

Introduction to offline data analysis process
3. OfflineData analysisProcess introduction
Note: This link mainly experiences the macro concept and processing process of the data analysis system, and initially understands the application links of hadoop and other frameworks. Don’t pay too much attention. Code details
A widely used data analysis system: "webLog data mining"
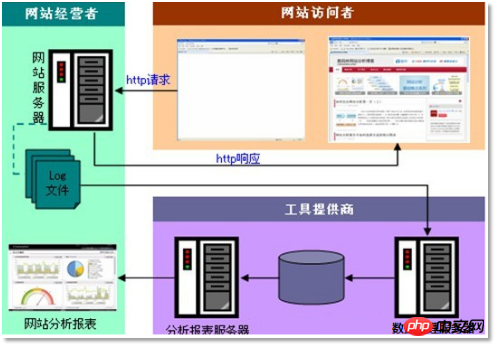
3.1 Requirements Analysis
3.1.1 Case Name
"Website or APPClickstream Log Data Mining System".
3.1.2 Case requirement description
“Web "Clickstream log" contains very important information for website operation. Through log analysis, we can know the number of visits to the website, which webpage has the most visitors, which webpage is the most valuable, advertising conversion rate, visitor source information, and visitor terminal information. wait.
3.1.3 Data source
The data of this case is mainly composed of User’s click behavior record
How to obtain: Pre-embed a js program on the page for the page you want to monitor Label binding event, as long as the user clicks or moves to the label, it can trigger the ajax request to the backgroundservlet program, use log4jRecord event information to the web server (nginx, tomcat, etc.), a growing log file is formed.
Form:
| ##58.215.204.118 - - [18/Sep/2013:06: 51:35 +0000] "GET /wp-includes/js/jquery/jquery.js?ver=1.10.2 HTTP/1.1" 304 0 "http://blog.fens.me/nodejs-socketio-chat/" "Mozilla/5.0 (Windows NT 5.1; rv:23.0) Gecko/20100101 Firefox/23.0" |

 3.2.3
3.2.3 

3.3
Final effect of the projectAfter the complete data processing process, reports of various statistical indicators will be periodically output. In production practice, these reports will eventually need to be The data is displayed in the form of visualization. This case uses the web program to realize data visualization.
The effect is as follows:
The above is the detailed content of Introduction to offline data analysis process. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Read CSV files and perform data analysis using pandas
Jan 09, 2024 am 09:26 AM
Read CSV files and perform data analysis using pandas
Jan 09, 2024 am 09:26 AM
Pandas is a powerful data analysis tool that can easily read and process various types of data files. Among them, CSV files are one of the most common and commonly used data file formats. This article will introduce how to use Pandas to read CSV files and perform data analysis, and provide specific code examples. 1. Import the necessary libraries First, we need to import the Pandas library and other related libraries that may be needed, as shown below: importpandasaspd 2. Read the CSV file using Pan
 How to open multiple Toutiao accounts? What is the process for applying for a Toutiao account?
Mar 22, 2024 am 11:00 AM
How to open multiple Toutiao accounts? What is the process for applying for a Toutiao account?
Mar 22, 2024 am 11:00 AM
With the popularity of mobile Internet, Toutiao has become one of the most popular news information platforms in my country. Many users hope to have multiple accounts on the Toutiao platform to meet different needs. So, how to open multiple Toutiao accounts? This article will introduce in detail the method and application process of opening multiple Toutiao accounts. 1. How to open multiple Toutiao accounts? The method of opening multiple Toutiao accounts is as follows: On the Toutiao platform, users can register accounts through different mobile phone numbers. Each mobile phone number can only register one Toutiao account, which means that users can use multiple mobile phone numbers to register multiple accounts. 2. Email registration: Use different email addresses to register a Toutiao account. Similar to mobile phone number registration, each email address can also register a Toutiao account. 3. Log in with third-party account
 Are Douyin sleep anchors profitable? What are the specific procedures for sleep live streaming?
Mar 21, 2024 pm 04:41 PM
Are Douyin sleep anchors profitable? What are the specific procedures for sleep live streaming?
Mar 21, 2024 pm 04:41 PM
In today's fast-paced society, sleep quality problems are plaguing more and more people. In order to improve users' sleep quality, a group of special sleep anchors appeared on the Douyin platform. They interact with users through live broadcasts, share sleep tips, and provide relaxing music and sounds to help viewers fall asleep peacefully. So, are these sleep anchors profitable? This article will focus on this issue. 1. Are Douyin sleep anchors profitable? Douyin sleep anchors can indeed earn certain profits. First, they can receive gifts and transfers through the tipping function in the live broadcast room, and these benefits depend on their number of fans and audience satisfaction. Secondly, the Douyin platform will give the anchor a certain share based on the number of views, likes, shares and other data of the live broadcast. Some sleep anchors will also
 Introducing the latest Win 11 sound tuning method
Jan 08, 2024 pm 06:41 PM
Introducing the latest Win 11 sound tuning method
Jan 08, 2024 pm 06:41 PM
After updating to the latest win11, many users find that the sound of their system has changed slightly, but they don’t know how to adjust it. So today, this site brings you an introduction to the latest win11 sound adjustment method for your computer. It is not difficult to operate. And the choices are diverse, come and download and try them out. How to adjust the sound of the latest computer system Windows 11 1. First, right-click the sound icon in the lower right corner of the desktop and select "Playback Settings". 2. Then enter settings and click "Speaker" in the playback bar. 3. Then click "Properties" on the lower right. 4. Click the "Enhance" option bar in the properties. 5. At this time, if the √ in front of "Disable all sound effects" is checked, cancel it. 6. After that, you can select the sound effects below to set and click
 Introduction to the skills and attributes of Hua Yishan Heart of the Moon Lu Shu
Mar 23, 2024 pm 05:30 PM
Introduction to the skills and attributes of Hua Yishan Heart of the Moon Lu Shu
Mar 23, 2024 pm 05:30 PM
In Hua Yishan Heart Moon, Lu Shu is an SSR celebrity. He is positioned as a single-target backline player and has a very impressive critical hit rate. Many players don’t know much about Lu Shu. Here’s what I’ve brought you. Come and take a look at the introduction to the skills and attributes of Hua Yishan Heart of the Moon Lu Shu. Celebrity Attributes Celebrity Skills 1. Lu Ming Shuzhong Skill Description: Lu Shu was born in Qiongqihui in Shuzhong. He has practiced martial arts since he was a child and has outstanding martial arts skills. Causes basic attack damage equal to 100% of the enemy's back row attack power, and reduces the target's rage by 10 points. Skill attributes: Level 2: Basic attack damage increased to 105%. Level 2: Basic attack damage is increased to 110%, and the target's rage is reduced by 15 points. Level 2: Basic attack damage increased to 115%. Level 2: Basic attack damage is increased to 120%, and the target's rage is reduced by 20 points. Level 2: Basic attack
 PyCharm Beginner's Guide: Comprehensive Analysis of Replacement Functions
Feb 25, 2024 am 11:15 AM
PyCharm Beginner's Guide: Comprehensive Analysis of Replacement Functions
Feb 25, 2024 am 11:15 AM
PyCharm is a powerful Python integrated development environment with rich functions and tools that can greatly improve development efficiency. Among them, the replacement function is one of the functions frequently used in the development process, which can help developers quickly modify the code and improve the code quality. This article will introduce PyCharm's replacement function in detail, combined with specific code examples, to help novices better master and use this function. Introduction to the replacement function PyCharm's replacement function can help developers quickly replace specified text in the code
 Detailed information on the location of the printer driver on your computer
Jan 08, 2024 pm 03:29 PM
Detailed information on the location of the printer driver on your computer
Jan 08, 2024 pm 03:29 PM
Many users have printer drivers installed on their computers but don't know how to find them. Therefore, today I bring you a detailed introduction to the location of the printer driver in the computer. For those who don’t know yet, let’s take a look at where to find the printer driver. When rewriting content without changing the original meaning, you need to The language is rewritten to Chinese, and the original sentence does not need to appear. First, it is recommended to use third-party software to search. 2. Find "Toolbox" in the upper right corner. 3. Find and click "Device Manager" below. Rewritten sentence: 3. Find and click "Device Manager" at the bottom 4. Then open "Print Queue" and find your printer device. This time it is your printer name and model. 5. Right-click the printer device and you can update or uninstall it.
 Detailed introduction of Samsung S24ai functions
Jun 24, 2024 am 11:18 AM
Detailed introduction of Samsung S24ai functions
Jun 24, 2024 am 11:18 AM
2024 is the first year of AI mobile phones. More and more mobile phones integrate multiple AI functions. Empowered by AI smart technology, our mobile phones can be used more efficiently and conveniently. Recently, the Galaxy S24 series released at the beginning of the year has once again improved its generative AI experience. Let’s take a look at the detailed function introduction below. 1. Generative AI deeply empowers Samsung Galaxy S24 series, which is empowered by Galaxy AI and brings many intelligent applications. These functions are deeply integrated with Samsung One UI6.1, allowing users to have a convenient intelligent experience at any time, significantly improving the performance of mobile phones. Efficiency and convenience of use. The instant search function pioneered by the Galaxy S24 series is one of the highlights. Users only need to press and hold
