

JAVA WEB notes--Chinese garbled characters
JAVA WEB Garbled Code Problem Analysis
Cause of Garbled Code
In the process of Java Web development, we often encounter the problem of garbled code. The reason for garbled code can be summarized as character encoding. Does not match the decoding method.
Since the reason for garbled characters is that the character encoding and decoding methods do not match, then why do we have to encode the characters? Is it okay not to encode them? This is because the basic unit of storing data in a computer is 1 byte, that is, 8 bits, so the maximum number of characters it can express is 28=256, and in our real society There are far more characters (Chinese characters, English, other characters, etc.) than this number, so in order to solve the conflict between characters and bytes, characters must be encoded before they can be stored in the computer.
Encoding and decoding
Common encoding methods in computers include ASCII, ISO-8859-1, GB2312, UTF-16, and UTF-8. .
ASCII code is represented by the lower 7 bits of a byte, so the maximum number of characters that can be expressed is 27=128. ISO-8859-1 is an extension of the ISO organization based on ASCII code. It is compatible with ASCII code and covers most Western European characters. ISO8859-1 uses one byte to represent, so it can express up to 256 characters. GB2312 uses double-byte encoding. The encoding range is A1-F7, where A1-A9 is the symbol area and B0-F7 is the Chinese character area, containing 6763 Chinese characters. GBK is to expand the GB2312 encoding and add more Chinese characters. There are 21,003 Chinese characters that can be expressed. UTF-16 uses a fixed-length encoding method. No matter what character is represented, it is represented by 2 bytes. This is also the storage format of characters in JAVA memory. Contrary to UTF-16, UTF-8 uses a variable-length encoding method, and different types of characters can be composed of 1-6 bytes.
Let’s take a look at the encoding of different encoding methods in the computer using the string "Hyuuga Hinata", as shown below.

Garbled code analysis and solution
For the garbled code problem in JAVA WEB, We divide the garbled characters caused by the request and the garbled characters caused by the response. For different garbled characters, we need to analyze the causes of the garbled characters, that is, what is the character encoding method and what is the decoding method.
For the garbled characters caused by the request, we need to analyze the Http request and check its encoding method. Since the HTTP request is divided into Get request and Post request, we will discuss them separately next.
For Get request, it is the default request method of the browser, and the submission method when the form is set to "Get" when submitting. We check the specific content through Firefox browser as follows:
The address bar is: 
The request content is:

Through the above request, we can see that the query string in the GET request is stored in the request line and sent to the WEB server , through the "Hyuga Hinata" encoding we can see that the encoding method used by the browser for this string is "UTF-8".
Looking at the server code, we can see garbled characters (as shown below). This is because the server decodes the data after receiving the string encoding by default using ISO-8859-1. , so the encoding and decoding methods are not unified.

The solution is as follows:
First get the string user before decoding encoding, and then specify the encoding method of the string, as shown below:

## The solution diagram is as follows:

In the process of Java web development, we pass parameters in hyperlinks and often encounter Chinese situations. In this case, we need to encode Chinese, we can set it to UTF-8, and the decoding scheme is the same as above.
<a href="${pageContext.request.contextPath}/Test?user=<%=URLEncoder.encode("日向雏田", "UTF-8")%>">点击</a>For Post request, it is the submission method when the form submission is set to "Post". We use the Firefox browser to view its specific content as follows:
The address bar and its page are:

The post request content is:

We can know from the above picture that in the post request , put the request content directly in the request body and send it to the web server, and the encoding method is "utf-8".
In this response Servlet, the doPost method body is as follows:
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String user=request.getParameter("user");
System.out.println(user);//输出为æ¥åéç°
}
The reason for the garbled characters here is still when the code getParameter ("user"), the web server uses the default decoding scheme "ISO-8859-1" for decoding, resulting in encoding and decoding schemes I disagree, the solution can be to use the get request garbled solution, but there is a simpler solution, directly specify the encoding/decoding scheme of the method body as "utf-8". The plan is as follows.
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8"); //设置请求体的编码/解码方案为UTF-8 但是请求行的编码解码方案不会受影响
String user=request.getParameter("user");
System.out.println(user); //输出为日向雏田
}The above analysis of the garbled code caused by the request is completed.
In the garbled code caused by the impact, the web server will write the response content into the response body and return it to the client without involving the status line. For example, if "HelloWorld" is output to the browser, the response is as shown in the figure below.
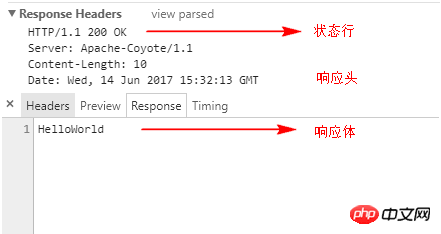
We have to involve four methods for the garbled code caused by the response, as follows:
response.setHeader("Content-Type", "text/html;cahrset=utf-8");//设置发送到客户端的响应的内容类型和响应内容的编码类型(响应体的编码类型)
response.setCharacterEncoding("utf-8");//设置响应体的编码类型
response.getWriter(); //获取响应的输出字符流
response.getOutputStream(); //获取响应的输出字节流
For setting the response body Encoding type, such as response.setHeader("Content-Type", "text/html;cahrset=utf-8"); and response.setCharacterEncoding("utf-8"); The encoding methods set by these two methods are equivalent. If the encoding method of the response body is not set, the default is ISO-8859-1, and the subsequent encoding method of the response body characters will iterate the previous encoding method. Both of these methods are valid before the getWriter method, and the method of setting encoding in the getWriter method will be invalid.
But these two methods are a little different, that is, the browser will automatically use the setHeader("Content-Type", "text/html;cahrset=utf-8") method. The encoding method of the response body is decoded, and the setCharacterEncoding() method is not used by all browsers to decode. The two methods are tested below, and the results are as follows:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setHeader("Content-Type", "text/html;charset=utf-8");
response.getWriter().write("日向雏田");
} 
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
response.setCharacterEncoding("utf-8");
response.getWriter().write("日向雏田");
} 
从上面可以看到第一个方法对于浏览器来说,支持的较好,提倡采用第一种方法设置响应体的字符编码方式。
对于获取响应字符输出流的方法,如果在此之前没有设置响应体的编码方式,那么默认为null,即ISO-8859-1方式进行编码。而且后面设置的编码方式会覆盖前面设置的编码方式。在getWriter()方法之后设置的编码无效。
对于获取响应输出字节流,我们在输出字符串时,我们需要设置字符串的编码方式如果没有那么默认ISO-8859-1。
对于前面2个输出流,由于只有一个输出缓存,所以这两个方法互斥。
以上,为了保证响应无乱码,需要保证字符编码和解码方法的统一,方案如下:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
// 方案1
// response.setHeader("Content-Type", "text/html;charset=utf-8");
// response.getWriter().write("日向雏田");
// 方案2
// response.getOutputStream().write("日向雏田".getBytes("UTF-8"));
// 方案1,2互斥
}
此外在Java web开发过程中,我们还会遇到当进行文件下载时,中文文件名导致的问题,如下图所示:
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
response.setHeader("content-disposition", "attachment;filename="+fileName);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}采用火狐浏览器进行测试,查看页面效果,及其响应结果如下:


经过查看响应头分析,下载文件名存放在响应头中,且对于中文文字没有采用UTF-8、UTF-16、GBK等等能识别中文的编码,那么对于中文文件名导致采用哪种编码方式呢?查看REF 7578得知,在此处采用ASCII编码,但是REF规定,如果不可避免的要使用非ASCII码的字符,程序员应该均匀的使用UTF-8,来最小化交互操作的问题。
所以,解决方案就是把文件名编码成UTF-8,传递给响应头,浏览器(部分)默认对该文件名进行UTF-8解码处理。
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
String realPath=this.getServletContext().getRealPath("/src/日向雏田.jpg");
String fileName=realPath.substring(realPath.lastIndexOf('\\')+1);
String utf_8Name=URLEncoder.encode(fileName,"utf-8");//解决方案
response.setHeader("content-disposition", "attachment;filename="+utf_8Name);
InputStream is=new FileInputStream(new File(realPath));
OutputStream os=response.getOutputStream();
byte[] buff=new byte[1024];
int len=0;
while((len=is.read(buff))>0){
os.write(buff, 0, len);
}
os.close();
is.close();
}效果如下:其中火狐浏览器并没有对其解码

The above is the detailed content of JAVA WEB notes--Chinese garbled characters. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 How to delete Xiaohongshu notes
Mar 21, 2024 pm 08:12 PM
How to delete Xiaohongshu notes
Mar 21, 2024 pm 08:12 PM
How to delete Xiaohongshu notes? Notes can be edited in the Xiaohongshu APP. Most users don’t know how to delete Xiaohongshu notes. Next, the editor brings users pictures and texts on how to delete Xiaohongshu notes. Tutorial, interested users come and take a look! Xiaohongshu usage tutorial How to delete Xiaohongshu notes 1. First open the Xiaohongshu APP and enter the main page, select [Me] in the lower right corner to enter the special area; 2. Then in the My area, click on the note page shown in the picture below , select the note you want to delete; 3. Enter the note page, click [three dots] in the upper right corner; 4. Finally, the function bar will expand at the bottom, click [Delete] to complete.
 How to set Chinese in Call of Duty: Warzone mobile game
Mar 22, 2024 am 08:41 AM
How to set Chinese in Call of Duty: Warzone mobile game
Mar 22, 2024 am 08:41 AM
Call of Duty Warzone is a newly launched mobile game. Many players are very curious about how to set the language of this game to Chinese. In fact, it is very simple. Players only need to download the Chinese language pack, and then You can modify it after using it. The detailed content can be learned in this Chinese setting method introduction. Let us take a look together. How to set the Chinese language for the mobile game Call of Duty: Warzone 1. First enter the game and click the settings icon in the upper right corner of the interface. 2. In the menu bar that appears, find the [Download] option and click it. 3. Select [SIMPLIFIEDCHINESE] (Simplified Chinese) on this page to download the Simplified Chinese installation package. 4. Return to the settings
 Setting up Chinese with VSCode: The Complete Guide
Mar 25, 2024 am 11:18 AM
Setting up Chinese with VSCode: The Complete Guide
Mar 25, 2024 am 11:18 AM
VSCode Setup in Chinese: A Complete Guide In software development, Visual Studio Code (VSCode for short) is a commonly used integrated development environment. For developers who use Chinese, setting VSCode to the Chinese interface can improve work efficiency. This article will provide you with a complete guide, detailing how to set VSCode to a Chinese interface and providing specific code examples. Step 1: Download and install the language pack. After opening VSCode, click on the left
 How to set Excel table to display Chinese? Excel switching Chinese operation tutorial
Mar 14, 2024 pm 03:28 PM
How to set Excel table to display Chinese? Excel switching Chinese operation tutorial
Mar 14, 2024 pm 03:28 PM
Excel spreadsheet is one of the office software that many people are using now. Some users, because their computer is Win11 system, so the English interface is displayed. They want to switch to the Chinese interface, but they don’t know how to operate it. To solve this problem, this issue The editor is here to answer the questions for all users. Let’s take a look at the content shared in today’s software tutorial. Tutorial for switching Excel to Chinese: 1. Enter the software and click the "File" option on the left side of the toolbar at the top of the page. 2. Select "options" from the options given below. 3. After entering the new interface, click the “language” option on the left
 What should I do if the notes I posted on Xiaohongshu are missing? What's the reason why the notes it just sent can't be found?
Mar 21, 2024 pm 09:30 PM
What should I do if the notes I posted on Xiaohongshu are missing? What's the reason why the notes it just sent can't be found?
Mar 21, 2024 pm 09:30 PM
As a Xiaohongshu user, we have all encountered the situation where published notes suddenly disappeared, which is undoubtedly confusing and worrying. In this case, what should we do? This article will focus on the topic of "What to do if the notes published by Xiaohongshu are missing" and give you a detailed answer. 1. What should I do if the notes published by Xiaohongshu are missing? First, don't panic. If you find that your notes are missing, staying calm is key and don't panic. This may be caused by platform system failure or operational errors. Checking release records is easy. Just open the Xiaohongshu App and click "Me" → "Publish" → "All Publications" to view your own publishing records. Here you can easily find previously published notes. 3.Repost. If found
 Will wwe2k24 have Chinese?
Mar 13, 2024 pm 04:40 PM
Will wwe2k24 have Chinese?
Mar 13, 2024 pm 04:40 PM
"WWE2K24" is a racing sports game created by Visual Concepts and was officially released on March 9, 2024. This game has been highly praised, and many players are eagerly interested in whether it will have a Chinese version. Unfortunately, so far, "WWE2K24" has not yet launched a Chinese language version. Will wwe2k24 be in Chinese? Answer: Chinese is not currently supported. The standard version of WWE2K24 in the Steam Chinese region is priced at 199 yuan, the deluxe version is 329 yuan, and the commemorative edition is 395 yuan. The game has relatively high configuration requirements, and there are certain standards in terms of processor, graphics card, or running memory. Official recommended configuration and minimum configuration introduction:
 How to add product links in notes in Xiaohongshu Tutorial on adding product links in notes in Xiaohongshu
Mar 12, 2024 am 10:40 AM
How to add product links in notes in Xiaohongshu Tutorial on adding product links in notes in Xiaohongshu
Mar 12, 2024 am 10:40 AM
How to add product links in notes in Xiaohongshu? In the Xiaohongshu app, users can not only browse various contents but also shop, so there is a lot of content about shopping recommendations and good product sharing in this app. If If you are an expert on this app, you can also share some shopping experiences, find merchants for cooperation, add links in notes, etc. Many people are willing to use this app for shopping, because it is not only convenient, but also has many Experts will make some recommendations. You can browse interesting content and see if there are any clothing products that suit you. Let’s take a look at how to add product links to notes! How to add product links to Xiaohongshu Notes Open the app on the desktop of your mobile phone. Click on the app homepage
 Tips for solving Chinese garbled characters when writing txt files with PHP
Mar 27, 2024 pm 01:18 PM
Tips for solving Chinese garbled characters when writing txt files with PHP
Mar 27, 2024 pm 01:18 PM
Tips for solving Chinese garbled characters written by PHP into txt files. With the rapid development of the Internet, PHP, as a widely used programming language, is used by more and more developers. In PHP development, it is often necessary to read and write text files, including txt files that write Chinese content. However, due to encoding format problems, sometimes the written Chinese will appear garbled. This article will introduce some techniques to solve the problem of Chinese garbled characters written into txt files by PHP, and provide specific code examples. Problem analysis in PHP, text
