

MySQL test environment
The test table is as follows
create table test_table2 ( id int auto_increment primary key, pay_id int, pay_time datetime, other_col varchar(100) )
Create a storage The process inserts test data. The characteristic of the test data is that pay_id is repeatable. Here, in the process of storing the process and inserting 300W pieces of data in a loop, a repeated pay_id is inserted every 100 pieces of data, and the time field is random within a certain range.
CREATE DEFINER=`root`@`%` PROCEDURE `test_insert`(IN `loopcount` INT) LANGUAGE SQLNOT DETERMINISTICCONTAINS SQL SQL SECURITY DEFINER COMMENT ''BEGINdeclare cnt int;set cnt = 0;while cnt< loopcount doinsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());if (cnt mod 100 = 0) theninsert into test_table2 (pay_id,pay_time,other_col) values (cnt,date_add(now(), interval floor(300*rand()) day),uuid());end if;set cnt = cnt + 1; end while;END
Execute call test_insert(3000000); Insert 303000 rows of data
How to write two subqueries
About query It means to query the data with business ID greater than 1 within a certain time period, so there are two ways to write it.
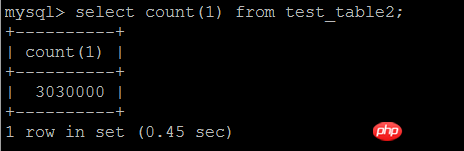
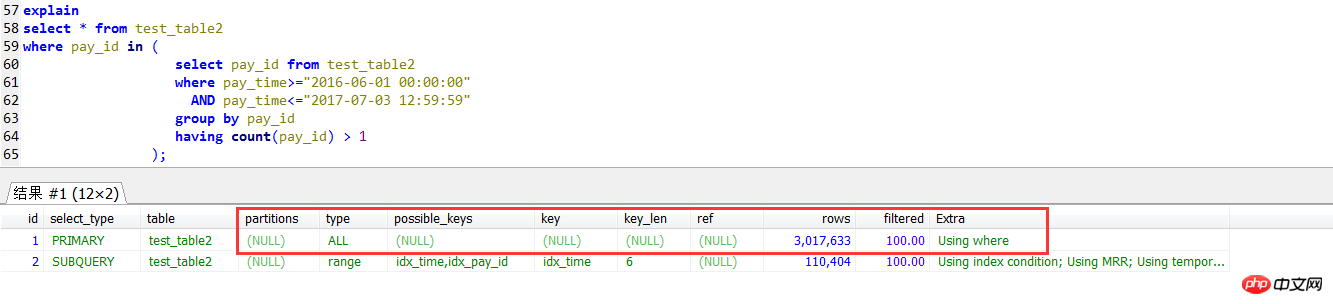
The first way to write it is as follows: The IN subquery is the business ID whose number of business statistics rows is greater than 1 within a certain period of time. The outer layer is queried according to the results of the IN subquery. There is an index on the column pay_id of the business ID. , the logic is relatively simple,
This writing method is indeed less efficient when the amount of data is large, and no index is needed
select * from test_table2 force index(idx_pay_id)where pay_id in ( select pay_id from test_table2 where pay_time>="2016-06-01 00:00:00" AND pay_time<="2017-07-03 12:59:59" group by pay_id having count(pay_id) > 1);
Execution result: 2.23 seconds
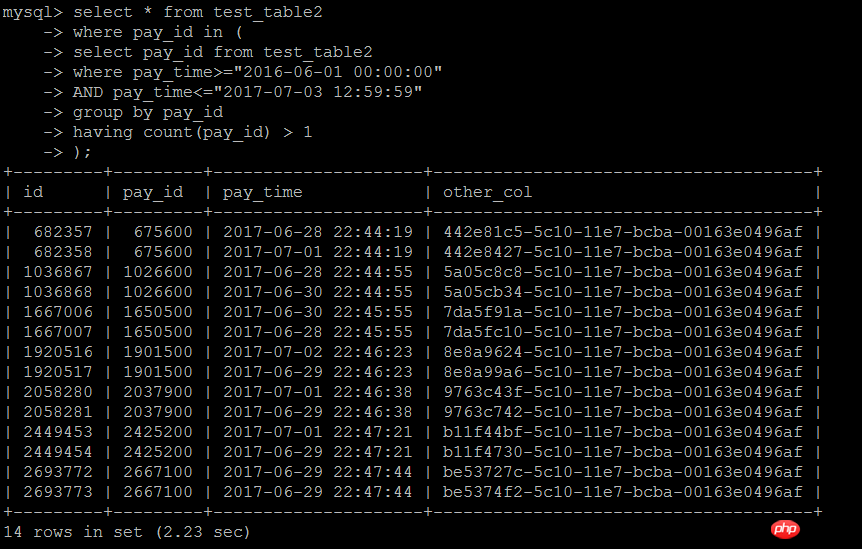
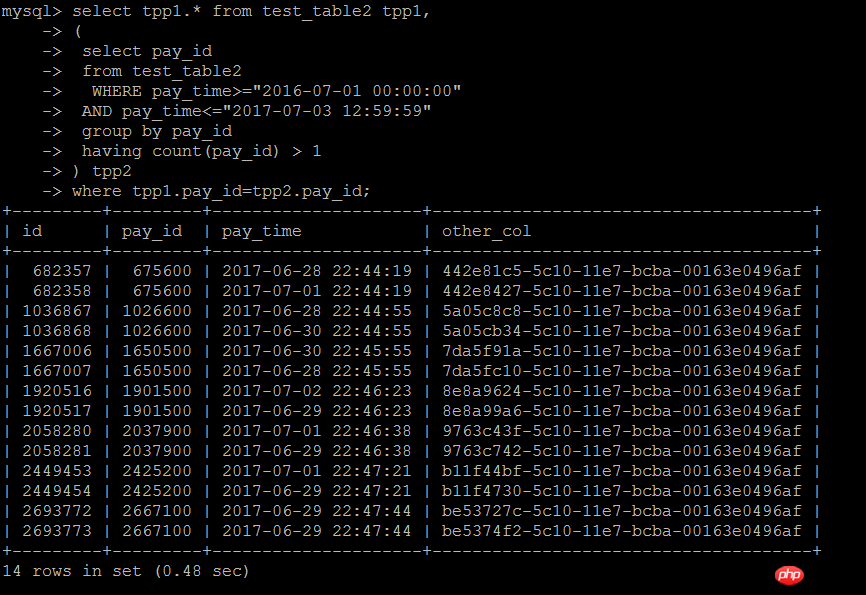
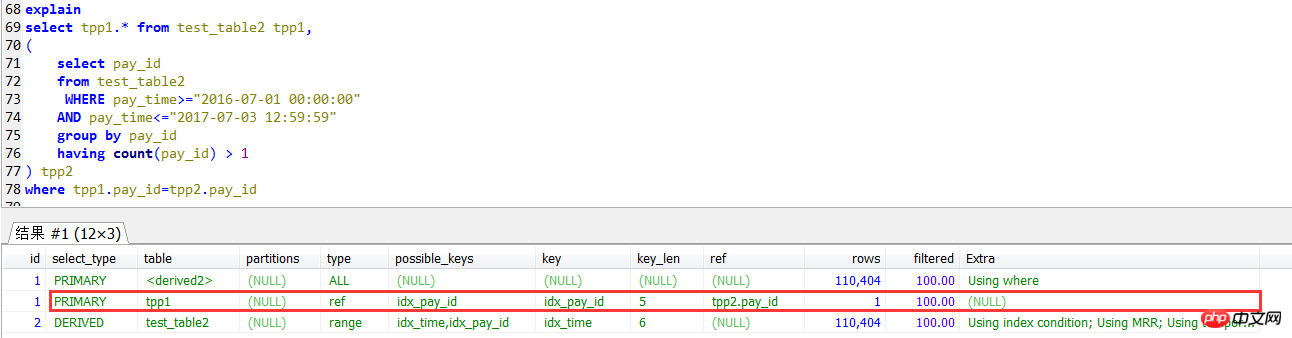
The second way of writing is to join with the subquery. This way of writing is equivalent to the IN subquery writing method above. The following test found that the efficiency is indeed a lot Improvement
select tpp1.* from test_table2 tpp1,
( select pay_id
from test_table2
WHERE pay_time>="2016-07-01 00:00:00"
AND pay_time<="2017-07-03 12:59:59"
group by pay_id
having count(pay_id) > 1) tpp2
where tpp1.pay_id=tpp2.pay_idExecution result: 0.48 seconds
In the execution plan of the subquery, it is found that the outer query is a full table The scanning method does not use the index on pay_id
The execution plan of the join self-check, the outer layer (query of tpp1 alias) uses the index on pay_id.
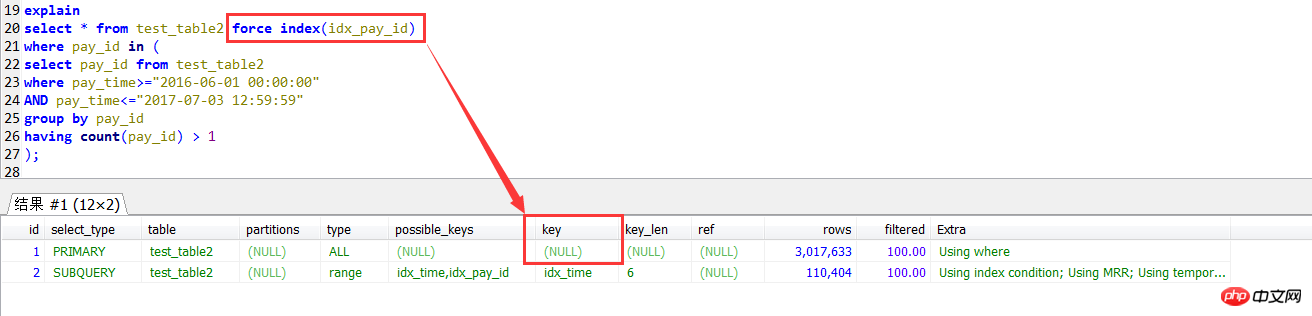
Later I wanted to use forced indexing for the first query method. Although no error was reported, I found that it was useless at all.
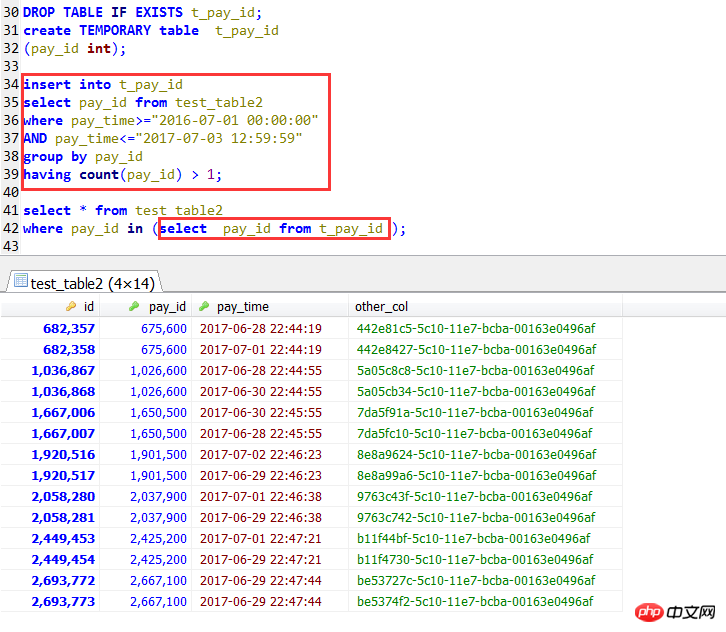
If the subquery is a direct value, the index can be used normally.

It can be seen that MySQL’s support for IN subqueries is indeed not very good.
In addition: adding a temporary table, although it is more efficient than many join methods, it is also more efficient than directly using IN subqueries. In this case, it is also possible Indexes are used, but in this simple case, there is no need to use a temporary table.
The following is a test of a similar case in sqlserver 2014, There are tens of thousands of identical test table structures and quantities. It can be seen that in this case, the two writing methods can be considered to be exactly the same in SQL Server (execution plan + efficiency). In this regard, SQL Server is much better than MySQL
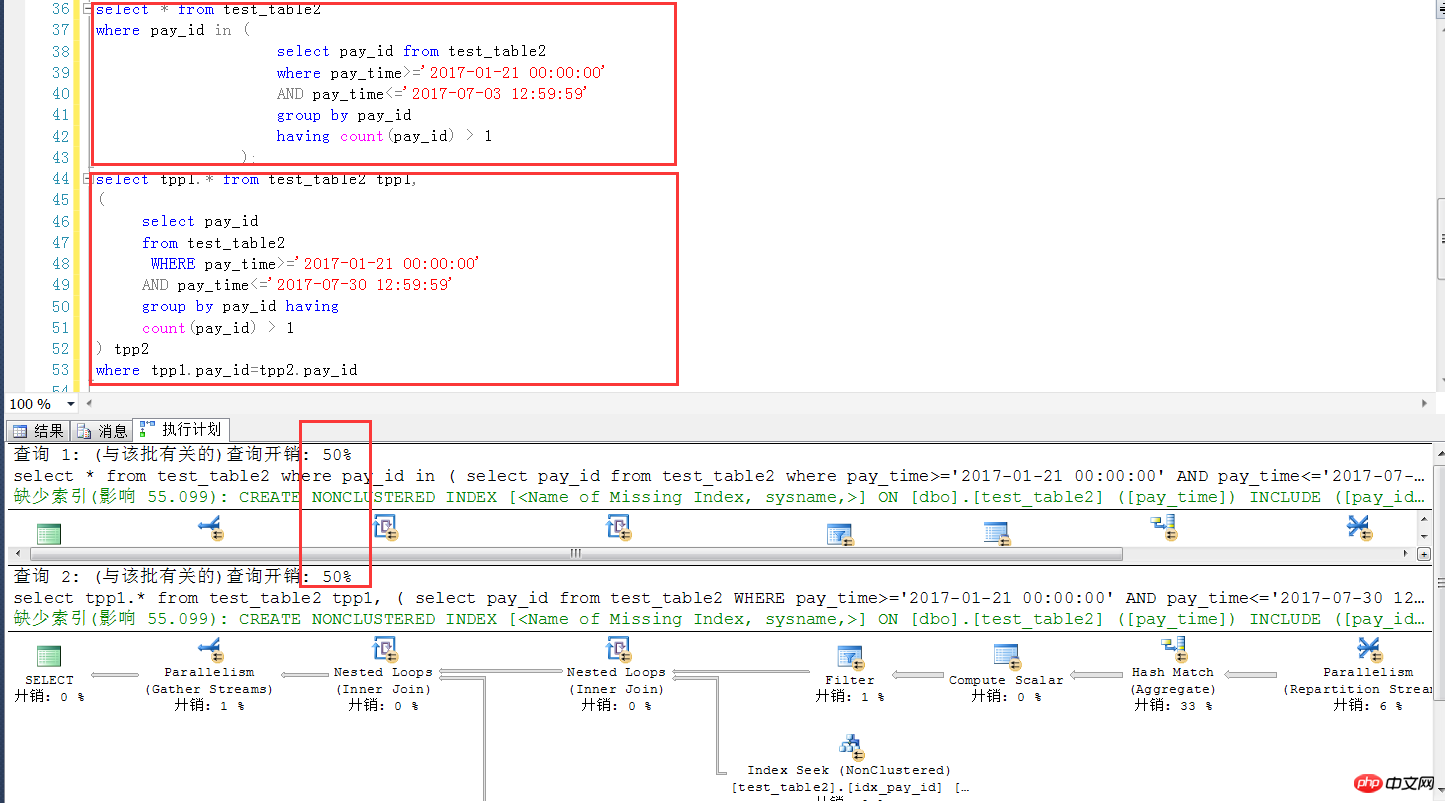
The following is the test environment script in sqlserver.
create table test_table2
(
id int identity(1,1) primary key,
pay_id int,
pay_time datetime,
other_col varchar(100)
)begin trandeclare @i int = 0while @i<300000begininsert into test_table2 values (@i,getdate()-rand()*300,newid());
if(@i%1000=0)begininsert into test_table2 values (@i,getdate()-rand()*300,newid());endset @i = @i + 1endCOMMITGOcreate index idx_pay_id on test_table2(pay_id);
create index idx_time on test_table2(pay_time);GOselect * from test_table2
where pay_id in (select pay_id from test_table2 where pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-03 12:59:59' group by pay_id having count(pay_id) > 1);
select tpp1.* from test_table2 tpp1,
( select pay_id
from test_table2
WHERE pay_time>='2017-01-21 00:00:00' AND pay_time<='2017-07-30 12:59:59'
group by pay_id having
count(pay_id) > 1) tpp2
where tpp1.pay_id=tpp2.pay_idSummary: In MySQL data, as of version 5.7.18, IN subqueries should still be used with caution
The above is the detailed content of How to write two subqueries in MySQL. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



