

The full name of the KNN algorithm is k-Nearest Neighbor, which means K nearest neighbor.
KNN is a classification algorithm. Its basic idea is to classify by measuring the distance between different feature values.
The algorithm process is as follows:
1. Prepare the sample data set (each data in the sample has been classified and has a classification label);
2. Use the sample data for training ;
3. Input test data A;
4. Calculate the distance between A and each data in the sample set;
5. Sort in order of increasing distance;
6. Select the distance from A The smallest k points;
7. Calculate the frequency of occurrence of the category where the first k points are located;
8. Return the category with the highest frequency of occurrence of the first k points as the predicted classification of A.
If the training set is too small, misjudgment will occur. If the training set is too large, the system overhead of classifying the test data will be very large. .
What is a suitable distance measure? A closer distance should mean that the two points are more likely to belong to the same category.
Distance measurements include:
1. Euclidean distance
The euclidean metric (also called Euclidean distance) is a commonly used distance definition , refers to the real distance between two points in m-dimensional space, or the natural length of the vector (that is, the distance from the point to the origin). The Euclidean distance in two- and three-dimensional space is the actual distance between two points.
Suitable for space problems.
2. Manhattan Distance
Taxi geometry or Manhattan Distance is a term created by Herman Minkowski in the 19th century. It is a method used in geometric metric spaces. A geometric term used to indicate the sum of the absolute axis distances of two points on the standard coordinate system. The Manhattan distance is the sum of the distances of the projections of the line segments formed by the Euclidean distance on the fixed rectangular coordinate system of the Euclidean space on the axis.
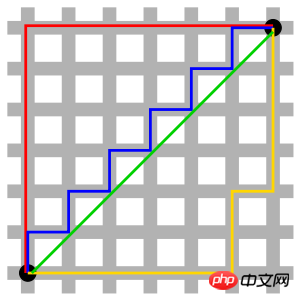
The red line in the figure represents the Manhattan distance, the green represents the Euclidean distance, which is the straight-line distance, and the blue and yellow represent the equivalent Manhattan distance. Manhattan distance - the distance between two points in the north-south direction plus the distance in the east-west direction, that is, d(i, j) = |xi-xj|+|yi-yj|.
Suitable for path problems.
3. Chebyshev distance
In mathematics, Chebyshev distance is a measure in vector space. The distance between two points is defined as the absolute difference in the numerical value of each coordinate. The maximum value.
Chebyshev distance will be used to calculate the distance between two points in the grid, such as: chessboard, warehousing and logistics applications.
For a grid, a point whose Chebyshev distance is 1 is the Moore neighborhood of this point.

Used for problems calculating distances in a grid.
4. Minkowski Distance
Min's distance is not a distance, but a definition of a set of distances.
Depending on the different variable parameters, Min's distance can represent a type of distance.
There is a variable parameter p in the formula:
When p=1, it is Manhattan distance;
When p=2, it is Euclidean distance;
When p→∞ , which is the Chebyshev distance.
5. Standardized Euclidean distance (Standardized Euclidean distance)
Standardized Euclidean distance is an improvement scheme made to address the shortcomings of simple Euclidean distance. It can be regarded as a weighted Euclidean distance.
The idea of standard Euclidean distance: Since the distribution of each dimensional component of the data is different, first "standardize" each component to have equal mean and variance.
6. Mahalanobis Distance
represents the covariance distance of the data.
It is an effective method to calculate the similarity of two unknown sample sets.
Dimensionally independent, the interference of correlation between variables can be eliminated.
7. Bhattacharyya Distance In statistics, Bhattacharyya distance is used to measure two discrete probability distributions. It is often used in classification to measure the separability between classes.
8. Hamming distance
The Hamming distance between two equal-length strings s1 and s2 is defined as the minimum amount of work required to change one of them into the other. Number of substitutions.
For example, the Hamming distance between the strings "1111" and "1001" is 2.
Application:
Information coding (in order to enhance fault tolerance, the minimum Hamming distance between codes should be made as large as possible).
9. Cosine of the included angle (Cosine)
In geometry, the cosine of the included angle can be used to measure the difference in the direction of two vectors, and in data mining, it can be used to measure the difference between sample vectors.
10. Jaccard similarity coefficient (Jaccard similarity coefficient)
The Jaccard distance uses the proportion of different elements in the two sets to all elements to measure the distinction between the two sets.
The Jaccard similarity coefficient can be used to measure the similarity of samples.
11. Pearson Correlation Coefficient
Pearson correlation coefficient, also called Pearson product-moment correlation coefficient (Pearson product-moment correlation coefficient), is a linear correlation coefficient. The Pearson correlation coefficient is a statistic used to reflect the degree of linear correlation between two variables.
The impact of high dimensions on distance measurement:
When there are more variables, the discriminating ability of Euclidean distance becomes worse.
The impact of variable value range on distance:
Variables with larger value ranges often play a dominant role in distance calculations, so the variables should be standardized first.
k is too small, the classification results are easily affected by noise points, and the error will increase;
k is too large, and the nearest neighbors may include too many other categories point (weighting the distance can reduce the impact of k value setting);
k=N (number of samples) is completely undesirable, because no matter what the input instance is at this time, it is simply predicted that it belongs to the training The class with the most instances, the model is too simple and ignores a lot of useful information in the training instances.
In practical applications, the K value generally takes a relatively small value. For example, the cross-validation method is used (in simple terms, some samples are used as the training set and some are used as the test set) to select the optimal K value. .
Rule of thumb: k is generally lower than the square root of the number of training samples.
1. Advantages
Simple, easy to understand, easy to implement, high accuracy, and not sensitive to outliers.
2. Disadvantages
KNN is a lazy algorithm. It is very simple to construct a model, but the system overhead of classifying test data is large (large amount of calculation and large memory overhead) because it requires scanning. All training samples and calculate the distance.
Numeric type and nominal type (with a finite number of different values, and there is no order between the values).
Such as customer churn prediction, fraud detection, etc.
Here we take python as an example to describe the implementation of the KNN algorithm based on Euclidean distance.
Euclidean distance formula:

Sample code taking Euclidean distance as an example:
#! /usr/bin/env python#-*- coding:utf-8 -*-# E-Mail : Mike_Zhang@live.comimport mathclass KNN: def __init__(self,trainData,trainLabel,k):
self.trainData = trainData
self.trainLabel = trainLabel
self.k = k def predict(self,inputPoint):
retLable = "None"arr=[]for vector,lable in zip(self.trainData,self.trainLabel):
s = 0for i,n in enumerate(vector) :
s += (n-inputPoint[i]) ** 2arr.append([math.sqrt(s),lable])
arr = sorted(arr,key=lambda x:x[0])[:self.k]
dtmp = {}for k,v in arr :if not v in dtmp : dtmp[v]=0
dtmp[v] += 1retLable,_ = sorted(dtmp.items(),key=lambda x:x[1],reverse=True)[0] return retLable
data = [
[1.0, 1.1],
[1.0, 1.0],
[0.0, 0.0],
[0.0, 0.1],
[1.3, 1.1],
]
labels = ['A','A','B','B','A']
knn = KNN(data,labels,3)print knn.predict([1.2, 1.1])
print knn.predict([0.2, 0.1])Above The implementation is relatively simple. You can use ready-made libraries in development, such as scikit-learn:
Recognize handwriting number
The above is the detailed content of Detailed introduction to KNN algorithm. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



