

node.js require() source code interpretation_node.js

In 2009, the Node.js project was born, and all modules are in the CommonJS format.
Today, the Node.js module warehouse npmjs.com has stored 150,000 modules, most of which are in CommonJS format.
The core of this format is the require statement, through which modules are loaded. When learning Node.js, you must learn how to use the require statement. Through source code analysis, this article introduces the internal operating mechanism of the require statement in detail to help you understand the module mechanism of Node.js.
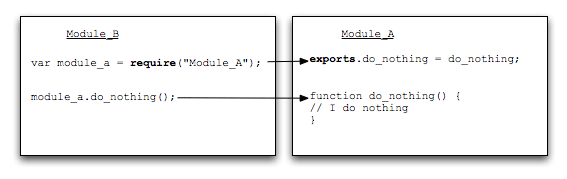
1. Basic usage of require()
Before analyzing the source code, let’s first introduce the internal logic of the require statement. If you just want to know how to use require, just read this paragraph.
The following content is translated from "Node User Manual" .
When Node encounters require(X), it is processed in the following order.
(1) If X is a built-in module (such as require('http'))
a. Return to the module.
b. No further execution.
(2) If X starts with "./" or "/" or "../"
a. Determine the absolute path of X based on the parent module where X is located.
b. Treat
X
X.js
X.json
X.node
c. Treat
X/package.json (main field)
X/index.js
X/index.json
X/index.node
(3) If X does not have a path
a. Determine the possible installation directory of X based on the parent module where X is located.
b. In each directory in turn, load X as a file name or directory name.
(4) Throw "not found"
Please see an example.
The current script file /home/ry/projects/foo.js executes require('bar') , which belongs to the third situation above. The internal operation process of Node is as follows.
First, determine that the absolute path of x may be the following locations, and search each directory in turn.
/home/ry/projects/node_modules/bar
/home/ry/node_modules/bar
/home/node_modules/bar
/node_modules/bar
When searching, Node first treats bar as the file name, tries to load the following files in sequence, and returns as long as one of them succeeds.
bar bar.js bar.json bar.node
If neither succeeds, it means that bar may be a directory name, so try to load the following files in sequence.
bar/package.json (main field)
bar/index.js
bar/index.json
bar/index.node
If the file or directory corresponding to bar cannot be found in any directory, an error will be thrown.
2. Module constructor
After understanding the internal logic, let’s look at the source code.
require is in Node’s lib/module.js file. For ease of understanding, the source code quoted in this article has been simplified and the original author's comments have been deleted.
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;
var module = new Module(filename, parent);
In the above code, Node defines a constructor Module, and all modules are instances of Module. As you can see, the current module (module.js) is also an instance of Module.
Each instance has its own properties. Let's take an example to see what the values of these attributes are. Create a new script file a.js.
// a.js
console.log('module.id: ', module.id);
console.log('module.exports: ', module.exports);
console.log('module.parent: ', module.parent);
console.log('module.filename: ', module.filename);
console.log('module.loaded: ', module.loaded);
console.log('module.children: ', module.children);
console.log('module.paths: ', module.paths);Run this script.
$ node a.js
module.id: .
module.exports: {}
module.parent: null
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
可以看到,如果没有父模块,直接调用当前模块,parent 属性就是 null,id 属性就是一个点。filename 属性是模块的绝对路径,path 属性是一个数组,包含了模块可能的位置。另外,输出这些内容时,模块还没有全部加载,所以 loaded 属性为 false 。
新建另一个脚本文件 b.js,让其调用 a.js 。
// b.js
var a = require('./a.js');运行 b.js 。
$ node b.js
module.id: /home/ruanyf/tmp/a.js
module.exports: {}
module.parent: { object }
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
上面代码中,由于 a.js 被 b.js 调用,所以 parent 属性指向 b.js 模块,id 属性和 filename 属性一致,都是模块的绝对路径。
三、模块实例的 require 方法
每个模块实例都有一个 require 方法。
Module.prototype.require = function(path) {
return Module._load(path, this);
};由此可知,require 并不是全局性命令,而是每个模块提供的一个内部方法,也就是说,只有在模块内部才能使用 require 命令(唯一的例外是 REPL 环境)。另外,require 其实内部调用 Module._load 方法。
下面来看 Module._load 的源码。
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
// 第三步:生成模块实例,存入缓存
var module = new Module(filename, parent);
Module._cache[filename] = module;
// 第四步:加载模块
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
上面代码中,首先解析出模块的绝对路径(filename),以它作为模块的识别符。然后,如果模块已经在缓存中,就从缓存取出;如果不在缓存中,就加载模块。
因此,Module._load 的关键步骤是两个。
◾Module._resolveFilename() :确定模块的绝对路径
◾module.load():加载模块
四、模块的绝对路径
下面是 Module._resolveFilename 方法的源码。
Module._resolveFilename = function(request, parent) {
// 第一步:如果是内置模块,不含路径返回
if (NativeModule.exists(request)) {
return request;
}
// 第二步:确定所有可能的路径
var resolvedModule = Module._resolveLookupPaths(request, parent);
var id = resolvedModule[0];
var paths = resolvedModule[1];
// 第三步:确定哪一个路径为真
var filename = Module._findPath(request, paths);
if (!filename) {
var err = new Error("Cannot find module '" + request + "'");
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
};
上面代码中,在 Module.resolveFilename 方法内部,又调用了两个方法 Module.resolveLookupPaths() 和 Module._findPath() ,前者用来列出可能的路径,后者用来确认哪一个路径为真。
为了简洁起见,这里只给出 Module._resolveLookupPaths() 的运行结果。
[ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules'
'/home/ruanyf/.node_modules',
'/home/ruanyf/.node_libraries',
'$Prefix/lib/node' ]
上面的数组,就是模块所有可能的路径。基本上是,从当前路径开始一级级向上寻找 node_modules 子目录。最后那三个路径,主要是为了历史原因保持兼容,实际上已经很少用了。
有了可能的路径以后,下面就是 Module._findPath() 的源码,用来确定到底哪一个是正确路径。
Module._findPath = function(request, paths) {
// 列出所有可能的后缀名:.js,.json, .node
var exts = Object.keys(Module._extensions);
// 如果是绝对路径,就不再搜索
if (request.charAt(0) === '/') {
paths = [''];
}
// 是否有后缀的目录斜杠
var trailingSlash = (request.slice(-1) === '/');
// 第一步:如果当前路径已在缓存中,就直接返回缓存
var cacheKey = JSON.stringify({request: request, paths: paths});
if (Module._pathCache[cacheKey]) {
return Module._pathCache[cacheKey];
}
// 第二步:依次遍历所有路径
for (var i = 0, PL = paths.length; i < PL; i++) {
var basePath = path.resolve(paths[i], request);
var filename;
if (!trailingSlash) {
// 第三步:是否存在该模块文件
filename = tryFile(basePath);
if (!filename && !trailingSlash) {
// 第四步:该模块文件加上后缀名,是否存在
filename = tryExtensions(basePath, exts);
}
}
// 第五步:目录中是否存在 package.json
if (!filename) {
filename = tryPackage(basePath, exts);
}
if (!filename) {
// 第六步:是否存在目录名 + index + 后缀名
filename = tryExtensions(path.resolve(basePath, 'index'), exts);
}
// 第七步:将找到的文件路径存入返回缓存,然后返回
if (filename) {
Module._pathCache[cacheKey] = filename;
return filename;
}
}
// 第八步:没有找到文件,返回false
return false;
};
经过上面代码,就可以找到模块的绝对路径了。
有时在项目代码中,需要调用模块的绝对路径,那么除了 module.filename ,Node 还提供一个 require.resolve 方法,供外部调用,用于从模块名取到绝对路径。
require.resolve = function(request) {
return Module._resolveFilename(request, self);
};
// 用法
require.resolve('a.js')
// 返回 /home/ruanyf/tmp/a.js
五、加载模块
有了模块的绝对路径,就可以加载该模块了。下面是 module.load 方法的源码。
Module.prototype.load = function(filename) {
var extension = path.extname(filename) || '.js';
if (!Module._extensions[extension]) extension = '.js';
Module._extensions[extension](this, filename);
this.loaded = true;
};上面代码中,首先确定模块的后缀名,不同的后缀名对应不同的加载方法。下面是 .js 和 .json 后缀名对应的处理方法。
Module._extensions['.js'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
module._compile(stripBOM(content), filename);
};
Module._extensions['.json'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
这里只讨论 js 文件的加载。首先,将模块文件读取成字符串,然后剥离 utf8 编码特有的BOM文件头,最后编译该模块。
module._compile 方法用于模块的编译。
Module.prototype._compile = function(content, filename) {
var self = this;
var args = [self.exports, require, self, filename, dirname];
return compiledWrapper.apply(self.exports, args);
};
上面的代码基本等同于下面的形式。
(function (exports, require, module, __filename, __dirname) {
// 模块源码
});也就是说,模块的加载实质上就是,注入exports、require、module三个全局变量,然后执行模块的源码,然后将模块的 exports 变量的值输出。
(完)

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1391
1391
 52
52

 What are the uses of require?
Nov 27, 2023 am 10:03 AM
What are the uses of require?
Nov 27, 2023 am 10:03 AM
Usage of require: 1. Introduce modules: In many programming languages, require is used to introduce external modules or libraries so that the functions they provide can be used in the program. For example, in Ruby, you can use require to load third-party libraries or modules; 2. Import classes or methods: In some programming languages, require is used to import specific classes or methods so that they can be used in the current file; 3. Perform specific tasks: In some programming languages or frameworks, require is used to perform specific tasks or functions.
 Tips to solve fatal error in php header: require(): Failed opening required 'data/tdk.php'
Nov 27, 2023 pm 01:06 PM
Tips to solve fatal error in php header: require(): Failed opening required 'data/tdk.php'
Nov 27, 2023 pm 01:06 PM
In PHP development, we often encounter such error prompts: fatalerror:require(): Failedopeningrequired'data/tdk.php'. This error is usually related to file processing in PHP applications. The specific reasons may be incorrect file paths, non-existent files, or insufficient file permissions. In this article, we will introduce you to some tips to resolve such error messages. Check the file path if "fatal
 fatal error: require(): Failed opening required 'data/tdk.php' error fix
Nov 27, 2023 am 11:40 AM
fatal error: require(): Failed opening required 'data/tdk.php' error fix
Nov 27, 2023 am 11:40 AM
Fatalerror:require():Failedopeningrequired'data/tdk.php' error repair method During the process of website development or maintenance, we often encounter various errors. One of the common errors is "Fatalerror:require():Failedopeningrequired'data/tdk.php'". This error
 How to solve the fatal error in the php header: require(): Failed opening required 'data/tdk.php' (include_path='.;C:\php\pear')
Nov 27, 2023 am 11:03 AM
How to solve the fatal error in the php header: require(): Failed opening required 'data/tdk.php' (include_path='.;C:\php\pear')
Nov 27, 2023 am 11:03 AM
Overview of methods to solve the FatalError in the PHP header: require():Failedopeningrequired'data/tdk.php'(include_path='.;C:phppear'): In the process of using PHP to develop websites, you often encounter various problems. Such error. Among them, "FatalError:require():Failedopeningrequ
 Can react use require?
Dec 27, 2022 am 09:47 AM
Can react use require?
Dec 27, 2022 am 09:47 AM
React can use require, and the correct way to use it is: 1. Read the image through "<img src={require('../img/icon1.png')} alt="" />"; 2. Use "require('~/images/2.png').default" method to read the image; 3. Split the img field into two parts: file name and image name, and then use "require('@/assets)" method to read it Just take it.
 node require what does it mean
Oct 18, 2022 pm 05:51 PM
node require what does it mean
Oct 18, 2022 pm 05:51 PM
require in node is a function that accepts a parameter, the formal parameter is named id, and the type is String; the require function can import modules, JSON files, and local files; the module can be accessed through a relative path from "node_modules", "local Module" or "JSON file", the path will be for the "__dirname" variable or the current working directory.
 How to solve the fatal error in the related php header: require(): Failed opening required 'data/tdk.php' error
Nov 27, 2023 am 10:26 AM
How to solve the fatal error in the related php header: require(): Failed opening required 'data/tdk.php' error
Nov 27, 2023 am 10:26 AM
How to resolve FatalError:require():Failedopeningrequired'data/tdk.php' error in related PHP headers While developing PHP applications, we may encounter various errors. One of the common errors is "FatalError:require():Failedopeningrequired'data/tdk.php'". This is wrong
 Revealing three different Java factory pattern implementation methods—taking source code analysis as the entry point
Dec 28, 2023 am 09:29 AM
Revealing three different Java factory pattern implementation methods—taking source code analysis as the entry point
Dec 28, 2023 am 09:29 AM
The factory pattern is widely used in software development and is a design pattern for creating objects. Java is a popular programming language that has found widespread use in industry. In Java, there are many different implementations of the factory pattern. In this article, we will interpret the Java factory pattern from a source code perspective and explore three different implementation methods. Java's factory pattern can help us create and manage objects. It centralizes the instantiation process of objects in a factory class, reducing the coupling between classes and improving
