

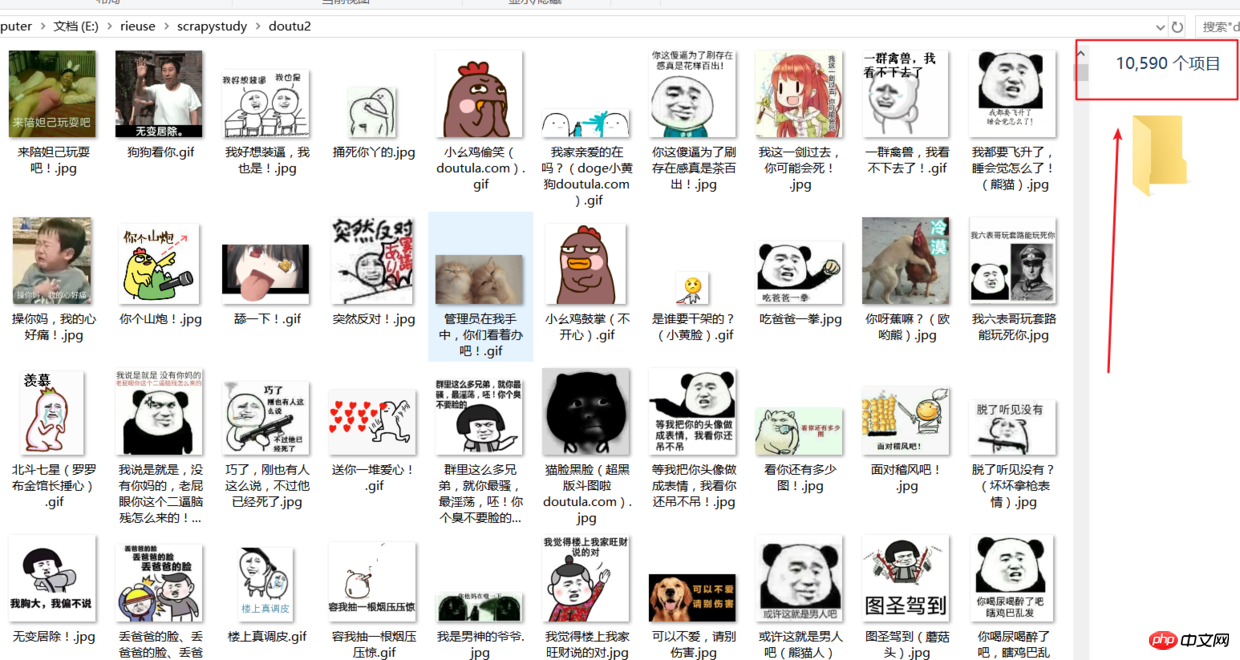
I encountered many pitfalls when using the Scrapy framework for the first time. I persisted in searching and modified the code to solve it. question. This time, we crawled the latest emoticon pictures www.doutula.com/photo/list of a DouTu website. We practiced using the Scrapy framework and used a random user agent to prevent being banned. The DouTu emoticon package is updated daily and can be crawled in total. About 50,000 expressions are stored in the hard drive. To save time, I grabbed more than 10,000 pictures.
Scrapy is an application framework written to crawl website data and extract structural data. It can be used in a series of programs including data mining, information processing or storing historical data.
Use the process
Create a Scrapy project
Define the extracted Item
Write a spider that crawls the website and extracts Item
Write an Item Pipeline to store the extracted Item (that is, data)
The following diagram shows Scrapy’s architecture, including an overview of the components and data flows that occur in the system (shown by the green arrow). Below is a brief introduction to each component, with links to detailed content. The data flow is described below
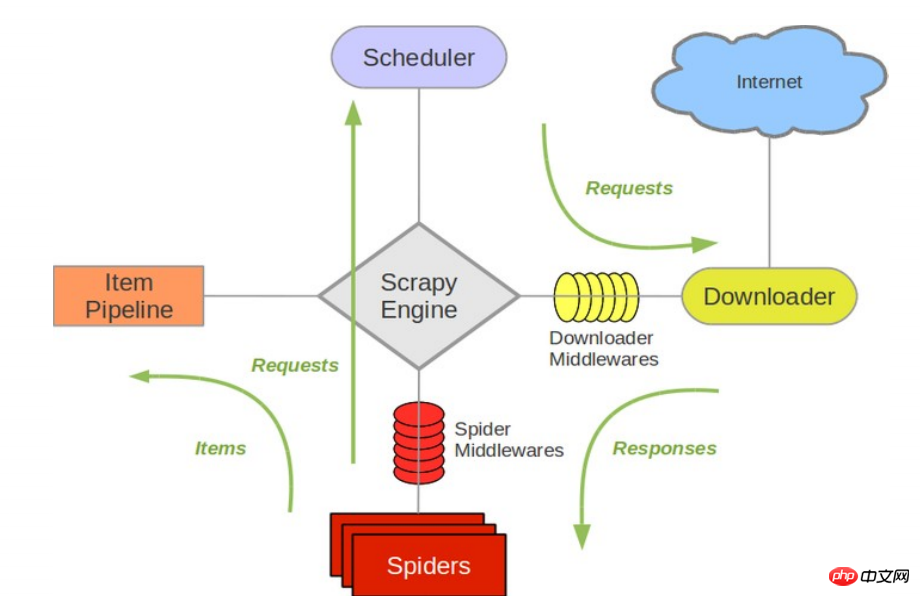
Component
Scrapy Engine
The engine is responsible for controlling the flow of data through all components in the system and triggering events when corresponding actions occur. See the Data Flow section below for details.
Scheduler (Scheduler)
The scheduler accepts requests from the engine and enqueues them so that they can be provided to the engine when the engine requests them later.
Downloader(Downloader)
The downloader is responsible for obtaining page data and providing it to the engine, and then to the spider.
Spiders
Spider is a class written by Scrapy users to analyze the response and extract the item (that is, the obtained item) or additional follow-up URL. Each spider is responsible for processing a specific (or a few) websites. See Spiders for more.
Item Pipeline
Item Pipeline is responsible for processing the items extracted by the spider. Typical processes include cleanup, validation, and persistence (such as accessing to a database). See Item Pipeline for more information.
Downloader middleware (Downloader middlewares)
Downloader middleware is a specific hook between the engine and the downloader, which handles the response passed by the Downloader to the engine. . It provides a simple mechanism to extend Scrapy functionality by inserting custom code. For more information, please see Downloader Middleware.
Spider middleware (Spider middlewares)
Spider middleware is a specific hook (specific hook) between the engine and the Spider, processing the spider's input (response) and output ( items and requests). It provides a simple mechanism to extend Scrapy functionality by inserting custom code. For more information, please see Spider middleware (Middleware).
1. After entering the latest Dou Tu emoticon from the homepage of the website, the URL is . After clicking on the second page, you will see that the URL becomes , then we know the composition of the URL. The last page is the number of different pages. Then the start_urls starting entry in spider is defined as follows, crawling 1 to 20 pages of image expressions. If you want to download more emoticon pages, you can add more.
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 20)]2. Enter the developer mode to analyze the structure of the web page. You can see the following structure. Right-click and copy the xpath address to get the a tag content where all the expressions are located. a[1] represents the first a, and removing [1] is all a.
//*[@id="pic-detail"]/div/div[1]/div[2]/a
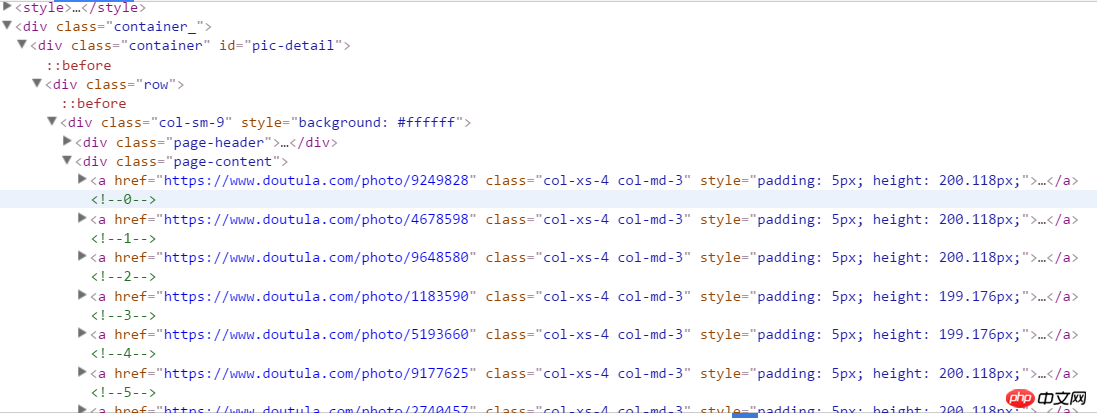
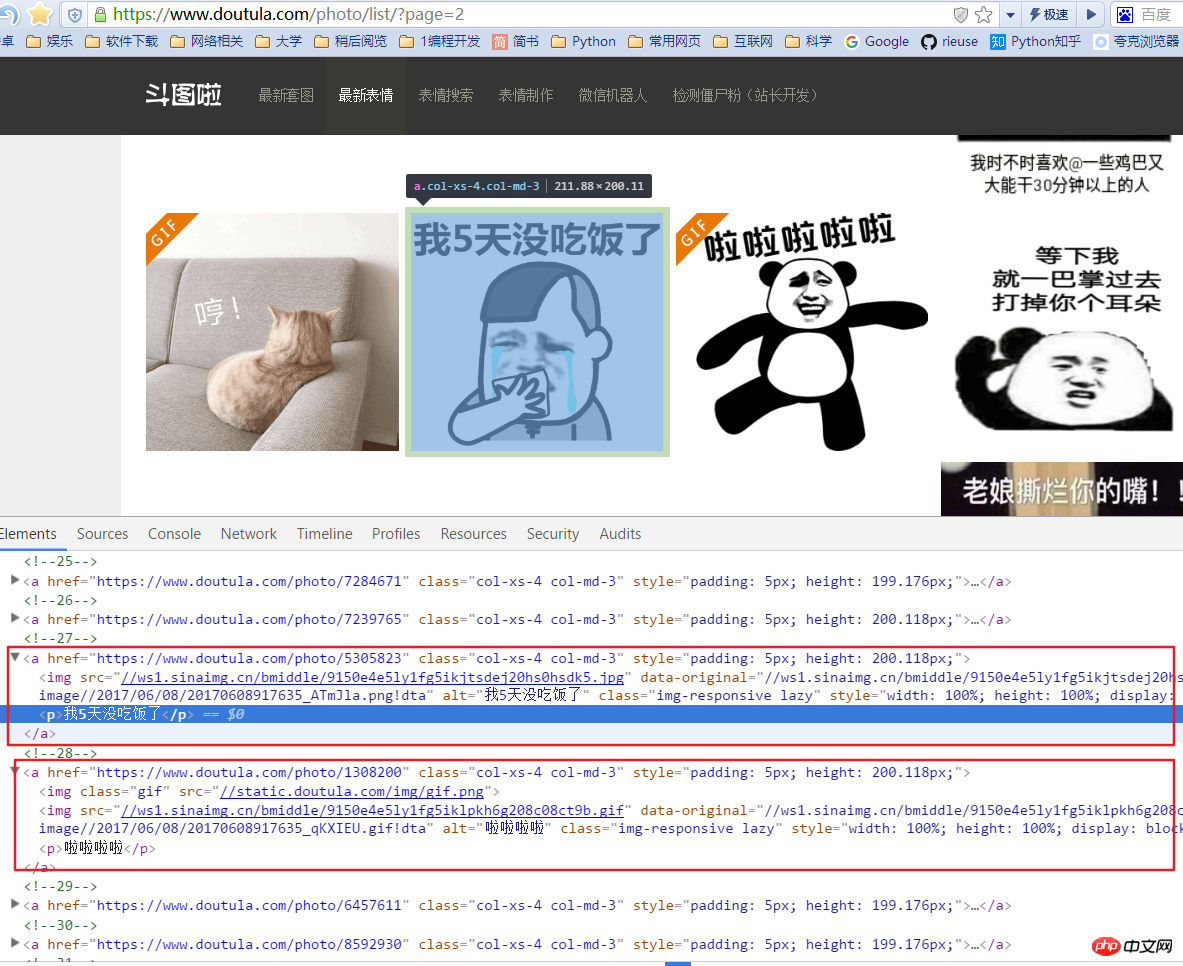
It is worth noting that there are two kinds of expressions here: one jpg and one gif. If you only grab the src of the first img under the a tag when getting the image address, an error will occur, so we need to grab the data-original value in the img. Here, there is a p tag under the a tag, which is the image introduction, and we also grab it as the name of the image file.
图片的连接是 'http:' + content.xpath('//img/@data-original') 图片的名称是 content.xpath('//p/text()')
完整代码地址 github.com/rieuse/learnPython
1.首先使用命令行工具输入代码创建一个新的Scrapy项目,之后创建一个爬虫。
scrapy startproject ScrapyDoutu cd ScrapyDoutu\ScrapyDoutu\spidersscrapy genspider doutula doutula.com
2.打开Doutu文件夹中的items.py,改为以下代码,定义我们爬取的项目。
import scrapyclass DoutuItem(scrapy.Item):
img_url = scrapy.Field()
name = scrapy.Field()3.打开spiders文件夹中的doutula.py,改为以下代码,这个是爬虫主程序。
# -*- coding: utf-8 -*-
import os
import scrapy
import requestsfrom ScrapyDoutu.items import DoutuItems
class Doutu(scrapy.Spider):
name = "doutu"
allowed_domains = ["doutula.com", "sinaimg.cn"]
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 40)] # 我们暂且爬取40页图片
def parse(self, response):
i = 0for content in response.xpath('//*[@id="pic-detail"]/div/div[1]/div[2]/a'):
i += 1item = DoutuItems()item['img_url'] = 'http:' + content.xpath('//img/@data-original').extract()[i]item['name'] = content.xpath('//p/text()').extract()[i]try:if not os.path.exists('doutu'):
os.makedirs('doutu')
r = requests.get(item['img_url'])
filename = 'doutu\\{}'.format(item['name']) + item['img_url'][-4:]with open(filename, 'wb') as fo:
fo.write(r.content)
except:
print('Error')
yield item3.这里面有很多值得注意的部分:
因为图片的地址是放在sinaimg.cn中,所以要加入allowed_domains的列表中
content.xpath('//img/@data-original').extract()[i]中extract()用来返回一个list(就是系统自带的那个) 里面是一些你提取的内容,[i]是结合前面的i的循环每次获取下一个标签内容,如果不这样设置,就会把全部的标签内容放入一个字典的值中。
filename = 'doutu\{}'.format(item['name']) + item['img_url'][-4:] 是用来获取图片的名称,最后item['img_url'][-4:]是获取图片地址的最后四位这样就可以保证不同的文件格式使用各自的后缀。
最后一点就是如果xpath没有正确匹配,则会出现
4.配置settings.py,如果想抓取快一点CONCURRENT_REQUESTS设置大一些,DOWNLOAD_DELAY设置小一些,或者为0.
# -*- coding: utf-8 -*-BOT_NAME = 'ScrapyDoutu'SPIDER_MODULES = ['ScrapyDoutu.spiders']NEWSPIDER_MODULE = 'ScrapyDoutu.spiders'DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'ScrapyDoutu.middlewares.RotateUserAgentMiddleware': 400,
}ROBOTSTXT_OBEY = False # 不遵循网站的robots.txt策略CONCURRENT_REQUESTS = 16 #Scrapy downloader 并发请求(concurrent requests)的最大值DOWNLOAD_DELAY = 0.2 # 下载同一个网站页面前等待的时间,可以用来限制爬取速度减轻服务器压力。COOKIES_ENABLED = False # 关闭cookies5.配置middleware.py配合settings中的UA设置可以在下载中随机选择UA有一定的反ban效果,在原有代码基础上加入下面代码。这里的user_agent_list可以加入更多。
import randomfrom scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareclass RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.user_agent_list)
if ua:
print(ua)
request.headers.setdefault('User-Agent', ua)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]6.到现在为止,代码都已经完成了。那么开始执行吧!scrapy crawl doutu
之后可以看到一边下载,一边修改User Agent。
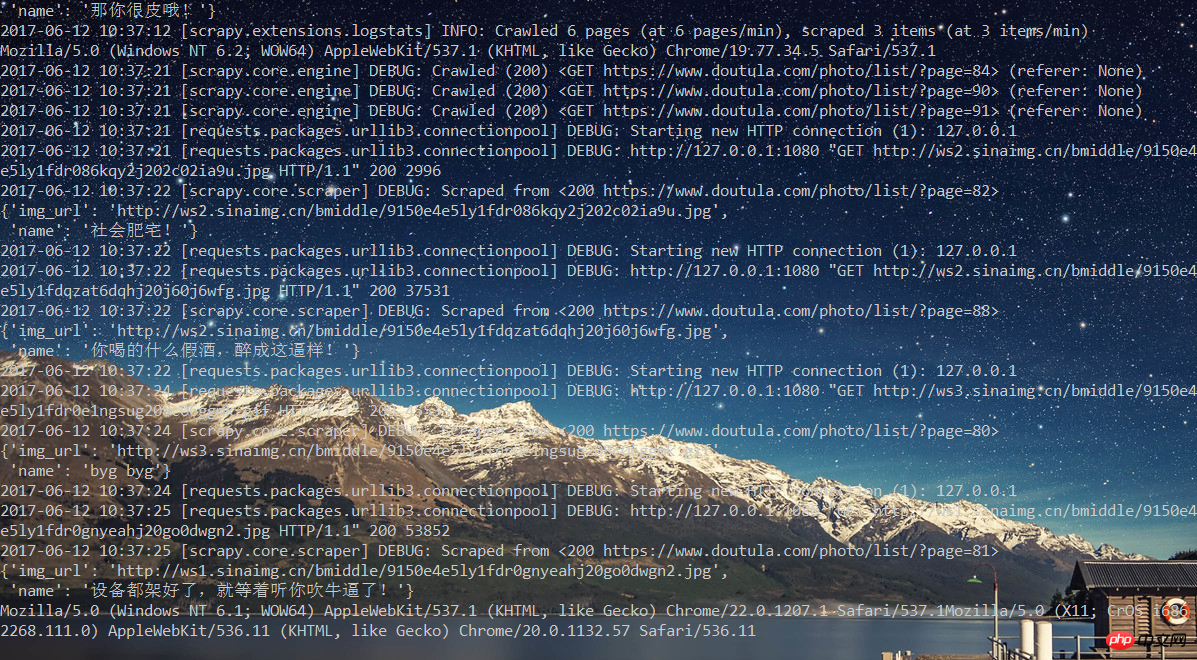
学习使用Scrapy遇到很多坑,但是强大的搜索系统不会让我感觉孤单。所以感觉Scrapy还是很强大的也很意思,后面继续学习Scrapy的其他方面内容。
The above is the detailed content of How to grab the latest emoticons from DouTu.com?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



