

Example of the process of crawling qq music with Python

1. Preface
##There is still a lot of music on qq music. Sometimes I want to download good music, but There is an annoying login process every time when downloading from a web page. So, here comes a qqmusic crawler. At least I think the most important thing for a for loop crawler is to find the URL of the element to be crawled. Let’s start looking (don’t laugh at me if I’m wrong)
<br>
## 2. Python crawls QQ music singlesA video from MOOC that I watched before gave a good explanation of the general steps for writing a crawler. We will also follow this.
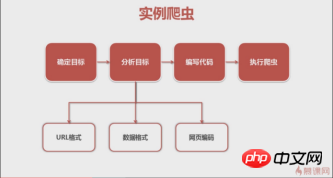 ## Crawler steps
## Crawler steps
First of all, we need to clarify the goal. This time we crawled the singles of QQ Music singer Andy Lau.
(Baidu Encyclopedia)->Analysis target (strategy: url format (range), data format, web page encoding)->Write code->Execute crawler 2. Analysis targetSong link:
From the screenshot on the left, you can know that singles use paging to arrange song information. Each page displays 30 items, a total of 30 pages. Clicking on the page number or the ">" on the far right will jump to the next page. The browser will send an asynchronous ajax request to the server. From the link, you can see the begin and num parameters, which represent the starting song subscript respectively (the screenshot is the 2nd page, the starting subscript is 30) and one page returns 30 items, and the server responds by returning song information in json format (MusicJsonCallbacksinger_track({"code":0,"data":{"list":[{"Flisten_count1":. .....]})), if you just want to obtain song information alone, you can directly splice the link request and parse the returned json format data. Here we do not use the method of directly parsing the data format. I use the Python Selenium method. After each page of single information is obtained and parsed, click ">" to jump to the next page and continue parsing until all the information is parsed and recorded. Single information. Finally, request the link of each single to obtain detailed single information. 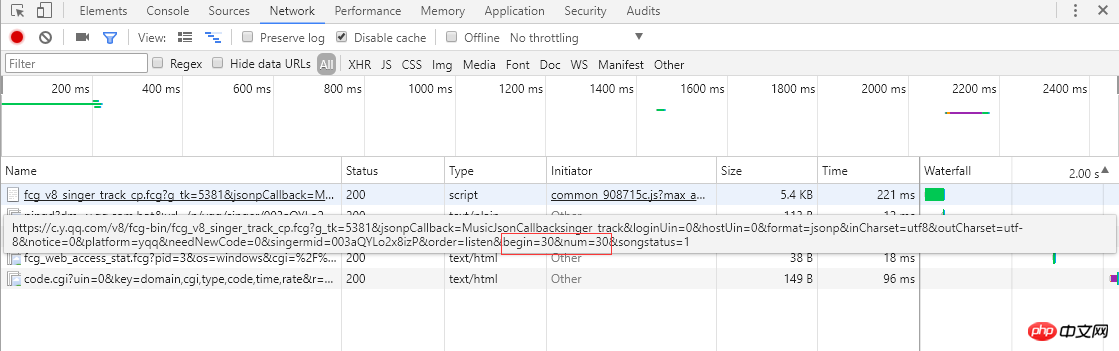
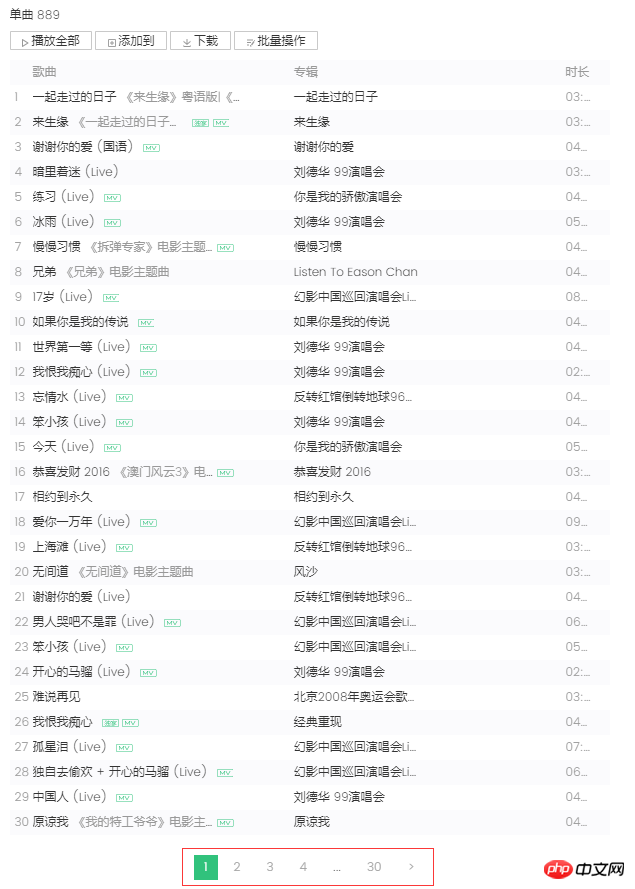
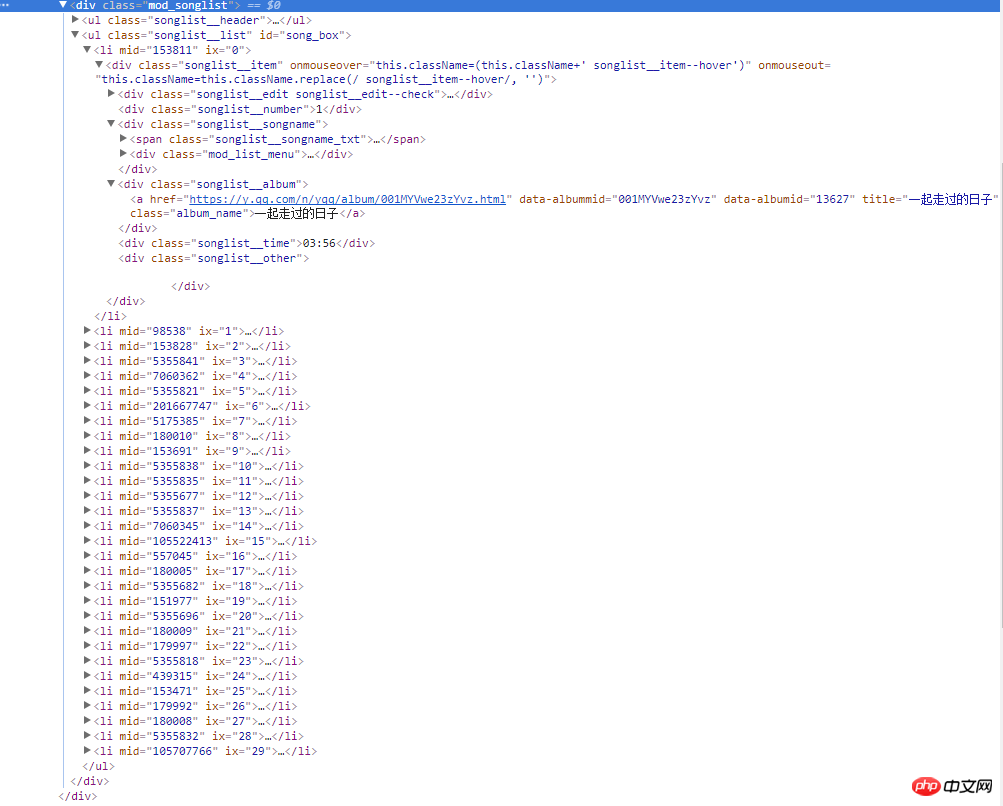
1 ) Download web page content. Here we use Python’s Urllib standard library and encapsulate a download method:
def download(url, user_agent='wswp', num_retries=2):
if url is None:
return None
print('Downloading:', url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
request = urllib.request.Request(url, headers=headers) # 设置用户代理wswp(Web Scraping with Python)
try:
html = urllib.request.urlopen(request).read().decode('utf-8')
except urllib.error.URLError as e:
print('Downloading Error:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry when return code is 5xx HTTP erros
return download(url, num_retries-1) # 请求失败,默认重试2次,
return html<br>
def music_scrapter(html, page_num=0):
try:
soup = BeautifulSoup(html, 'html.parser')
mod_songlist_div = soup.find_all('div', class_='mod_songlist')
songlist_ul = mod_songlist_div[1].find('ul', class_='songlist__list')
'''开始解析li歌曲信息'''
lis = songlist_ul.find_all('li')
for li in lis:
a = li.find('div', class_='songlist__album').find('a')
music_url = a['href'] # 单曲链接
urls.add_new_url(music_url) # 保存单曲链接
# print('music_url:{0} '.format(music_url))
print('total music link num:%s' % len(urls.new_urls))
next_page(page_num+1)
except TimeoutException as err:
print('解析网页出错:', err.args)
return next_page(page_num + 1)
return Nonedef get_music():
try:
while urls.has_new_url():
# print('urls count:%s' % len(urls.new_urls))
'''跳转到歌曲链接,获取歌曲详情'''
new_music_url = urls.get_new_url()
print('url leave count:%s' % str( len(urls.new_urls) - 1))
html_data_info = download(new_music_url)
# 下载网页失败,直接进入下一循环,避免程序中断
if html_data_info is None:
continue
soup_data_info = BeautifulSoup(html_data_info, 'html.parser')
if soup_data_info.find('div', class_='none_txt') is not None:
print(new_music_url, ' 对不起,由于版权原因,暂无法查看该专辑!')
continue
mod_songlist_div = soup_data_info.find('div', class_='mod_songlist')
songlist_ul = mod_songlist_div.find('ul', class_='songlist__list')
lis = songlist_ul.find_all('li')
del lis[0] # 删除第一个li
# print('len(lis):$s' % len(lis))
for li in lis:
a_songname_txt = li.find('div', class_='songlist__songname').find('span', class_='songlist__songname_txt').find('a')
if 'https' not in a_songname_txt['href']: #如果单曲链接不包含协议头,加上
song_url = 'https:' + a_songname_txt['href']
song_name = a_songname_txt['title']
singer_name = li.find('div', class_='songlist__artist').find('a').get_text()
song_time =li.find('div', class_='songlist__time').get_text()
music_info = {}
music_info['song_name'] = song_name
music_info['song_url'] = song_url
music_info['singer_name'] = singer_name
music_info['song_time'] = song_time
collect_data(music_info)
except Exception as err: # 如果解析异常,跳过
print('Downloading or parse music information error continue:', err.args)<span style="font-size: 16px;">爬虫跑起来了,一页一页地去爬取专辑的链接,并保存到集合中,最后通过get_music()方法获取单曲的名称,链接,歌手名称和时长并保存到Excel文件中。</span><br><span style="font-size: 14px;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/a1138f33f00f8d95b52fbfe06e562d24-4.png" class="lazy" alt="" style="max-width:90%" style="max-width:90%"><strong><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/9282b5f7a1dc4a90cee186c16d036272-5.png" class="lazy" alt=""></strong></span>
<br>
1. The single uses paging. Switching to the next page uses an asynchronous ajax request to obtain json format data from the server and render it to the page. The browser address bar link remains unchanged. , cannot be requested through spliced links. At first I thought about simulating ajax requests through the Python Urllib library, but then I thought about using Selenium. Selenium can well simulate the real operation of the browser, and the positioning of page elements is also very convenient. It simulates clicking the next page, constantly switching the single pagination, and then parsing the web page source code through BeautifulSoup to obtain the single information.
2.url link manager uses a collection data structure to save single links. Why use collections? Because multiple singles may come from the same album (with the same album URL), this can reduce the number of requests.
class UrlManager(object):<br> def __init__(self):<br> self.new_urls = set() # 使用集合数据结构,过滤重复元素<br> self.old_urls = set() # 使用集合数据结构,过滤重复元素
def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>
, and the single information can be well saved through the Excel file. def write_to_excel(self, content):<br> try:<br> for row in content:<br> self.workSheet.append([row['song_name'], row['song_url'], row['singer_name'], row['song_time']])<br> self.workBook.save(self.excelName) # 保存单曲信息到Excel文件<br> except Exception as arr:<br> print('write to excel error', arr.args)<br><br>
Finally, I have to celebrate, after all, I successfully crawled the single information of QQ Music . This time we were able to successfully crawl the single, Selenium was indispensable. This time we only used some simple functions of selenium. We will learn more about Selenium in the future, not only in terms of crawlers but also in UI automation.
Points that need to be optimized in the future:
1. There are many download links, and it is slow to download one by one. We plan to use multi-threaded concurrent downloading later.
2. The download speed is too fast. In order to avoid the server disabling the IP and the problem of too frequent access to the same domain name later, there is a waiting mechanism, and there is a wait between each request. interval.
3. Parsing web pages is an important process. Regular expressions, BeautifulSoup and lxml can be used. Currently, the BeautifulSoup library is used. In terms of efficiency, BeautifulSoup is not as efficient as lxml. Later, Will try to use lxml.
The above is the detailed content of Example of the process of crawling qq music with Python. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 HadiDB: A lightweight, horizontally scalable database in Python
Apr 08, 2025 pm 06:12 PM
HadiDB: A lightweight, horizontally scalable database in Python
Apr 08, 2025 pm 06:12 PM
HadiDB: A lightweight, high-level scalable Python database HadiDB (hadidb) is a lightweight database written in Python, with a high level of scalability. Install HadiDB using pip installation: pipinstallhadidb User Management Create user: createuser() method to create a new user. The authentication() method authenticates the user's identity. fromhadidb.operationimportuseruser_obj=user("admin","admin")user_obj.
 Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
Python: Exploring Its Primary Applications
Apr 10, 2025 am 09:41 AM
Python is widely used in the fields of web development, data science, machine learning, automation and scripting. 1) In web development, Django and Flask frameworks simplify the development process. 2) In the fields of data science and machine learning, NumPy, Pandas, Scikit-learn and TensorFlow libraries provide strong support. 3) In terms of automation and scripting, Python is suitable for tasks such as automated testing and system management.
 The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
The 2-Hour Python Plan: A Realistic Approach
Apr 11, 2025 am 12:04 AM
You can learn basic programming concepts and skills of Python within 2 hours. 1. Learn variables and data types, 2. Master control flow (conditional statements and loops), 3. Understand the definition and use of functions, 4. Quickly get started with Python programming through simple examples and code snippets.
 Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
Navicat's method to view MongoDB database password
Apr 08, 2025 pm 09:39 PM
It is impossible to view MongoDB password directly through Navicat because it is stored as hash values. How to retrieve lost passwords: 1. Reset passwords; 2. Check configuration files (may contain hash values); 3. Check codes (may hardcode passwords).
 How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
How to use AWS Glue crawler with Amazon Athena
Apr 09, 2025 pm 03:09 PM
As a data professional, you need to process large amounts of data from various sources. This can pose challenges to data management and analysis. Fortunately, two AWS services can help: AWS Glue and Amazon Athena.
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
The steps to start a Redis server include: Install Redis according to the operating system. Start the Redis service via redis-server (Linux/macOS) or redis-server.exe (Windows). Use the redis-cli ping (Linux/macOS) or redis-cli.exe ping (Windows) command to check the service status. Use a Redis client, such as redis-cli, Python, or Node.js, to access the server.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to view server version of Redis
Apr 10, 2025 pm 01:27 PM
How to view server version of Redis
Apr 10, 2025 pm 01:27 PM
Question: How to view the Redis server version? Use the command line tool redis-cli --version to view the version of the connected server. Use the INFO server command to view the server's internal version and need to parse and return information. In a cluster environment, check the version consistency of each node and can be automatically checked using scripts. Use scripts to automate viewing versions, such as connecting with Python scripts and printing version information.
