
 Backend Development
Python Tutorial
Scrapy tutorial--crawling the first N articles of a website
Backend Development
Python Tutorial
Scrapy tutorial--crawling the first N articles of a website
Scrapy tutorial--crawling the first N articles of a website
1. Top 3000 personnel list page
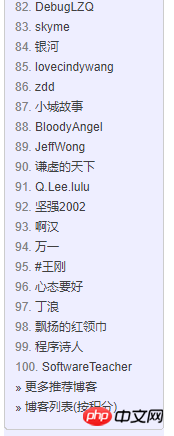

2) Analyze the page structure: Each TD is a person.
The first small is the ranking
The second a tag is the nickname and username, as well as the blog address of the homepage. The username is obtained by intercepting the address
The fourth small tag is the number of blogs and points, which can be obtained one by one after string separation.
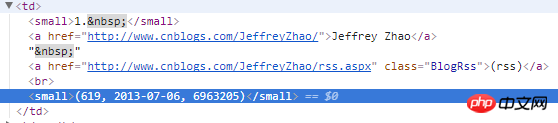
3) Code: Use xpath to obtain tags and related content. After obtaining the homepage blog address, send a request.
def parse(self, response):
for i in response.xpath("//table[@width='90%']//td"):
item = CnblogsItem()
2] .strip ()
item ['nickname'] = i.xpath ("./ a [1] // text ()"). Extract () [0] .Strip ()#item [ 'userName'] = i.xpath(
"./a[1]/@href").extract()[0].split('/')[-2].strip()
"./a[1]/@href") totalAndScore = i.xpath(
"./small[2]//text()").extract()[0].lstrip('(').rstrip(')').split(',')
item['score'] = totalAndScore[2].strip()
# print(top)
# print(nickName)
# print(userName)
# print(total)
# Print (score)
# Return
Yield scrapy.request (i.xpath ("./ a [1]/@href"). Extract () [0], meta = {'page ': 1, 'item': item},
callback=self.parse_page)
二、各人员博客列表页
1)页面结构:通过分析,每篇博客的a标签id中都包含“TitleUrl”,这样就可以获取到每篇博客的地址了。每页面地址,加上default.html?page=2,page跟着变动就可以了。

2)代码:置顶的文字会去除掉。
def parse_page(self, response):
# print(response.meta['nickName'])
#//a[contains(@id,'TitleUrl')]
urlArr = response.url.split('default.aspx?')
if len(urlArr) > 1:
baseUrl = urlArr[-2]
else:
baseUrl = response.url
list = response.xpath("//a[contains(@id,'TitleUrl')]")
for i in list:
item = CnblogsItem()
item['top'] = int(response.meta['item']['top'])
item['nickName'] = response.meta['item']['nickName']
item['userName'] = response.meta['item']['userName']
item['score'] = int(response.meta['item']['score'])
item['pageLink'] = response.url
item['title'] = i.xpath(
"./text()").extract()[0].replace(u'[置顶]', '').replace('[Top]', '').strip()
item['articleLink'] = i.xpath("./@href").extract()[0]
yield scrapy.Request(i.xpath("./@href").extract()[0], meta={'item': item}, callback=self.parse_content)
if len(list) > 0:
response.meta['page'] += 1
yield scrapy.Request(baseUrl + 'default.aspx?page=' + str(response.meta['page']), meta={'page': response.meta['page'], 'item': response.meta['item']}, callback=self.parse_page)
3)对于每篇博客的内容,这里没有抓取。也很简单,分析页面。继续发送请求,找到id为cnblogs_post_body的div就可以了。
def parse_content(self, response):
content = response.xpath("//div[@id='cnblogs_post_body']").extract()
item = response.meta['item']if len(content) == 0:
item['content'] = u'该文章已加密'else:
item['content'] = content[0]yield item
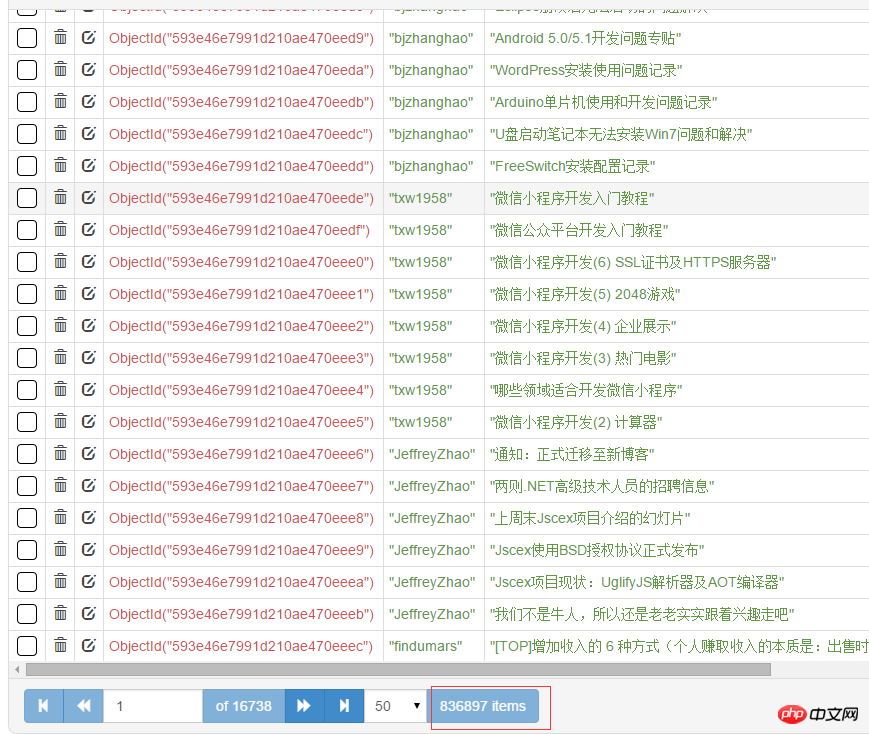
三、数据存储MongoDB
这一部分没什么难的。记着安装pymongo,pip install pymongo。总共有80+万篇文章。
from cnblogs.items import CnblogsItemimport pymongoclass CnblogsPipeline(object):def __init__(self): client = pymongo.MongoClient(host='127.0.0.1', port=27017) dbName = client['cnblogs'] self.table = dbName['articles'] self.table.createdef process_item(self, item, spider):if isinstance(item, CnblogsItem): self.table.insert(dict(item))return item
四、代理及Model类
scrapy中的代理,很简单,自定义一个下载中间件,指定一下代理ip和端口就可以了。
def process_request(self, request, spider): request.meta['proxy'] = 'http://117.143.109.173:80'
Model类,存放的是对应的字段。
class CnblogsItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 排名top = scrapy.Field() nickName = scrapy.Field() userName = scrapy.Field()# 积分score = scrapy.Field()# 所在页码地址pageLink = scrapy.Field()# 文章标题title = scrapy.Field()# 文章链接articleLink = scrapy.Field()
# 文章内容
content = scrapy.Field()
五、wordcloud词云分析
对每个人的文章进行词云分析,存储为图片。wordcloud的使用用,可参考园内文章。
这里用了多线程,一个线程用来生成分词好的txt文本,一个线程用来生成词云图片。生成词云大概,1秒一个。

# coding=utf-8import sysimport jiebafrom wordcloud import WordCloudimport pymongoimport threadingfrom Queue import Queueimport datetimeimport os
reload(sys)
sys.setdefaultencoding('utf-8')class MyThread(threading.Thread):def __init__(self, func, args):
threading.Thread.__init__(self)
self.func = func
self.args = argsdef run(self):
apply(self.func, self.args)# 获取内容 线程def getTitle(queue, table):for j in range(1, 3001):# start = datetime.datetime.now()list = table.find({'top': j}, {'title': 1, 'top': 1, 'nickName': 1})if list.count() == 0:continuetxt = ''for i in list:
txt += str(i['title']) + '\n'name = i['nickName']
top = i['top']
txt = ' '.join(jieba.cut(txt))
queue.put((txt, name, top), 1)# print((datetime.datetime.now() - start).seconds)def getImg(queue, word):for i in range(1, 3001):# start = datetime.datetime.now()get = queue.get(1)
word.generate(get[0])
name = get[1].replace('<', '').replace('>', '').replace('/', '').replace('\\', '').replace('|', '').replace(':', '').replace('"', '').replace('*', '').replace('?', '')
word.to_file('wordcloudimgs/' + str(get[2]) + '-' + str(name).decode('utf-8') + '.jpg')print(str(get[1]).decode('utf-8') + '\t生成成功')# print((datetime.datetime.now() - start).seconds)def main():
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
dbName = client['cnblogs']
table = dbName['articles']
wc = WordCloud(
font_path='msyh.ttc', background_color='#ccc', width=600, height=600)if not os.path.exists('wordcloudimgs'):
os.mkdir('wordcloudimgs')
threads = []
queue = Queue()
titleThread = MyThread(getTitle, (queue, table))
imgThread = MyThread(getImg, (queue, wc))
threads.append(imgThread)
threads.append(titleThread)for t in threads:
t.start()for t in threads:
t.join()if __name__ == "__main__":
main()六、完整源码地址
附:mongodb内存限制windows:
The above is the detailed content of Scrapy tutorial--crawling the first N articles of a website. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 Tutorial on how to use Dewu
Mar 21, 2024 pm 01:40 PM
Tutorial on how to use Dewu
Mar 21, 2024 pm 01:40 PM
Dewu APP is currently a very popular brand shopping software, but most users do not know how to use the functions in Dewu APP. The most detailed usage tutorial guide is compiled below. Next is the Dewuduo that the editor brings to users. A summary of function usage tutorials. Interested users can come and take a look! Tutorial on how to use Dewu [2024-03-20] How to use Dewu installment purchase [2024-03-20] How to obtain Dewu coupons [2024-03-20] How to find Dewu manual customer service [2024-03-20] How to check the pickup code of Dewu [2024-03-20] Where to find Dewu purchase [2024-03-20] How to open Dewu VIP [2024-03-20] How to apply for return or exchange of Dewu
 Quark browser usage tutorial
Feb 24, 2024 pm 04:10 PM
Quark browser usage tutorial
Feb 24, 2024 pm 04:10 PM
Quark Browser is a very popular multi-functional browser at the moment, but most friends don’t know how to use the functions in Quark Browser. The most commonly used functions and techniques will be sorted out below. Next, the editor will guide users. Here is a summary of the multi-functional usage tutorials of Quark Browser. Interested users can come and take a look together! Tutorial on how to use Quark Browser [2024-01-09]: How to scan test papers to see answers on Quark [2024-01-09]: How to enable adult mode on Quark Browser [2024-01-09]: How to delete used space on Quark [2024 -01-09]: How to clean up the Quark network disk storage space [2024-01-09]: How to cancel the backup of Quark [2024-01-09]: Quark
 Upgrading numpy versions: a detailed and easy-to-follow guide
Feb 25, 2024 pm 11:39 PM
Upgrading numpy versions: a detailed and easy-to-follow guide
Feb 25, 2024 pm 11:39 PM
How to upgrade numpy version: Easy-to-follow tutorial, requires concrete code examples Introduction: NumPy is an important Python library used for scientific computing. It provides a powerful multidimensional array object and a series of related functions that can be used to perform efficient numerical operations. As new versions are released, newer features and bug fixes are constantly available to us. This article will describe how to upgrade your installed NumPy library to get the latest features and resolve known issues. Step 1: Check the current NumPy version at the beginning
 Tutorial on how to turn off the payment sound on WeChat
Mar 26, 2024 am 08:30 AM
Tutorial on how to turn off the payment sound on WeChat
Mar 26, 2024 am 08:30 AM
1. First open WeChat. 2. Click [+] in the upper right corner. 3. Click the QR code to collect payment. 4. Click the three small dots in the upper right corner. 5. Click to close the voice reminder for payment arrival.
 What software is photoshopcs5? -photoshopcs5 usage tutorial
Mar 19, 2024 am 09:04 AM
What software is photoshopcs5? -photoshopcs5 usage tutorial
Mar 19, 2024 am 09:04 AM
PhotoshopCS is the abbreviation of Photoshop Creative Suite. It is a software produced by Adobe and is widely used in graphic design and image processing. As a novice learning PS, let me explain to you today what software photoshopcs5 is and how to use photoshopcs5. 1. What software is photoshop cs5? Adobe Photoshop CS5 Extended is ideal for professionals in film, video and multimedia fields, graphic and web designers who use 3D and animation, and professionals in engineering and scientific fields. Render a 3D image and merge it into a 2D composite image. Edit videos easily
 DisplayX (monitor testing software) tutorial
Mar 04, 2024 pm 04:00 PM
DisplayX (monitor testing software) tutorial
Mar 04, 2024 pm 04:00 PM
Testing a monitor when buying it is an essential part to avoid buying a damaged one. Today I will teach you how to use software to test the monitor. Method step 1. First, search and download the DisplayX software on this website, install it and open it, and you will see many detection methods provided to users. 2. The user clicks on the regular complete test. The first step is to test the brightness of the display. The user adjusts the display so that the boxes can be seen clearly. 3. Then click the mouse to enter the next link. If the monitor can distinguish each black and white area, it means the monitor is still good. 4. Click the left mouse button again, and you will see the grayscale test of the monitor. The smoother the color transition, the better the monitor. 5. In addition, in the displayx software we
 Experts teach you! The Correct Way to Cut Long Pictures on Huawei Mobile Phones
Mar 22, 2024 pm 12:21 PM
Experts teach you! The Correct Way to Cut Long Pictures on Huawei Mobile Phones
Mar 22, 2024 pm 12:21 PM
With the continuous development of smart phones, the functions of mobile phones have become more and more powerful, among which the function of taking long pictures has become one of the important functions used by many users in daily life. Long screenshots can help users save a long web page, conversation record or picture at one time for easy viewing and sharing. Among many mobile phone brands, Huawei mobile phones are also one of the brands highly respected by users, and their function of cropping long pictures is also highly praised. This article will introduce you to the correct method of taking long pictures on Huawei mobile phones, as well as some expert tips to help you make better use of Huawei mobile phones.
 In summer, you must try shooting a rainbow
Jul 21, 2024 pm 05:16 PM
In summer, you must try shooting a rainbow
Jul 21, 2024 pm 05:16 PM
After rain in summer, you can often see a beautiful and magical special weather scene - rainbow. This is also a rare scene that can be encountered in photography, and it is very photogenic. There are several conditions for a rainbow to appear: first, there are enough water droplets in the air, and second, the sun shines at a low angle. Therefore, it is easiest to see a rainbow in the afternoon after the rain has cleared up. However, the formation of a rainbow is greatly affected by weather, light and other conditions, so it generally only lasts for a short period of time, and the best viewing and shooting time is even shorter. So when you encounter a rainbow, how can you properly record it and photograph it with quality? 1. Look for rainbows. In addition to the conditions mentioned above, rainbows usually appear in the direction of sunlight, that is, if the sun shines from west to east, rainbows are more likely to appear in the east.
