

This Linux tutorial will explain the Heka configuration for you, and the specific operation process:
Distributed back-end log architecture based on Heka, ElasticSearch and Kibana
The current mainstream back-end logs are The standard elk mode (Elasticsearch, Logstash, Kinaba) is adopted, which is responsible for log storage, collection and log visualization respectively.
But because our log files are diverse and distributed on different servers, various logs are used to facilitate secondary development and customization in the future. Therefore, Mozilla adopted Heka, which is implemented using golang open source and imitated Logstash.
Currently mainstream backend logs adopt the standard elk mode (Elasticsearch, Logstash, Kinaba), which are responsible for log storage respectively , collection and log visualization.
But because our log files are diverse and distributed on different servers, various logs are used to facilitate secondary development and customization in the future. Therefore, Mozilla adopted Heka, which is implemented using golang open source and imitated Logstash.
The overall architecture after using Heka, ElasticSearch and Kibana is shown in the figure below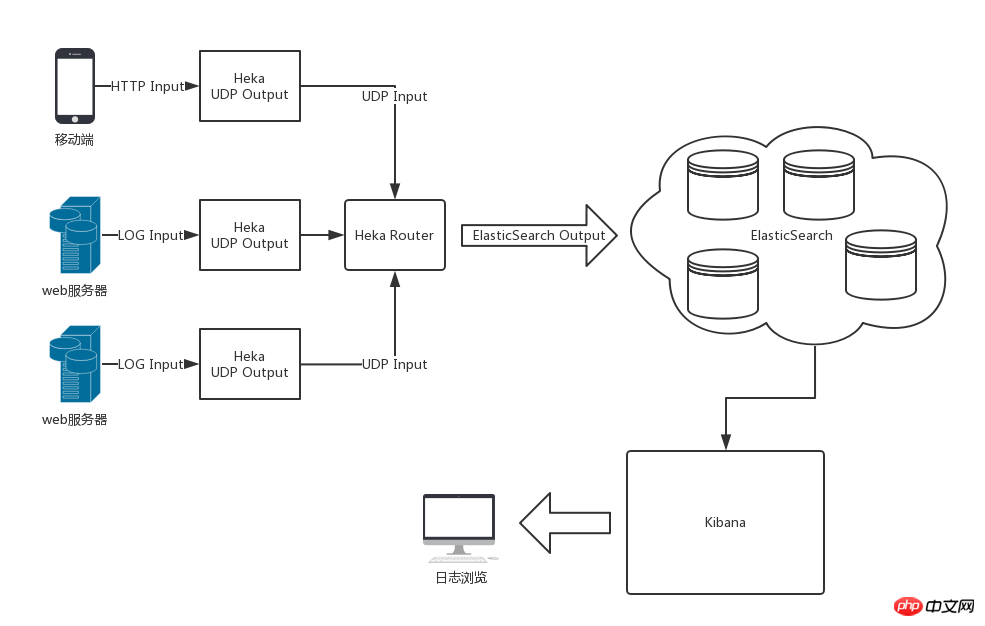
Heka's log processing flow is input segmentation, decoding, filtering, encoding and output. The data flow within a single Heka service flows within each module through the Message data model defined by Heka.
Heka has built-in most commonly used module plug-ins, such as
The input plug-in has Logstreamer Input, which can use log files as input sources,
The decoding plug-in Nginx Access Log Decoder can decode the nginx access log into standard key-value pair data and hand it over to the subsequent module plug-in for processing.
Thanks to the flexible configuration of input and output, the log data collected by Heka in various places can be processed and output to Heka in the log center for unified encoding and then handed over to ElasticSearch for storage.
The above is the detailed content of Detailed introduction to Heka configuration. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



