

Python crawler audio data example

1: Foreword
This time we crawled the information of each channel of all radio stations under the popular column of Himalaya and various information of each audio data in the channel, and then put the crawled data Save to mongodb for subsequent use. This time the amount of data is around 700,000. Audio data includes audio download address, channel information, introduction, etc., there are many.
I had my first interview yesterday. The other party was an artificial intelligence big data company. I was going to do an internship during the summer vacation of my sophomore year. They asked me to have crawled audio data, so I came to analyze Himalaya. The audio data crawls down. At present, I am still waiting for three interviews, or to be notified of the final interview news. (Because I can get certain recognition, I am very happy regardless of success or failure)
2: Running environment
IDE: Pycharm 2017
Python3.6
- ##pymongo 3.4.0
- requests 2.14.2
- lxml 3.7.2
- BeautifulSoup 4.5.3
1. First enter the main page of this crawl. You can see 12 channels on each page. There are a lot of audios under each channel, and there are many paginations in some channels. Crawl plan: Loop through 84 pages, parse each page, grab the name of each channel, picture link, and save the channel link to mongodb.
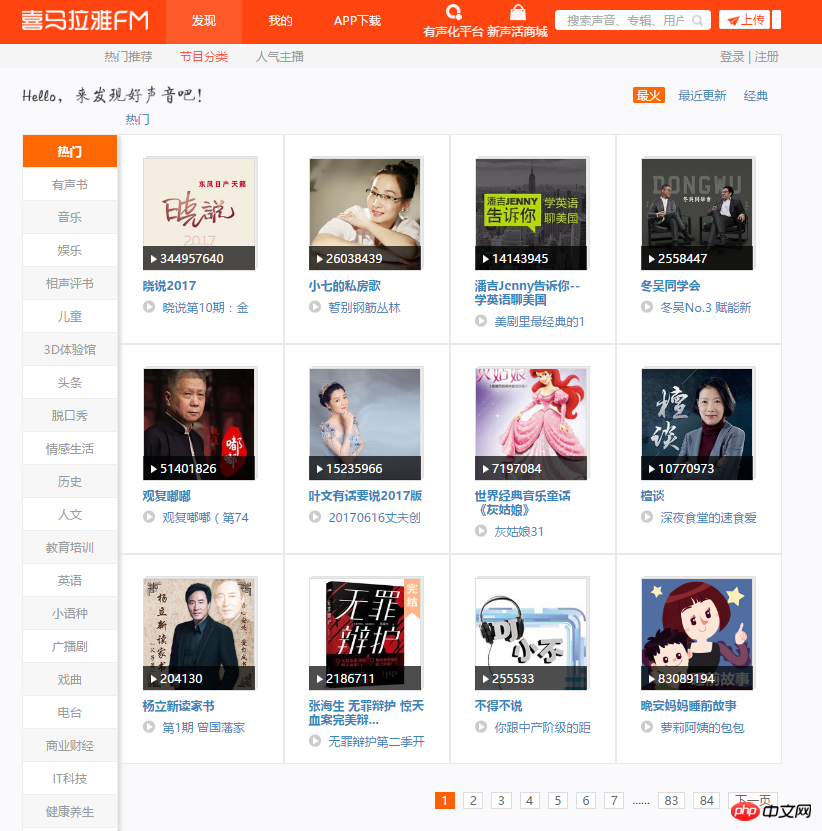 Popular Channels
Popular Channels2. Open the developer mode, analyze the page, and quickly get the location of the data you want. The following code realizes grabbing the information of all popular channels and saving it to mongodb.
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
print(content) Analysis Channel
Analysis Channel3. The following is to start to obtain all the audio data in each channel. The United States was obtained through the parsing page. Channel link. For example, we analyze the page structure after entering this link. It can be seen that each audio has a specific ID, which can be obtained from the attributes in a div. Use split() and int() to convert to individual IDs.
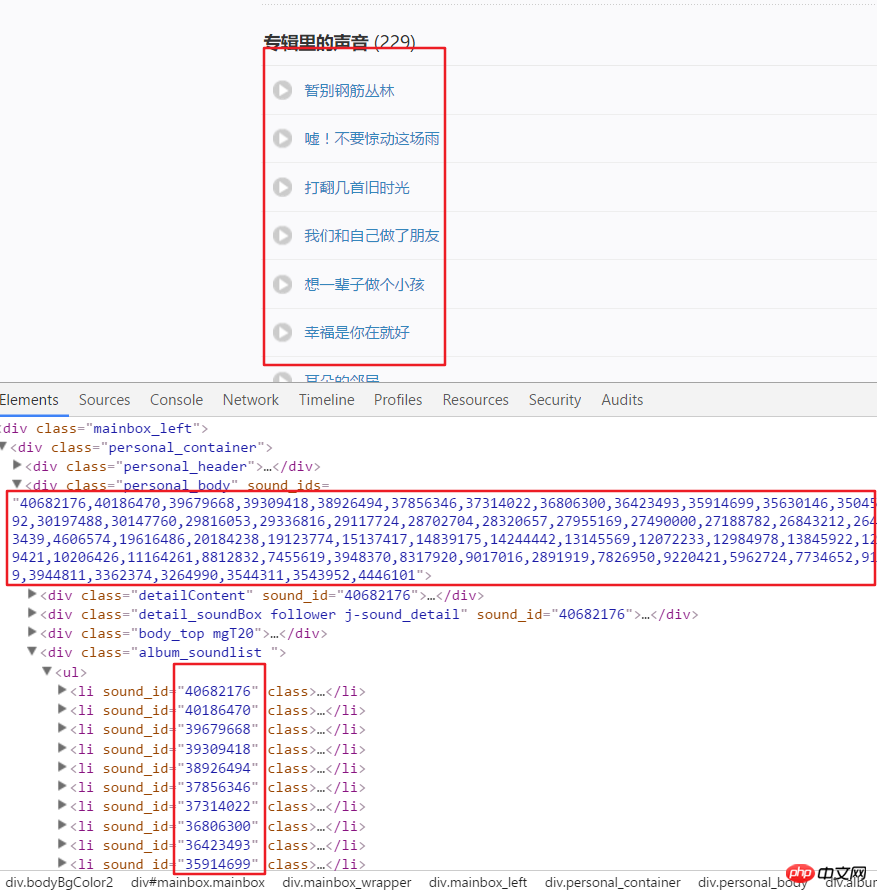 Channel page analysis
Channel page analysis4. Then click an audio link, enter developer mode, refresh the page and click XHR, then click a json The link to see this includes all the details of this audio.
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)html = requests.get(murl, headers=headers1).text
dic = json.loads(html) Audio page analysis
Audio page analysishtml = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)# 之后就接解析音频页函数就行,后面有完整代码说明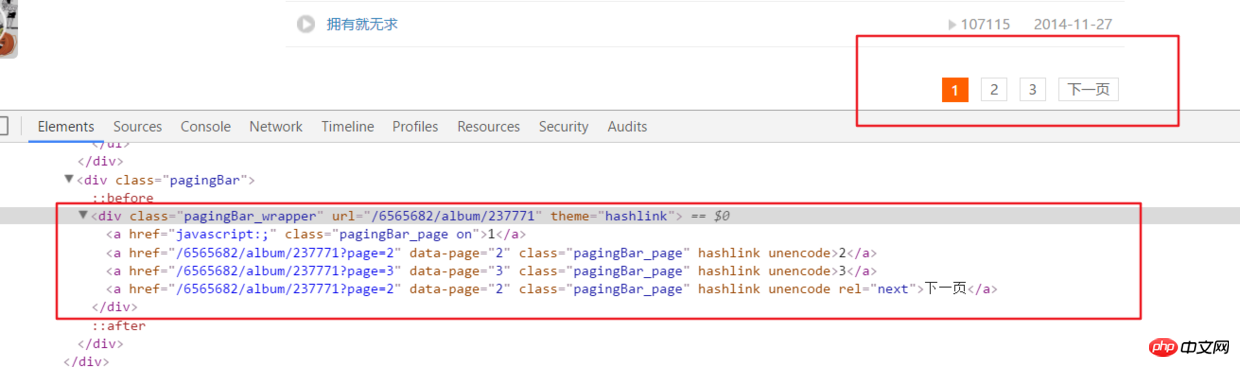 Paging
Paging6. All code
__author__ = '布咯咯_rieuse'import jsonimport randomimport timeimport pymongoimport requestsfrom bs4 import BeautifulSoupfrom lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):
content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')if __name__ == '__main__':
get_url()7. If it can be faster if it is changed to asynchronous form, just change it to the following. I tried to get nearly 100 more pieces of data per minute than normal. This source code is also in github.
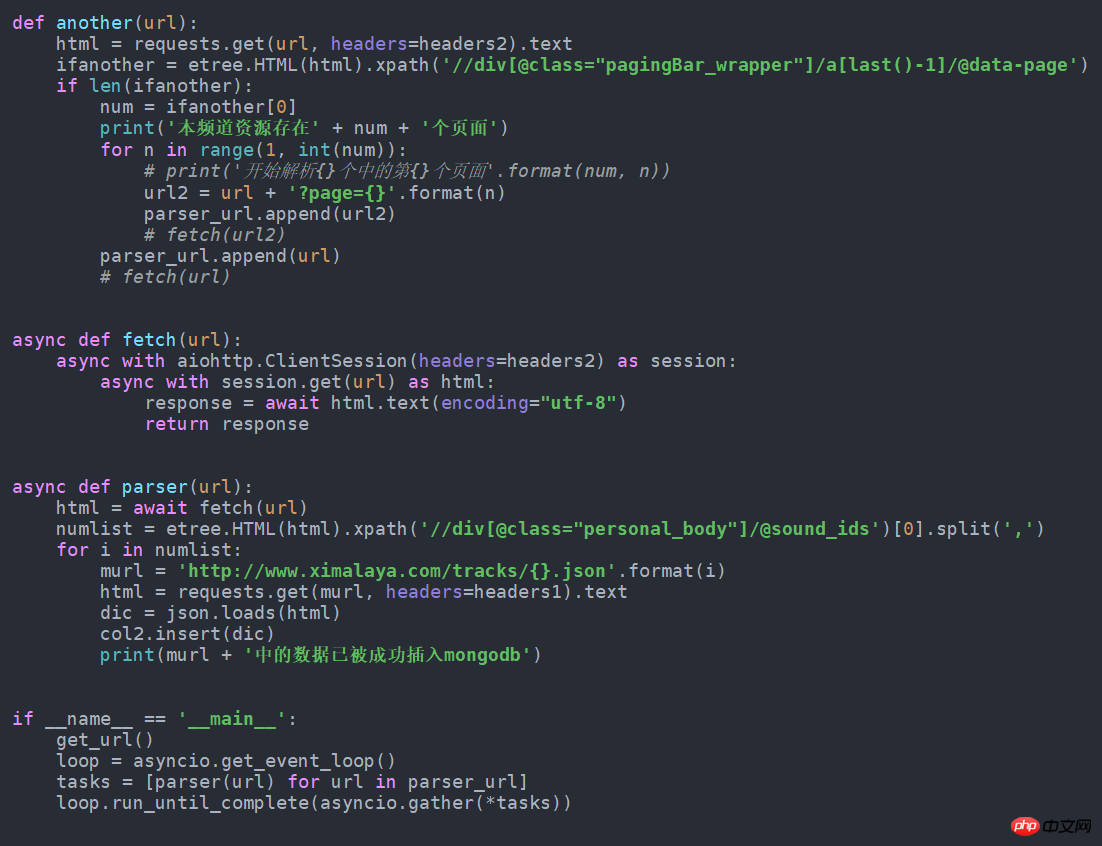 asynchronous
asynchronousThe above is the detailed content of Python crawler audio data example. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
Can vscode be used for mac
Apr 15, 2025 pm 07:36 PM
VS Code is available on Mac. It has powerful extensions, Git integration, terminal and debugger, and also offers a wealth of setup options. However, for particularly large projects or highly professional development, VS Code may have performance or functional limitations.
 Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
Can vscode run ipynb
Apr 15, 2025 pm 07:30 PM
The key to running Jupyter Notebook in VS Code is to ensure that the Python environment is properly configured, understand that the code execution order is consistent with the cell order, and be aware of large files or external libraries that may affect performance. The code completion and debugging functions provided by VS Code can greatly improve coding efficiency and reduce errors.
 Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang is more suitable for high concurrency tasks, while Python has more advantages in flexibility. 1.Golang efficiently handles concurrency through goroutine and channel. 2. Python relies on threading and asyncio, which is affected by GIL, but provides multiple concurrency methods. The choice should be based on specific needs.
