数 COMPRESS 压缩一个字符串,然后返回一个二进制串。使用该函数需要 MySQL 服务端支持压缩,否则会返回 NULL,压缩字段最好采用 varbinary 或者 blob 字段类型保存。使用 UNCOMPRESSED 函数对压缩过的数据进行解压。注意,采用这种方式需要在业务侧做少量改造。压缩后的内容存储方式如下:
a、空字符串就以空字符串存储
b、非空字符串存储方式为前 4 个 bype 保存未压缩的字符串,紧接着保存压缩的字符串
3、方案实践
字段压缩方案涉及到的几个相关的函数如下:
压缩函数
COMPRESS()
解压缩函数
UNCOMPRESS()
字符串长度函数
LENGTH()
未解压字符串长度函数
UNCOMPRESSED_LENGTH()
实践步骤:
a、创建一张测试表
CREATE TABLE IF NOT EXISTS `test`.`test_compress` ( `id` int unsigned NOT NULL AUTO_INCREMENT COMMENT 'ID', `content` blob NOT NULL COMMENT '内容列', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=latin1 COMMENT='压缩测试表';
b、网表中插入压缩的数据
insert into `test`.`test_compress`(content) values(COMPRESS(REPEAT('a',1000)));
c、读取压缩的数据
select UNCOMPRESS(content) from `test`.`test_compress`;
d、查询对应的长度和内容
复制代码 代码如下:
SELECT UNCOMPRESSED_LENGTH(content) AS length, LENGTH(content) AS compress_length, UNCOMPRESS(content), content FROM `test`.`test_compress`
4、压缩效果
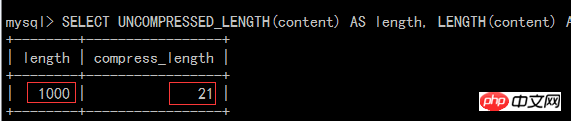
从上面截图可以看出压缩效果比较好,针对 text、char、varchr、blob 等,如果里面重复的数据越多压缩效果就越好。
三、InnoDB 表压缩方案解决方案
1、适用场景
采用压缩表一般都用在由于数据量太大,磁盘空间不足,负载主要体现在 IO 上,而服务器的 CPU 又有比较多的余量的场景。
2、表压缩简介 a、为什么需要压缩
目前很多表都支持压缩,比如 Myisam、InnoDB、TokuDB、MyRocks 。由于使用 InnoDB 主要是不需要做什么改动,对线上完全透明,压缩方案也非常成熟,因此这里只对 InnoDB 做详细说明。对于 TokuDB 和 MyRocks 的压缩方案将在 MySQL 的压缩方案(二)中撰文说明。
在 SSD 没有大量横行的时候,数据库几乎都是 IO 负载型的,在 CPU 有大量余量的时候,磁盘 IO 的瓶颈就已经凸显出来。而数据的大量存储,尤其是日志型数据和监控类型的数据,会导致磁盘空间快速增长。硬盘不够用也会在很多业务中凸显出来。一种比较好的方式就诞生了,那就是通过牺牲少量 CPU 资源,采用压缩来减少磁盘空间占用,以及优化 IO 和带宽。尤其针对读多些少的业务。
SSD 出来后,数据库的 IO 负载有所降低,但是对于磁盘空间的问题还是没有很好的解决。因此压缩表使用还是非常的广泛。这也就是为什么那么多的引擎都支持压缩的原因。而 innodb 在 MySQL 5.5 的时候就支持了压缩功能,只是压缩比比较低,通常在 50%左右。而 tokuDB 能达到 80%左右,MyRocks 的压缩比能达到 70%左右。
注意:压缩比和你存储的数据组成有很大的关系,并不是所有的数据都能达到上面所说的压缩比。如果大部分都是字符串,并且重复的数据比较多,压缩比会很好。
b、innodb 的压缩介绍
使用 innodb 压缩的前提条件是,innodb_file_per_table 这个参数要启用,innodb_file_format 这个参数设置成 Barracuda。
你可以使用 ROW_FORMAT=COMPRESSED 来 create 或者 alter 表来开启 innodb 的压缩功能,如果没有指定 KEY_BLOCK_SIZE 的大小,默认 KEY_BLOCK_SIZE 为 innodb_page_size 大小的一半,也可以通过指定 KEY_BLOCK_SIZE=n 参数来开启 innodb 的压缩功能,n 可以为 1、2、4、8、16,单位是 K。n 的值越小,压缩比越高,消耗的 CPU 资源也越多。注意 32K 或者 64K 的页不支持压缩。启用压缩后,索引数据也同样会被压缩。
你也可以通过调整 innodb_compression_level 来设置压缩的级别,级别从 1~9,默认是 6。级别越低,意味着压缩比越高,同时也意味着需要更多的 CPU 资源。
c、压缩算法
innodb 压缩借助的是著名的 zlib 库,采用 L777 压缩算法,这种算法在减少数据大小和 CPU 利用方面很成熟高效。同时这种算法是无损的,因此原生的未压缩的数据总是能够从压缩文件中重构,LZ777 实现原理是查找重复数据的序列号然后进行压缩,所以数据模式决定了压缩效率,一般而言,用户的数据能够被压缩 50%以上。
d、压缩表在 buffer_pool 中如何处理
在 buffer_pool 缓冲池中,压缩的数据通过 KEY_BLOCK_SIZE 的大小的页来保存,如果要提取压缩的数据或者要更新压缩数据对应的列,则会创建一个未压缩页来解压缩数据,然后在数据更新完成后,会将为压缩页的数据重新写入到压缩页中。内存不足的时候,MySQL 会讲对应的未压缩页踢出去。因此如果你启用了压缩功能,你的 buffer_pool 缓冲池中可能会存在压缩页和未压缩页,也可能只存在压缩页。不过可能仍然需要将你的 buffer_pool 缓冲池调大,以便能同时能保存压缩页和未压缩页。
MySQL 采用最少使用(LRU)算法来确定将哪些页保留在内存中,哪些页剔除出去,因此热数据会更多地保留在内存中。当压缩表被访问的时候,MySQL 使用自适应的 LRU 算法来维持内存中压缩页和非压缩页的平衡。当系统 IO 负载比较高的时候,这种算法倾向于讲未压缩的页剔除,一面腾出更多的空间来存放更多的压缩页。当系统 CPU 负载比较高的时候,MySQL 倾向于将压缩页和未压缩页都剔除出去,这个时候更多的内存用来保留热的数据,从而减少解压的操作。
e、如何评估 KEY_BLOCK_SIZE 是否合适
为了更深入地了解压缩表对性能的影响,在 Information Schema 库中有对应的表可以用来评估内存的使用和压缩率等指标。INNODB_CMP 是收集的是某一类的 KEY_BLOCK_SIZE 压缩表的整体状况的信息,汇总的是所有 KEY_BLOCK_SIZE 压缩表的统计。而 INNODB_CMP_PER_INDEX 表则是收集各个表和索引的压缩情况信息,这些信息对于在某个时间评估某个表的压缩效率或者诊断性能问题很有帮助。INNODB_CMP_PER_INDEX 表的收集会导致系统性能受到影响,必须 innodb_cmp_per_index_enabled 选项才会记录,生产环境最好不要开启。
我们可以通过观察 INNODB_CMP 表的压缩失败情况,如果失败比较多,则需要调大 KEY_BLOCK_SIZE。一般建议 KEY_BLOCK_SIZE 设置为 8。
3、方案实践
a、设置好 innodb_file_per_table 和 innodb_file_format 参数
SET GLOBAL innodb_file_per_table=1;SET GLOBAL innodb_file_format=Barracuda;
b、创建对应的压缩表
复制代码 代码如下:
CREATE TABLE compress_test (c1 INT PRIMARY KEY,content varchar(255)) ROW_FORMAT=COMPRESSEDKEY_BLOCK_SIZE=8;
如果是已经存在的表,则通过 alter 来修改,SQL 如下:
ALTER TABLE compress_test ROW_FORMAT=COMPRESSED KEY_BLOCK_SIZE=8;
4、压缩效果
压缩效果通过线上的一个监控的表修改为压缩后的文件大小来说明,压缩前后对比如下:
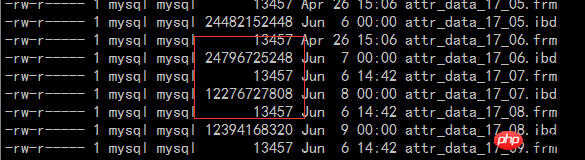
The above is the detailed content of Usage scenarios and solutions for compression in MySQL. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL: Simple Concepts for Easy Learning
Apr 10, 2025 am 09:29 AM
MySQL is an open source relational database management system. 1) Create database and tables: Use the CREATEDATABASE and CREATETABLE commands. 2) Basic operations: INSERT, UPDATE, DELETE and SELECT. 3) Advanced operations: JOIN, subquery and transaction processing. 4) Debugging skills: Check syntax, data type and permissions. 5) Optimization suggestions: Use indexes, avoid SELECT* and use transactions.
 How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
How to open phpmyadmin
Apr 10, 2025 pm 10:51 PM
You can open phpMyAdmin through the following steps: 1. Log in to the website control panel; 2. Find and click the phpMyAdmin icon; 3. Enter MySQL credentials; 4. Click "Login".
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL: Essential Skills for Developers
Apr 10, 2025 am 09:30 AM
MySQL and SQL are essential skills for developers. 1.MySQL is an open source relational database management system, and SQL is the standard language used to manage and operate databases. 2.MySQL supports multiple storage engines through efficient data storage and retrieval functions, and SQL completes complex data operations through simple statements. 3. Examples of usage include basic queries and advanced queries, such as filtering and sorting by condition. 4. Common errors include syntax errors and performance issues, which can be optimized by checking SQL statements and using EXPLAIN commands. 5. Performance optimization techniques include using indexes, avoiding full table scanning, optimizing JOIN operations and improving code readability.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Monitor Redis Droplet with Redis Exporter Service
Apr 10, 2025 pm 01:36 PM
Effective monitoring of Redis databases is critical to maintaining optimal performance, identifying potential bottlenecks, and ensuring overall system reliability. Redis Exporter Service is a powerful utility designed to monitor Redis databases using Prometheus. This tutorial will guide you through the complete setup and configuration of Redis Exporter Service, ensuring you seamlessly build monitoring solutions. By studying this tutorial, you will achieve fully operational monitoring settings
