

Configure python 2.7
bs4
requestsInstall using pip to install sudo pip install bs4
sudo pip install requests
Briefly explain the use of bs4. Because it is crawling web pages, I will introduce find and find_all
The difference between find and find_all is that the things returned are different. Find returns is the first matched tag and the content in the tag
find_all returns a list
For example, we write a test.html to test the difference between find and find_all. The content is:
<html> <head> </head> <body> <div id="one"><a></a></div> <div id="two"><a href="#">abc</a></div> <div id="three"><a href="#">three a</a><a href="#">three a</a><a href="#">three a</a></div> <div id="four"><a href="#">four<p>four p</p><p>four p</p><p>four p</p> a</a></div> </body> </html>
<br/>
Then the code of test.py is:
from bs4 import BeautifulSoup import lxml if __name__=='__main__': s = BeautifulSoup(open('test.html'),'lxml') print s.prettify() print "------------------------------" print s.find('div') print s.find_all('div') print "------------------------------" print s.find('div',id='one') print s.find_all('div',id='one') print "------------------------------" print s.find('div',id="two") print s.find_all('div',id="two") print "------------------------------" print s.find('div',id="three") print s.find_all('div',id="three") print "------------------------------" print s.find('div',id="four") print s.find_all('div',id="four") print "------------------------------"
<br/>
After running, we can see the result. When getting the specified tag, there is not much difference between the two. When getting a group of tags, the difference between the two will be displayed.

So we must pay attention to what we need when using it, otherwise an error will occur
The next step is to obtain web page information through requests. I don’t quite understand why others write heard and follow For other things
I directly accessed the webpage, obtained the second-level webpages of several categories on prose.com through the get method, and then passed a group test to crawl all the webpages
def get_html():
url = ""
two_html = ['sanwen','shige','zawen','suibi','rizhi','novel'] for doc in two_html:
i=1 if doc=='sanwen':print "running sanwen -----------------------------" if doc=='shige':print "running shige ------------------------------" if doc=='zawen':print 'running zawen -------------------------------' if doc=='suibi':print 'running suibi -------------------------------' if doc=='rizhi':print 'running ruzhi -------------------------------' if doc=='nove':print 'running xiaoxiaoshuo -------------------------' while(i<10):
par = {'p':i}
res = requests.get(url+doc+'/',params=par)if res.status_code==200:
soup(res.text)
i+=i
<br/>
In this part of the code, I did not process the res.status_code that is not 200. The resulting problem is that errors will not be displayed and the crawled content will be lost. Then I analyzed the web page of Sanwen.net and found that it is www.sanwen.net/rizhi/&p=1
. The maximum value of p is 10. I don’t understand. The last time I crawled the disk, it was 100 pages. I’ll analyze it later. Then get the content of each page through the get method. <br/>After getting the content of each page, it is to analyze the author and title. The code is like this
def soup(html_text):
s = BeautifulSoup(html_text,'lxml')
link = s.find('div',class_='categorylist').find_all('li') for i in link:if i!=s.find('li',class_='page'):
title = i.find_all('a')[1]
author = i.find_all('a')[2].text
url = title.attrs['href']
sign = re.compile(r'(//)|/')
match = sign.search(title.text)
file_name = title.text if match:
file_name = sign.sub('a',str(title.text))
<br/>
There is a cheating thing when getting the title, please ask the boss When you write prose, why do you add slashes in the title? Not only one but also two. This problem directly led to an error in the file name when I wrote the file later, so I wrote a regular expression and I changed it for you. <br/>The last step is to get the prose content. Through the analysis of each page, we can get the article address, and then get the content directly. I originally wanted to get it one by one by changing the web page address, which saves trouble.
def get_content(url):
res = requests.get(''+url) if res.status_code==200:
soup = BeautifulSoup(res.text,'lxml')
contents = soup.find('div',class_='content').find_all('p')
content = ''for i in contents:
content+=i.text+'\n'return content
<br/>
The last thing is to write the file and save it ok
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
f.close()
Three functions to obtain There is a problem with the essays on prose.com. The problem is that I don’t know why some essays are lost. I can only get about 400 articles. This is much different from the articles on prose.com, but it is indeed available page by page. Come on, I hope someone can help me with this issue. Maybe we should make the web page inaccessible. Of course, I think it has something to do with the broken network in my dormitory
f = open(file_name+'.txt','w') print 'running w txt'+file_name+'.txt' f.write(title.text+'\n')
f.write(author+'\n')
content=get_content(url)
f.write(content)
f.close()
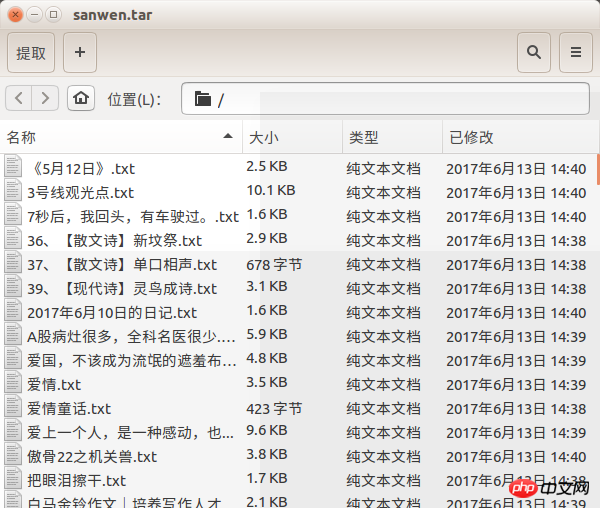
I almost forgot the rendering

The above is the detailed content of How does python crawl articles from prose.com?. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



