
How many bytes does an object occupy?
Regarding the size of the object, for C/C++, there is a sizeof function that can be directly obtained, but Java does not seem to have such a method. Fortunately, the Instrumentation class was introduced after JDK 1.5. This class provides a method for calculating the memory footprint of an object. As for how to use the specific Instrumentation class, I won’t go into detail. You can refer to this article on how to accurately measure the size of Java objects.
But one difference is that this article uses the command line to pass in JVM parameters to specify the agent. Here I set the JVM parameters through Eclipse:

#The following is the specific path of agent.jar that I typed. I won’t talk about the rest, but take a look at the test code:
1 public class JVMSizeofTest { 2 3 @Test 4 public void testSize() { 5 System.out.println("Object对象的大小:" + JVMSizeof.sizeOf(new Object()) + "字节"); 6 System.out.println("字符a的大小:" + JVMSizeof.sizeOf('a') + "字节"); 7 System.out.println("整型1的大小:" + JVMSizeof.sizeOf(new Integer(1)) + "字节"); 8 System.out.println("字符串aaaaa的大小:" + JVMSizeof.sizeOf(new String("aaaaa")) + "字节"); 9 System.out.println("char型数组(长度为1)的大小:" + JVMSizeof.sizeOf(new char[1]) + "字节");10 }11 12 }The running result is:
Object对象的大小:16字节 字符a的大小:16字节 整型1的大小:16字节 字符串aaaaa的大小:24字节 char型数组(长度为1)的大小:24字节
Then, the code remains unchanged, add a virtual machine parameter "-XX:-UseCompressedOops", and run the test class again. The running result is:
Object对象的大小:16字节 字符a的大小:24字节 整型1的大小:24字节 字符串aaaaa的大小:32字节 char型数组(长度为1)的大小:32字节
The reason will be explained in detail later.
Java object size calculation method
JVM size for ordinary objects and array objects The calculation method is different, I drew a picture to illustrate:
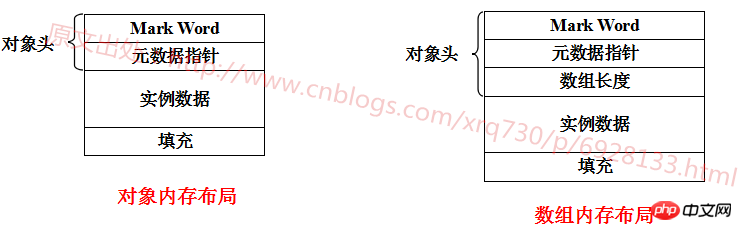
Explain each part of it:
Mark Word: stores information recorded when the object is running, and the memory size occupied is the same as the number of machine digits, that is, 32-bit machine occupies 4 bytes , 64-bit machine occupies 8 bytes
Metadata pointer: Points to the Klass object describing the type (the C++ counterpart of the Java class ) pointer, the Klass object contains metadata of the type to which the instance object belongs, so this field is called a metadata pointer. The JVM will frequently use this pointer to locate the type information located in the method area during runtime. The size of this data will be discussed later
Array length: unique to array objects, a reference type pointing to int type, used to describe the length of the array, the size of this data The same size as the metadata pointer, the same will be said later
Instance data: Instance data is The eight basic data types are byte, short, int, long, float, double, char, and boolean (object types are also composed of these eight basic data types). How many bytes each data type occupies is not listed one by one.
Padding: indefinite, HotSpot’s alignment is 8-byte alignment, that is, an object must be an integer multiple of 8 bytes , so if the last data size is 17, fill it with 7, and if the previous data size is 18, fill it with 6, and so on
Finally let’s talk about the size of the metadata pointer. The metadata pointer is a reference type, so normally the 64-bit machine metadata pointer should be 8 bytes, and the 32-bit machine metadata pointer should be 4 bytes, but there is an optimization in HotSpot that compresses the metadata type pointer. Storage, use JVM parameters:
-XX:+UseCompressedOops to turn on compression
- XX:-UseCompressedOops turns off compression
HotSpot defaults to the former, which means turning on metadata pointer compression. When compression is turned on, the metadata pointer on a 64-bit machine will Occupies 4 bytes in size. In other wordsWhen compression is turned on, the reference on the 64-bit machine will occupy 4 bytes, otherwise it will be the normal 8 bytes.
Calculation of Java object memory size
With the above theoretical basis, we will You can analyze the execution results of the JVMSizeofTest class and why the size of the same object is different after adding the "-XX:-UseCompressedOops" parameter.
The first is the size of the Object:
When pointer compression is turned on, 8 bytes Mark Word + 4 words Section metadata pointer = 12 bytes, because 12 bytes is not a multiple of 8, so 4 bytes are filled, and the object Object occupies 16 bytes of memory
Close When pointers are compressed, 8-byte Mark Word + 8-byte metadata pointer = 16 bytes. Since 16 bytes is exactly a multiple of 8, there is no need to fill bytes, and the object Object occupies 16 bytes of memory
Then the size of the character 'a':
When pointer compression is turned on, 8-byte Mark Word + 4 bytes metadata pointer + 1 byte char = 13 bytes, since 13 bytes is not a multiple of 8, so 3 bytes are padded, character 'a' occupies 16 bytes of memory
When pointer compression is turned off, 8 bytes Mark Word + 8 bytes metadata pointer + 1 byte char = 17 bytes, since 17 bytes is not a multiple of 8, it is padded 7 bytes, the character 'a' occupies 24 bytes of memory
Then the size of the integer 1:
When pointer compression is turned on, 8-byte Mark Word + 4-byte metadata pointer + 4-byte int = 16 bytes. Since 16 bytes is exactly a multiple of 8, there is no need to fill bytes. , integer 1 occupies 16 bytes of memory
When pointer compression is turned off, 8 bytes Mark Word + 8 bytes metadata pointer + 4 bytes int = 20 bytes. Since 20 bytes is exactly a multiple of 8, it is filled with 4 bytes. The integer 1 occupies 24 bytes of memory.
followed by the string The size of "aaaaa", all static fields do not need to be managed, only the instance fields are focused on, the instance fields in the String object include "char value[]" and "int hash", it can be seen from this:
When pointer compression is turned on, 8-byte Mark Word + 4-byte metadata pointer + 4-byte reference + 4-byte int = 20 bytes. Since 20 bytes is not a multiple of 8, so Filling 4 bytes, the string "aaaaa" occupies 24 bytes of memory
When pointer compression is turned off, 8 bytes Mark Word + 8 bytes metadata pointer + 8 bytes reference + 4 bytes int = 28 bytes, since 28 bytes is not a multiple of 8, so 4 bytes are padded, and the string "aaaaa" occupies 32 bytes of memory
The last is the size of the char array with length 1:
When pointer compression is turned on, 8-byte Mark Word + 4-byte metadata pointer + 4-byte array size reference + 1-byte char = 17 bytes. Since 17 bytes is not a multiple of 8, 7 bytes are padded. A char array of length 1 occupies 24 words. Section Memory
#When pointer compression is turned off, 8 bytes of Mark Word + 8 bytes of metadata pointer + 8 bytes of array size reference + 1 word Section char = 25 bytes. Since 25 bytes is not a multiple of 8, it is filled with 7 bytes. The char array with a length of 1 occupies 32 bytes of memory.
##Mark Word
Mark Word has been seen before, it is a very important part of the Java object header. Mark Word stores the running data of the object itself, such as hash code (HashCode), GC generation age, lock status identification, locks held by threads, biased thread ID, biased timestamp, etc.
However, because the object needs to store a lot of runtime data, it actually exceeds the limit that the 32-bit and 64-bit Bitmap structures can record. However, the object header is data defined with the object itself. Regardless of the additional storage cost, taking into account the space efficiency of the virtual machine, Mark Word is designed as a non-fixed data structure in order to store as much information as possible in a very small space. For example, when the object in the 32-bit HotSpot virtual machine is not locked, 25 Bits in the 32 Bits space of Mark Word are used to store the object hash code (HashCode), 4 Bits are used to store the object generation age, and 2 Bits are used to store the object generation age. Storage lock identification bit, 1Bit fixed bit 0. The storage content of objects in other states (lightweight locking, heavyweight locking, GC mark, biasable) is as shown in the figure below:
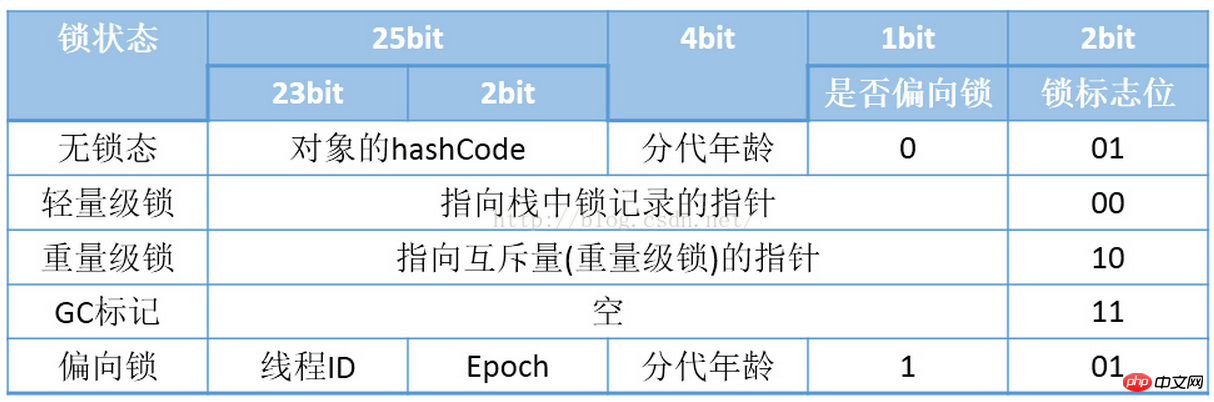
What we need to pay special attention to here is the lock status. The lock status and changes in the lock status will be studied later.
Upgrade of lock
As shown in the figure above, there are four lock states. : No lock state, biased locks, lightweight locks and heavyweight locks. Biased locks and lightweight locks were introduced starting from JDK1.6 to reduce the performance consumption caused by acquiring and releasing locks.
The status of the four locks will gradually escalate with competition. Locks can be upgraded but cannot be downgraded, which means that biased locks can be upgraded to lightweight locks but lightweight locks cannot be downgraded. To bias the lock, the purpose is to improve the efficiency of acquiring and releasing locks. Use a diagram to represent this relationship:

bias lock
HotSpot author passes Previous research has found that in most cases, there is not only no multi-thread competition for locks, but also always acquired multiple times by the same thread. In order to make the code for threads to acquire locks lower, biased locks are introduced. The process of obtaining the bias lock is:
Access Mark Word to see if the bias lock flag is set to 1 and whether the flag bit is 01----Confirm it is Biasable state
If it is in the biasable state, test whether the thread id points to the current thread, if so, execute (5), otherwise execute (3)
#If the thread id does not point to the current thread, compete for the lock through CAS operation. If the competition succeeds, set the thread id in Mark Word to the current thread id, and then execute (5); if the competition fails, execute (4)
If CAS fails to acquire the biased lock, it means there is competition. When the global safepoint (safepoint) is reached, the thread that obtained the biased lock is suspended, and the biased lock is upgraded to a lightweight lock (because the biased lock assumes no competition, but there is competition here, and the biased lock needs to be upgraded), and then The thread blocked at the safe point continues to execute the synchronization code
Execute the synchronization code
As soon as it is acquired, it will be released. The release point of the biased lock lies in step (4) above. Only when other threads try to compete for the biased lock, the thread holding the biased lock will release the lock, the thread will not take the initiative to release the bias lock. The release process of the biased lock is:
Need to wait for the global safety point (no bytecode is being executed at this point in time)
It will first suspend the thread that owns the bias lock and determine whether the lock object is locked
Bias lock release Then restore to the unlocked (identification bit is 01) or lightweight lock (identification bit is 00) state
Lightweight lock
The locking process of lightweight lock is:
Enter the code When synchronizing a block, if the lock status of the synchronization object is lock-free, the JVM will first create a space called Lock Record in the stack frame of the current thread to store a copy of the current Mark Word of the lock object. Officially called Displaced Mark Word, at this time the status of the thread stack and object header is as shown in the figure 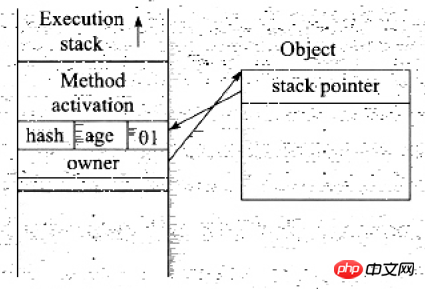
Copy the Mark Word in the object header to the lock record
After the copy is successful, the JVM will use the CAS operation to try to update the Mark Word of the object to a pointer to the Lock Record, and store it in the Lock Record. The owner pointer points to the Object Mark Word. If the update is successful, perform step (4), otherwise perform step (5)
If the update action is successful, then the current The thread owns the lock of the object, and the lock flag of the object Mark Word is set to 00, which means that the object is in a lightweight lock state. At this time, the status of the thread stack and object header is as shown in the figure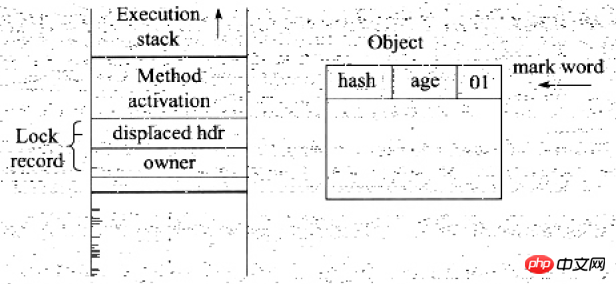
If the update action fails, the JVM will first check whether the Mark Word of the object points to the stack frame of the current thread. If so, it means that the current thread already owns the lock of this object. , then you can directly enter the synchronized block to continue execution. Otherwise, it means that multiple threads compete for the lock, and the lightweight lock will expand into a heavyweight lock, and the status value of the lock identifier will become 10. What is stored in the Mark Word is the pointer to the heavyweight lock, and the threads waiting for the lock will also enter later. blocking state. The current thread tries to use spin to acquire the lock. Spin is to prevent the thread from blocking and uses a loop to acquire the lock.
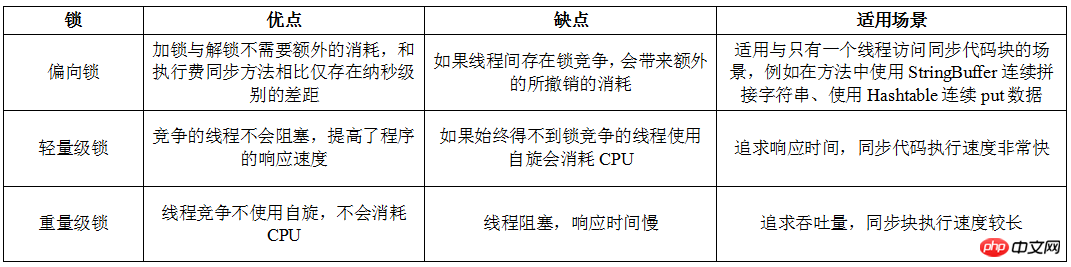
Comparison of biased locks, lightweight locks and heavyweight locks
The following uses a table to compare biased locks and lightweight locks Class locks and heavyweight locks, I saw it online and I think it is very well written. In order to deepen my memory, I typed it again by hand:
The above is the detailed content of Java Virtual Machine 14: Java object size, object memory layout and lock status changes. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



