

How to do a good web crawler?

The essence of web crawlers is actually to "steal" data from the Internet. Through web crawlers, we can collect the resources we need, but similarly, improper use may also cause some serious problems.
Therefore, when using web crawlers, we need to be able to "steal in the right way".
Web crawlers are mainly divided into the following three categories:
1. Small scale, small amount of data, and insensitive crawling speed; for this We can use the Requests library to implement web crawlers, which are mainly used to crawl web pages;
2. Medium scale, with large data scale and sensitive crawling speed; for this type of web crawler, we can use the Scrapy library. Implementation, mainly used to crawl websites or series of websites;
3. Large scale, search engine, crawling speed is key; at this time, customized development is required, mainly used to crawl the entire network, usually to build the entire network Search engines, such as Baidu, Google search, etc.
Among these three types, the first one is the most common, and most of them are small-scale crawlers that crawl web pages.
There are also many objections to web crawlers. Because web crawlers will constantly send requests to the server, affecting server performance, causing harassment to the server, and increasing the workload of website maintainers.
In addition to harassment of servers, web crawlers may also cause legal risks. Because the data on the server has property rights, if the data is used for profit, it will bring legal risks.
In addition, web crawlers may also cause user privacy leaks.
In short, the risks of web crawlers are mainly attributed to the following three points:
Performance of the server Harassment
Legal risks at the content level
Leakage of personal privacy
Therefore, web crawlers The use requires certain rules.
In actual situations, some larger websites have imposed relevant restrictions on web crawlers, and web crawlers are also regarded as a standardizable function on the entire Internet.
For general servers, we can limit web crawlers in two ways:
1. If the owner of the website has Certain technical capabilities to limit web crawlers through source review.
Source review is generally restricted by judging User-Agent. This article focuses on the second type.
2. Use the Robots protocol to tell web crawlers the rules they need to abide by, which ones can be crawled, and which ones are not allowed, and require all crawlers to comply with this protocol.
The second method is to inform in the form of an announcement. The Robots Agreement is a recommendation but not binding. Web crawlers may not comply, but there may be legal risks. Through these two methods, effective moral and technical restrictions on web crawlers are formed on the Internet.
Then, When we write a web crawler, we need to respect the management of website resources by the website maintainers.
On the Internet, some websites do not have the Robots protocol, and all data can be crawled; however, the vast majority of mainstream websites support the Robots protocol and have relevant restrictions. The following is a detailed introduction to the Robots protocol. basic syntax.
Robots protocol (Robots Exclusion Standard, web crawler exclusion standard):
Function: The website tells web crawlers which pages can be crawled and which no.
Format: robots.txt file in the root directory of the website.
Basic syntax of Robots protocol: * represents all, / represents the root directory.
For example, PMCAFF's Robots protocol:
User-agent: *
Disallow: /article/edit
Disallow: /discuss/write
Disallow: /discuss/edit
In line 1 User-agent:* means that all web crawlers need to abide by the following protocols;
Disallow: /article/edit in line 2 means that all web crawlers are not allowed to access articles under article/edit Content, the same applies to others.
If you observe Jingdong’s Robots protocol, you can see that there is User-agent: EtaoSpider, Disallow: /, where EtaoSpider is a malicious crawler and is not allowed to crawl any resources of Jingdong.
User-agent: *
Disallow: /?*
Disallow: /pop /*.html
Disallow: /pinpai/*.html?*
User-agent: EtaoSpider
Disallow: /
User-agent: HuihuiSpider
Disallow: /
User-agent: GwdangSpider
Disallow: /
User-agent: WochachaSpider
Disallow: /
With the Robots protocol, you can regulate the content of the website and tell all web crawlers which ones can be crawled and which ones are not allowed.
It is important to note that the Robots protocol exists in the root directory. Different root directories may have different Robots protocols, so you need to pay more attention when crawling.
The above is the detailed content of How to do a good web crawler?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

![WLAN expansion module has stopped [fix]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN expansion module has stopped [fix]
Feb 19, 2024 pm 02:18 PM
WLAN expansion module has stopped [fix]
Feb 19, 2024 pm 02:18 PM
If there is a problem with the WLAN expansion module on your Windows computer, it may cause you to be disconnected from the Internet. This situation is often frustrating, but fortunately, this article provides some simple suggestions that can help you solve this problem and get your wireless connection working properly again. Fix WLAN Extensibility Module Has Stopped If the WLAN Extensibility Module has stopped working on your Windows computer, follow these suggestions to fix it: Run the Network and Internet Troubleshooter to disable and re-enable wireless network connections Restart the WLAN Autoconfiguration Service Modify Power Options Modify Advanced Power Settings Reinstall Network Adapter Driver Run Some Network Commands Now, let’s look at it in detail
 How to solve win11 DNS server error
Jan 10, 2024 pm 09:02 PM
How to solve win11 DNS server error
Jan 10, 2024 pm 09:02 PM
We need to use the correct DNS when connecting to the Internet to access the Internet. In the same way, if we use the wrong dns settings, it will prompt a dns server error. At this time, we can try to solve the problem by selecting to automatically obtain dns in the network settings. Let’s take a look at the specific solutions. How to solve win11 network dns server error. Method 1: Reset DNS 1. First, click Start in the taskbar to enter, find and click the "Settings" icon button. 2. Then click the "Network & Internet" option command in the left column. 3. Then find the "Ethernet" option on the right and click to enter. 4. After that, click "Edit" in the DNS server assignment, and finally set DNS to "Automatic (D
 Fix 'Failed Network Error' downloads on Chrome, Google Drive and Photos!
Oct 27, 2023 pm 11:13 PM
Fix 'Failed Network Error' downloads on Chrome, Google Drive and Photos!
Oct 27, 2023 pm 11:13 PM
What is the "Network error download failed" issue? Before we delve into the solutions, let’s first understand what the “Network Error Download Failed” issue means. This error usually occurs when the network connection is interrupted during downloading. It can happen due to various reasons such as weak internet connection, network congestion or server issues. When this error occurs, the download will stop and an error message will be displayed. How to fix failed download with network error? Facing “Network Error Download Failed” can become a hindrance while accessing or downloading necessary files. Whether you are using browsers like Chrome or platforms like Google Drive and Google Photos, this error will pop up causing inconvenience. Below are points to help you navigate and resolve this issue
 Fix: WD My Cloud doesn't show up on the network in Windows 11
Oct 02, 2023 pm 11:21 PM
Fix: WD My Cloud doesn't show up on the network in Windows 11
Oct 02, 2023 pm 11:21 PM
If WDMyCloud is not showing up on the network in Windows 11, this can be a big problem, especially if you store backups or other important files in it. This can be a big problem for users who frequently need to access network storage, so in today's guide, we'll show you how to fix this problem permanently. Why doesn't WDMyCloud show up on Windows 11 network? Your MyCloud device, network adapter, or internet connection is not configured correctly. The SMB function is not installed on the computer. A temporary glitch in Winsock can sometimes cause this problem. What should I do if my cloud doesn't show up on the network? Before we start fixing the problem, you can perform some preliminary checks:
 What should I do if the earth is displayed in the lower right corner of Windows 10 when I cannot access the Internet? Various solutions to the problem that the Earth cannot access the Internet in Win10
Feb 29, 2024 am 09:52 AM
What should I do if the earth is displayed in the lower right corner of Windows 10 when I cannot access the Internet? Various solutions to the problem that the Earth cannot access the Internet in Win10
Feb 29, 2024 am 09:52 AM
This article will introduce the solution to the problem that the globe symbol is displayed on the Win10 system network but cannot access the Internet. The article will provide detailed steps to help readers solve the problem of Win10 network showing that the earth cannot access the Internet. Method 1: Restart directly. First check whether the network cable is not plugged in properly and whether the broadband is in arrears. The router or optical modem may be stuck. In this case, you need to restart the router or optical modem. If there are no important things being done on the computer, you can restart the computer directly. Most minor problems can be quickly solved by restarting the computer. If it is determined that the broadband is not in arrears and the network is normal, that is another matter. Method 2: 1. Press the [Win] key, or click [Start Menu] in the lower left corner. In the menu item that opens, click the gear icon above the power button. This is [Settings].
 Check network connection: lol cannot connect to the server
Feb 19, 2024 pm 12:10 PM
Check network connection: lol cannot connect to the server
Feb 19, 2024 pm 12:10 PM
LOL cannot connect to the server, please check the network. In recent years, online games have become a daily entertainment activity for many people. Among them, League of Legends (LOL) is a very popular multiplayer online game, attracting the participation and interest of hundreds of millions of players. However, sometimes when we play LOL, we will encounter the error message "Unable to connect to the server, please check the network", which undoubtedly brings some trouble to players. Next, we will discuss the causes and solutions of this error. First of all, the problem that LOL cannot connect to the server may be
 What's going on when the network can't connect to the wifi?
Apr 03, 2024 pm 12:11 PM
What's going on when the network can't connect to the wifi?
Apr 03, 2024 pm 12:11 PM
1. Check the wifi password: Make sure the wifi password you entered is correct and pay attention to case sensitivity. 2. Confirm whether the wifi is working properly: Check whether the wifi router is running normally. You can connect other devices to the same router to determine whether the problem lies with the device. 3. Restart the device and router: Sometimes, there is a malfunction or network problem with the device or router, and restarting the device and router may solve the problem. 4. Check the device settings: Make sure the wireless function of the device is turned on and the wifi function is not disabled.
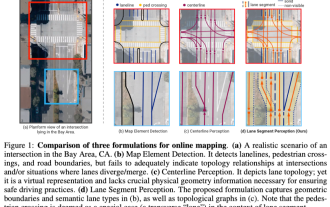 ICLR'24 new ideas without pictures! LaneSegNet: map learning based on lane segmentation awareness
Jan 19, 2024 am 11:12 AM
ICLR'24 new ideas without pictures! LaneSegNet: map learning based on lane segmentation awareness
Jan 19, 2024 am 11:12 AM
Written above & The author’s personal understanding of maps as key information for downstream applications of autonomous driving systems is usually represented by lanes or center lines. However, the existing map learning literature mainly focuses on detecting geometry-based topological relationships of lanes or sensing centerlines. Both methods ignore the inherent relationship between lane lines and center lines, that is, lane lines bind center lines. Although simply predicting two types of lanes in one model are mutually exclusive in the learning objective, this paper proposes lanesegment as a new representation that seamlessly combines geometric and topological information, thus proposing LaneSegNet. This is the first end-to-end mapping network that generates lanesegments to obtain a complete representation of road structure. LaneSegNet has two levels
