
In the previous section "spring-cloud-sleuth+zipkin tracking service implementation (1)", we used microservice-zipkin-server, microservice-zipkin-client, microservice- The three zipkin-client-backend programs implement service call link tracking using http for communication and data persistence into memory.
Here we make two changes. First, the data is changed from being stored in memory to being persisted to the database. Second, the http communication is changed to mq asynchronous communication.
We still use the three programs in the previous section to make modifications so that everyone can see the differences. Here, a stream is added to each project name to indicate the difference.
To change the http method to communication through MQ, we need to replace the original dependent io.zipkin.java:zipkin-server with spring-cloud-sleuth-zipkin-stream and spring-cloud-starter-stream-rabbit
To use mysql persistence at the same time, we need to add mysql related dependencies.
All maven dependencies are as follows:
" <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--zipkin依赖--> <!--此依赖会自动引入spring-cloud-sleuth-stream并且引入zipkin的依赖包--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--保存到数据库需要如下依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> "
After adding the above maven dependencies, we will replace the @EnableZipkinServer annotation in the startup class ZipkinServer with @EnableZipkinStreamServer,
The details are as follows:
package com.yangyang.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* Created by chenshunyang on 2017/5/24.
*/
@EnableZipkinStreamServer// //使用Stream方式启动ZipkinServer
@SpringBootApplication
public class ZipkinStreamServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinStreamServerApplication.class,args);
}
}Click@ From the source code of the EnableZipkinStreamServer annotation, we can see that it also introduces the @EnableZipkinServer annotation and also creates a rabbit-mq message queue listener. 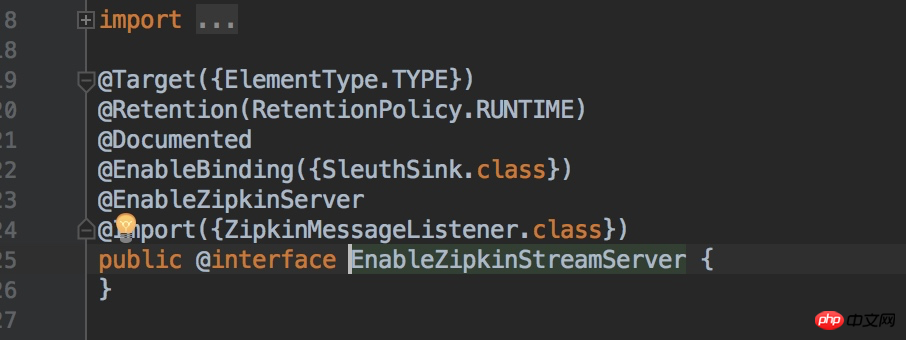
To facilitate receiving mq messages sent from the message client.
Since the message middleware rabbit mq and mysql are used, we also need to add relevant configurations to the configuration file application.properties:
server.port=11020 spring.application.name=microservice-zipkin-stream-server #zipkin数据保存到数据库中需要进行如下配置 #表示当前程序不使用sleuth spring.sleuth.enabled=false #表示zipkin数据存储方式是mysql zipkin.storage.type=mysql #数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素 spring.datasource.schema[0]=classpath:/zipkin.sql #spring boot数据源配置 spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.initialize=true spring.datasource.continue-on-error=true #rabbitmq配置 spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
Among them, zipkin.sql can be copied directly to the official website, or You can copy it from this demo
In order to avoid interference from http communication, we changed the original listening port from 11008 to 11020, started the program, and no error was reported and the rabbit connection log could be seen, indicating that the program started successfully.
The same as the configuration in the previous section, the client configuration is also very simple, and the maven dependency only You need to replace the original spring-cloud-starter-zipkin with the following two dependencies
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
In addition, add the configuration to connect to MQ in the configuration file
server: port: 11021 spring: application: name: microservice-zipkin-stream-client #rabbitmq配置 rabbitmq: host: 127.0.0.1 port : 5672 username: guest password: guest
Of course for the sake of demonstration Difference, the port has also been adjusted accordingly
Access according to the previous section: http://localhost:11021/call/1, we can go to the previous section, This shows that the sleuth function of rabbit-mq communication has taken effect.
We have visited the consumer's address many times and can see in the log that the request time will not suddenly take a long time.
In order to experience the feature of no data loss brought to us by MQ communication, we clear the data in the database, and then refresh the zipkin server interface. You can see that there is no more data.
Then we will zipkin -The server program wants to close, and then access the consumer address multiple times. After that, we restart the zipkin server program, and access the UI interface after successful startup
Soon we see that the Span Name option has data to select, and at the same time, the records in the database The number of entries is no longer the previous 0.
This shows that after restarting our zipkin, we successfully obtained the information data generated by the provider and consumer during the shutdown period from MQ. In this way, we can use the rest service call tracking function of spring-cloud-sleuth-stream+zipkin.
The above is the detailed content of spring-cloud-sleuth+zipkin tracking service implementation (2). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



