
This article summarizes the architectural practice in e-commerce platforms from various angles. Due to the rush of time, a first draft has been finalized and will be supplemented and improved. Everyone is welcome to communicate.
Please state the source for reprinting:
Author: Yang Butao
Focus on distributed architecture, big data, search, open source technology
QQ:306591368
TechnologyBlog:
Client page cache (http The header contains Expires/Cache of Control , last modified (304, server does not return body, the client can continue to use cache to reduce traffic ), ETag)
reverse proxy cache
Application-side caching (memcache)
In-memory database
Buffer, cache mechanism (database, middleware, etc.)
Hash, B tree , inverted, bitmap
Hash index is suitable for comprehensive array addressing and linked list insertion characteristics, and can achieve fast access to data.
B-tree index is suitable for query-oriented scenarios, avoiding multiple IOs and improving query efficiency.
Inverted index is the best way to implement the word-to-document mapping relationship and the most effective index structure, and is widely used in the search field.
Bitmap is a very simple and fast data structure. It can optimize storage space and speed at the same time (without having to trade space for time), and is suitable for computing scenarios with massive data.
In large-scale data, the data has certain The characteristic of locality uses the principle of locality to divide and conquer the problem of massive data calculation.
The MR model is a shared-nothing architecture, and the data set is distributed to various nodes. During processing, each node reads the locally stored data for processing(map), merges the processed data(combine), sorts(shuffle and sort), and then distributes(to the reduce node). This avoids the transmission of large amounts of data and improves processing efficiency.
Parallel Computing ) refers to using multiple computing resources simultaneously to solve The process of calculating problems is an effective means to improve the computing speed and processing capabilities of computer systems. Its basic idea is to use multiple processors /processes /threads to collaboratively solve the same problem, that is, to decompose the problem to be solved into several parts, and each part is calculated in parallel by an independent processor. The difference between
and MR is that it is based on problem decomposition rather than data decomposition.
With the increase of platform concurrency, it is necessary to expand the node capacity for clustering and use load balancing The device distributes requests; load balancing devices usually provide load balancing while also providing failure detection functions; at the same time, in order to improve availability, disaster recovery backup is needed to prevent unavailability problems caused by node failure; backup is available online and offline backup, you can choose different backup strategies based on different invalidity requirements.
Read and write separation is for the database. With the increase of system concurrency, an important means to improve the availability of data access is to separate writing data and reading data. ; Of course, while reading and writing are separated, attention needs to be paid to the consistency of the data; for consistency, in distributed systems CAP quantification, more attention is paid to availability.
The relationship between the various modules in the platform should be as low-coupled as possible. They can interact through relevant message components, asynchronously if possible, and clearly distinguish the main process of data flow. With the secondary process, the primary and secondary processes are asynchronous. For example, logging can be operated asynchronously, which increases the availability of the entire system.
Of course in asynchronous processing, in order to ensure that data is received or processed, a confirmation mechanism (confirm, ack) is often needed.
However, in some scenarios, although the request has been processed, the confirmation message is not returned due to other reasons (such as unstable network ). In this case, the request needs to be resent. Processing design needs to consider idempotence due to retransmission factors.
Monitoring is also an important means to improve the availability of the entire platform. Multi-platforms monitor multiple dimensions; the module is transparent at runtime to achieve white-boxing during the runtime. .
Split includes splitting the business and splitting the database.
System resources are always limited. If a relatively long business is executed in one go, under a large number of concurrent operations, this blocking method cannot effectively release resources for other processes to execute in a timely manner. The throughput of this system is not high.
It is necessary to logically segment the business and use an asynchronous and non-blocking method to improve the throughput of the system.
With the increase in data volume and concurrency, read-write separation cannot meet the system concurrency performance requirements, and data needs to be segmented, including dividing the data into databases and tables. This method of dividing databases and tables requires adding routing logic support for data.
For the scalability of the system, it is best for the module to be stateless, and the overall throughput can be improved by adding nodes.
The capacity of the system is limited, and the amount of concurrency it can withstand is also limited. When designing the architecture, flow control must be considered , to prevent the system from crashing due to unexpected attacks or the impact of instantaneous concurrency. When designing to add flow control measures, you can consider queuing requests. If the request exceeds the expected range, you can issue an alarm or discard it.
For access to shared resources, in order to prevent conflicts, concurrency control is required. At the same time, some transactions need to be transactional to ensure transaction consistency, so in the transaction When designing the system, atomic operations and concurrency control need to be considered.
Some commonly used high-performance means to ensure concurrency control include optimistic locking, Latch, mutex, copy-on-write, CAS, etc.; multi-version concurrency control MVCC is usually an important means to ensure consistency, which is used in databases are often used in design.
There are different types of business logic in the platform, some are computationally complex, some are consumingIO, and at the same time, For the same type, different business logic consumes different amounts of resources, which requires different strategies for different logics.
For IO type, an event-driven asynchronous non-blocking method can be adopted. The single-threaded method can reduce the overhead caused by thread switching, or in the case of multi-threading, the spin method can be adopted. Reduce thread switching (such as Oracle latch design ); for computing, make full use of multi-threading for operations.
With the same type of calling method, different businesses allocate appropriate resources, set different numbers of computing nodes or threads, divert the business, and prioritize high-priority businesses.
When errors occur in some business modules of the system, in order to reduce the impact on the processing of normal requests under concurrency, sometimes it is necessary to consider separate channels for these abnormal requests Handle or even temporarily automatically disable these abnormal business modules.
The failure of some requests may be an accidental temporary failure (such as network instability), and request retry needs to be considered.
The system resources are limited. When using resources, you must release them at the end, whether the request is a normal path or an abnormal path, so as to facilitate Timely recycling of resources for use by other requests.
When designing the communication architecture, it is often necessary to consider timeout control.
2. Static Architecture Blueprint
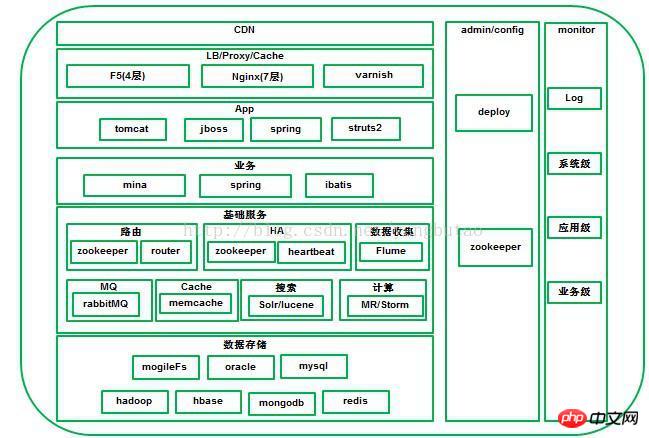
The entire architecture is a layered and distributed architecture, including CDN and load balancing vertically. /Reverse proxy, web application, business layer, basic service layer, data storage layer. The horizontal direction includes configuration management, deployment and monitoring of the entire platform.
CDNThe system can redirect the user's request to the location closest to the user in real time based on comprehensive information such as network traffic and the connection of each node, load status, distance to the user, and response time. on the service node. Its purpose is to enable users to obtain the content they need nearby, solve Internet network congestion, and improve the response speed for users to access the website.
For large-scale e-commerce platforms, it is generally necessary to build CDN for network acceleration. Large platforms such as Taobao and JD.com use self-built CDN. Small and medium-sized enterprises can use third-party CDN to cooperate with manufacturers, such as Blue Xun, Wangsu, Kuaiwang, etc.
Of course, when choosing a CDN vendor, you need to consider the length of business, whether it has scalable bandwidth resources, flexible traffic and bandwidth selection, stable nodes, and cost-effectiveness.
A large platform includes many business domains, and different business domains have different clusters. You can use DNS to distribute or poll domain name resolution, DNS The method is simple to implement, but lacks flexibility due to the existence of cache; it is generally based on commercial hardware F5, NetScaler or open source soft load lvs and is distributed at the 4 layer. Of course, redundancy will be used (such as lvs+keepalived), adopt the active and backup mode. After the
4 layer is distributed to the business cluster, it will go through web servers such as nginx or HAProxy at layer 7 Do load balancing or reverse Agents are distributed to application nodes in the cluster.
To choose which load to choose, you need to comprehensively consider various factors (whether it meets high concurrency and high performance, how to solve session retention, what is the load balancing algorithm, support for compression, memory consumption of cache); The following is an introduction based on several commonly used load balancing software.
LVS, working on the 4 layer, is a high-performance, high-concurrency, scalable, and reliable load balancer implemented in Linux, supporting multiple forwarding methods (NAT, DR, IP Tunneling ), where DR mode supports load balancing over the WAN. Supports dual-machine hot standby (Keepalived or Heartbeat). The dependence on the network environment is relatively high.
Nginx works on the 7 layer, event-driven, asynchronous and non-blocking architecture, supporting multi-process high-concurrency load balancer / reverse proxy software. You can do some diversion for http based on domain names, directory structures, and regular rules. Detect internal server failures through the port, such as status codes, timeouts, etc. returned by the server when processing web pages, and will resubmit requests that return errors to another node. However, the disadvantage is that it does not support url for detection. For session sticky, it can be implemented based on the algorithm of ip hash, and supports session sticky through the cookie-based extension nginx-sticky-module.
HAProxy supports 4 layer and 7 layer for load balancing, and supports session session persistence, cookie guidance; support backend url detection method; load balancing algorithms are relatively rich, including RR, weight, etc.
For images, you need a separate domain name, an independent or distributed image server or such as mogileFS, you can add varnish on top of the image server for image caching.
The application layer runs in jboss or tomcatcontainers, representing independent systems, such as front-end shopping, user independent services, back-end systems, etc.
Protocol interface, HTTP, JSON
can use servlet3.0, asynchronous servlet, to improve the throughput of the entire system
httpRequests go through N ginx, It is assigned to a certain node of App through the load balancing algorithm. It is relatively simple to expand this layer.
In addition to using cookie to save a small amount of user partial information (cookies generally cannot exceed the size of 4K), for the App access layer, user-related sessiondata is saved , but some reverse proxies or load balancing do not support session sticky or have relatively high access availability requirements (app access node is down, session is lost), this It is necessary to consider the centralized storage of session to make the App access layer stateless. At the same time, when the number of system users increases, horizontal expansion can be achieved by adding more application nodes.
SessionCentralized storage needs to meet the following requirements:
a, efficient communication protocol
b, session distributed cache, support node scaling, data redundant backup and data migration
c, sessionexpiration management
represent the services provided by businesses in a certain field. For e-commerce, the fields include users, goods, orders, red envelopes, payment services, etc. Different fields provide different services. Services,
These different fields constitute modules. Good module division and interface design are very important. Generally, the principles of high cohesion and interface convergence are referred to.
This can improve the availability of the entire system. Of course, modules can be deployed together according to the size of the application. For large-scale applications, they are generally deployed independently.
High concurrency:
Business layer external protocols are exposed in RPC of NIO, and more mature NIOcommunication frameworks can be used, such as netty, mina
Availability:
In order to improve the availability of module services, a module is deployed on multiple nodes for redundancy and automatically performs load forwarding and failover ;
can initially use the VIP+heartbeat method. Currently, the system has one Separate components HA, use zookeeper to achieve (advantages over the original solution)
Consistency and transactions:
For the consistency of distributed systems, try to satisfy Availability and consistency can be achieved through proofreading to achieve a final consistent state.
The communication component is used to call between internal services of the business system. In a large-concurrency e-commerce platform, it needs to meet the requirements of high concurrency and high throughput.
The entire communication component includes two parts: client and server.
The client and server maintain long connections, which can reduce the cost of establishing a connection for each request. The client defines a connection pool for each server. After initializing the connection, the server can be connected concurrently to perform rpc operations. Long connections in the connection pool require heartbeat maintenance and request timeout settings.
The maintenance process of long connections can be divided into two stages, one is the process of sending requests, and the other is the process of receiving responses. During the process of sending the request, if an IOException occurs, the connection will be marked invalid. When receiving a response, the server returns SocketTimeoutException. If a timeout is set, it will return an exception directly and clear those timed-out requests in the current connection. Otherwise, continue to send heartbeat packets (Because there may be packet loss, if the interval exceeds pingInterval, send pingoperation). If pingfails(send IOException), it means that the current connection is If there is a problem, then mark the current connection as invalid; if ping is successful, it means that the current connection is reliable and continue to read. Invalid connections will be cleared from the connection pool.
Each connection runs in a separate thread for receiving responses, and the client can do it synchronously (wait,notify) or asynchronously To make rpc calls,
serialization adopts the more efficient hession serialization method.
The server uses the event-driven NIO’s MINA framework to support high concurrency and high throughput requests.

In most database sharding solutions, in order to improve the throughput of the database, the first step is to vertically segment different tables into different In the database,
Then when a table in the database exceeds a certain size, the table needs to be split horizontally. The same is true here. Here we take the user table as an example;
For clients accessing the database, it needs to be based on the user's ID, locate the data that needs to be accessed;
data segmentation algorithm,
does hash operation based on the user’s ID, consistency Hash, this method has the problem of migrating invalid data, The service is unavailable during the migration period
Maintain the routing table, which stores the mapping relationship between users and sharding. Sharding is divided into leader and replica, which are responsible for writing and reading respectively
In this way, each biz client needs to maintain all sharding connection pools. This has the disadvantage that it will cause a full connection problem;
A solution The sharding of sharding is done at the business service layer, and each business node only maintains one shard connection.
See the picture (router)

The implementation of the routing component is like this (availability, high performance, high concurrency)
Based on performance considerations, MongoDB Maintain the relationship between user id and shard. In order to ensure availability, build a replicatset cluster.
biz’s sharding and database’s sharding are in one-to-one correspondence, and only access one database sharding.
bizBusiness registration node arrives zookeeperup/bizs/shard/down.
router monitors zookeeper on /bizs/under node status, caches online biz in router.
Whenclient requests router to obtain biz, router first obtains the user's corresponding shard from mongodb, router obtains the biz node through the RR algorithm based on the cached content.
In order to solve the availability and concurrency throughput issues of router, make router redundant while clientlistenzoo keeper’s/routers Node and cache online routernode list.
The traditional way to implement HA is generally to use virtual IPdrift, combined with Heartbeat, keepalived and other implementationsHA ,
Keepalived uses vrrp to forward data packets, providing 4 layer load balancing, switching by detecting vrrp packets, and doing redundant hot backup More suitable to match with LVS. linux Heartbeat is a high-availability service based on network or host. HAProxy or Nginx can forward data packets based on the 7 layer, so Heatbeat is more suitable for HAProxy, Nginx, including High availability of business.
In a distributed cluster, you can use zookeeper Coordination to achieve cluster list maintenance and invalidation Notification, the client can choose the hash algorithm or roudrobin to achieve load balancing; for the master-master mode and master-slave mode, they can be supported through the zookeeper distributed lock mechanism.
For asynchronous interaction between various systems of the platform, it is carried out through the MQ component.
When designing message service components, message consistency, persistence, availability, and a complete monitoring system need to be considered.
There are two main open source message middlewares in the industry: RabbitMQ and kafka,
RabbitMQ,follows the AMQP protocol and is developed by the inherently high-concurrency erlannglanguage; kafka is Linkedinopened in 2010year12month open source message publishing and subscription system,it is mainly used for processing Active streaming data,data processing of large amounts of data.
A response confirmation mechanism is required in situations where message consistency is relatively high, including the process of producing messages and consuming messages; however, responses caused by network and other principles Missing may lead to duplication of messages, which can be judged and filtered based on idempotence at the business level; RabbitMQ adopts this method. There is also a mechanism where the consumer brings the LSN number when pulling messages from broker, and pulls messages in batches from a certain LSN point in broker, so that no response mechanism is needed, kafka is in the middle of distributed messages That's how it works.
The storage of messages in broker, based on the message reliability requirements and comprehensive measurement of performance, can be in memory or persisted to storage.
For availability and high throughput requirements, both cluster and active-standby modes can be applied in actual scenarios. The RabbitMQ solution includes ordinary cluster and higher availability mirror queue methods. kafka uses zookeeper to manage the broker and consumer in the cluster. You can register topic to zookeeper; through the coordination mechanism of zookeeper, producer saves the broker corresponding to topic Information can be sent to broker randomly or in a polling manner; and producer can specify shards based on semantics, and messages can be sent to a certain shard of broker.
Generally speaking, RabbitMQ is used for real-time messaging that requires relatively high reliability. . kafka is mainly used to process active streaming data and data processing of large amounts of data. 5) Cache & Buffer Pressure can greatly improve the throughput of the system, such as usually adding cache cache before database storage.
But the introduction of the cache architecture inevitably brings about some problems, cachehit rate issues, jitter caused by cachefailure, cache and storage consistency. The data in
Cache is limited after all compared to storage. The ideal situation is the hot data of the storage system, which can be eliminated by using some common algorithms LRU etc. Old data; as the system scale increases, a single node cache cannot meet the requirements, so a distributed Cache needs to be built; in order to solve the jitter caused by the failure of a single node, distributed cache generally uses consistency hash This solution greatly reduces the jitter range caused by the failure of a single node; and for scenarios with relatively high availability requirements, each node needs to be backed up. The data has the same backup in both cache and storage, so there must be consistency issues. If the consistency is relatively strong, update the database cache at the same time. For those with low consistency requirements, you can set a cache expiration time policy.
MemcachedAs a high-speed distributed cache server, the protocol is relatively simple and is based on the event processing mechanism of libevent. The
Cache system is used in the client of the router system in the platform. The hotspot data will be cached on the client. When the data access fails, the router system will be accessed.
Of course, currently more in-memory databases are used for cache, such as Redis, mongodb; redis has richer data operations than memcacheAPI; redis Both and mongodb persist data, but memcache does not have this function, so memcache is more suitable for caching data on relational databases.
BufferSystem
Used in high-speed write operation scenarios, some data in the platform needs to be written to the database , and the data is divided into databases and tables, but the reliability of the data is not that high. In order to reduce the write pressure on the database, batch write operations can be adopted.
Open a memory area. When the data reaches a certain threshold of the area, such as 80%, do the sub-library sorting work in the memory (memory speed is still relatively fast), and then flush the sub-library in batches.
Search is a very important function in e-commerce platforms. It mainly includes search word category navigation, automatic prompts and search sorting functions.
The main open source enterprise-level search engines include lucene and sphinx. I will not discuss which search engine is better here. However, in addition to the basic functions that need to be supported when choosing a search engine, you need to consider the following two non-functional aspects:
a. Does the search engine support distributed indexing and search to cope with massive data, support read-write separation, and improve availability?
b. Real-time indexing
c. Performance
Solr is a high-performance full-text search server based on lucene. It provides a richer query language than lucene, is configurable and extensible, and provides external interfaces in XML/JSON format based on the http protocol. .
Starting from the Solr4 version, the SolrCloud method is provided to support distributed indexing and automatically perform shardingdata sharding; through each sharding’s master-slave (leader, replica) mode improves search performance; use zookeeper to manage the cluster, including leader election, etc., to ensure the availability of the cluster.
LuceneThe indexed Reader is based on the index snapshot, so it must be in the index commit After , reopen a new one Only by taking a snapshot can you search for newly added content; and indexing commit is very performance-intensive, so the efficiency of real-time index search is relatively low.
For the real-time performance of index search, Solr4’s previous solution was to combine full file indexing and memory incremental index merging, see the figure below.

Solr4 provides a solution for NRT softcommit. softcommit can search for the latest changes to the index without submitting the index operation, but the changes to the index are not sync commit to hard disk storage. If an accident occurs and the program ends abnormally, the data that has not been committed will be lost, so you need to perform commit operations regularly.
The indexing and storage operations of data in the platform are asynchronous, which can greatly improve availability and throughput; only index operations are performed on certain attribute fields and the identification of the data is storedkey , reduce the size of the index; data is stored in distributed storage Hbase . hbase does not support secondary index search well, but it can be combined with Solr search function to perform multi-dimensional retrieval statistics.
The consistency of index data andHBasedata storage, that is, how to ensure that the data stored in HBase has been indexed, you can use the confirm confirmation mechanism by establishing before indexing The data queue to be indexed. After the data storage and indexing are completed, the data is deleted from the data queue to be indexed.
7) Log collectionDuring the entire transaction process, a large number of logs will be generated, and these logs need to be collected and stored in a distributed storage system to facilitate centralized query and Analysis and processing.The log system needs to have three basic components, namely agent (encapsulating the data source and sending the data in the data source to collector), collector (receiving data from multiple agent and summarizing it Import the store in the backend), store (the central storage system should be scalable and reliable, and should support the currently very popular HDFS).
The most commonly used open source log collection systems in the industry are cloudera’s Flume and facebook’s Scribe, among which FlumeCurrent Version FlumeNG has made major architectural changes to Flume.
When designing or making technical selection of a log collection system, it is usually necessary to have the following characteristics:
a. The bridge between the application system and the analysis system will The relationship between them is decoupled
b, distributed and scalable, with high scalability. When the amount of data increases, it can be expanded horizontally by adding nodes
The log collection system is scalable and can be used at all levels of the system. Scalable, data processing does not require state, and scalability is relatively easy to achieve.
c, Near real-time
In some scenarios with high timeliness requirements, it is necessary to collect logs in time for data analysis;
General log files will be rolled regularly or quantitatively, so real-time detection Generate log files, perform similar tail operations on log files in a timely manner, and support batch sending to improve transmission efficiency; the timing of batch sending needs to meet the requirements of the number of messages and time interval.
d, Fault tolerance ScribeThe fault tolerance consideration is that when the back-end storage system crash, scribe will write the data to the local disk. When the storage system returns to normal, scribeReload logs into the storage system.
FlumeNGachieves load balancing and failover through Sink Processor. Multiple Sink can form a Sink Group. A Sink Processor is responsible for activating a Sink from a specified Sink Group. Sink Processor can achieve load balancing through all Sink in the group; it can also be transferred to another when one Sink fails.
e, Transaction support Scribedoes not consider transaction support.
Flumerealizes transaction support through the response confirmation mechanism, see the picture below,

FlumeNG's channel can be based on memory and file persistence mechanisms based on different reliability requirements. Memory-based data transmission has higher sales, but after the node goes down, the data is lost and cannot be recovered; while file persistence Downtime can be recovered.
g, Regular and quantitative archiving of data
After the data is collected by the log collection system, it is generally stored in a distributed file system such as Hadoop. In order to facilitate subsequent processing and analysis of the data, timing (TimeTrigger )or quantitative(SizeTrigger’s rollingFile of distributed system.
In a trading system, it is usually necessary to synchronize heterogeneous data sources, usually There are data files to relational databases, data files to distributed databases, relational databases to distributed databases, etc. Synchronization of data between heterogeneous sources is generally based on performance and business needs. Data storage in local files is generally based on performance considerations. Files are stored sequentially, so the efficiency is relatively high; data synchronization to relational data is generally It is based on query requirements; while distributed databases store more and more massive data, relational databases cannot meet large data storage and query requests.
In the design of data synchronization, the issues of throughput, fault tolerance, reliability, and consistency need to be comprehensively considered.
Synchronization is divided into real-time incremental data synchronization and offline full data. Let’s introduce it from these two dimensions,
Real-time increments are generally Tail files to track file changes in real time, and export to the database in batches or multi-threads , The architecture of this method is similar to the log collection framework. This method requires a confirmation mechanism, including two aspects.
One aspect is that Channel needs to confirm to agent that it has received data records in batches, and send LSN number to agent, so that when agent fails and recovers, it can use this LSN Click start tail; Of course, for the problem of allowing a small amount of duplicate records ( occurs when channel confirms to agent, agentis down and does not receive the confirmation message ), it needs to be in the business scenario judge.
Another aspect is sync to channel Confirm that the batch writing to the database has been completed, so channel You can delete this part of the message that has been confirm.
Based on reliability requirements, channel can use file persistence.
See the picture below

The full offline version follows the principle of exchanging time between spaces and divide and conquer to shorten the data synchronization time as much as possible and improve the efficiency of synchronization.
It is necessary to segment the source data such as MySQL, read the source data concurrently with multiple threads, and write the source data concurrently in batches with multiple threads such as HBase. Use channel as a buffer between reading and writing to achieve better Decoupling, channel can be based on file storage or memory. See the picture below:

For the segmentation of source data, if it is a file, you can set the block size according to the file name.
For relational databases, since the general requirement is to synchronize data offline for a period of time only(For example, synchronizing the order data of the day to HBase in the early morning), so it is necessary to segment the data according to the number of rows( ), multi-threads will scan the entire table (build index in time, and also need to return the table ), for the table containing a large amount of data, IO is very high and the efficiency is very low; here is the solution It is to create partitions for the database according to the time field ( synchronized according to time ) , and export according to the partition each time.
from traditional relational database-based parallel processing clusters for near real-time in-memory computing to the current -based Hadoop's massive data analysis, data analysis is widely used in large e-commerce websites, including traffic statistics, recommendation engines, trend analysis, user behavior analysis, data mining classifiers, distributed indexes, etc. etc.
There are commercial EMC Greenplum parallel processing clusters. The architecture of Greenplum adopts MPP (Massively Parallel Processing), a distributed database based on postgresql for large data storage.
In terms of memory computing, there are SAP’s HANA, and the open source nosqlmemory database mongodb also supports mapreduce for data analysis.
Offline analysis of massive data is currently widely used by Internet companies Hadoop, Hadoop has irreplaceable advantages in scalability, robustness, computing performance and cost, it is a fact The big data analysis platform
Hadoop, which has become the mainstream of current Internet companies, is used to process large-scale data through the distributed processing framework of MapReduce, and the scalability is also very good; but the biggest shortcoming of MapReduce It is a scenario that cannot meet real-time requirements and is mainly used for offline analysis.
Based on MapRducemodel programming for data analysis, the development efficiency is not high. The emergence of Hive located on top of hadoop makes data analysis similar to writing sql. sql undergoes syntax analysis, After generating the execution plan, the MapReduce task is finally generated for execution, which greatly improves the efficiency of development and enables analysis in the ad-hoc (calculation when query occurs) method.
The analysis of distributed data based on the MapReduce model is all offline analysis, and the execution is all brute force scanning, and cannot use mechanisms similar to indexes. ; The open source Cloudera Impala is based on the MPP parallel programming model. The underlying layer is a high-performance real-time analysis platform stored in Hadoop, which can greatly reduce the delay of data analysis.
The version currently used by Hadoop is Hadoop1.0. On the one hand, the original MapReduce framework has a single point problem with JobTracker. On the other hand, JobTracker doing Resource management also performs task scheduling. As the amount of data and Job tasks increase, there are obvious bottlenecks in scalability, memory consumption, thread model, reliability and performance; Hadoop2.0 yarn reconstructed the entire framework, separated resource management and task scheduling, and solved this problem from the architectural design.
Refer to the architecture of Yarn
In the Internet field, real-time computing is widely used in real-time monitoring analysis, flow control, risk control and other fields. The e-commerce platform system or application needs to undergo real-time filtering and analysis of the large amount of logs and abnormal information generated daily to determine whether early warning is needed;
At the same time, it is necessary to implement a self-protection mechanism for the system, such as controlling the flow of modules to prevent Unexpected system paralysis caused by excessive pressure on the system. When the traffic is too large, mechanisms such as rejection or diversion can be adopted; some businesses require risk control. For example, some businesses in the lottery need to limit numbers based on the real-time sales of the system. and allocate numbers.
The original calculation was based on a single node. With the explosive generation of system information and the increase in calculation complexity, the calculation of a single node can no longer meet the requirements of real-time calculation. Multi-node distributed calculation is required, and distributed real-time The computing platform emerged.
The real-time computing mentioned here is actually streaming computing. The predecessor of the concept is actually CEPcomplex event processing. Related open source products such as Esper, industry distributed stream computing products Yahoo S4, Twitter storm, etc. stormopen source products are the most widely used.
For the real-time computing platform, the following factors need to be considered from the architectural design:
1. Scalability
As the business volume increases and the amount of calculation increases, by increasing node processing, It can be processed.
2. High performance, low latency
From data flowing into the computing platform to calculating the output results, it needs to be efficient and low-latency to ensure that messages are processed quickly and achieve real-time calculations.
3. Reliability
Ensure that each data message is processed completely once.
4. Fault tolerance
The system can automatically manage node downtime and failure, which is transparent to the application.
Twitter’s Storm does better in the above aspects. Let’s briefly introduce the architecture of Storm.

The entire cluster is managed through zookeeper.
The client submits the topology to nimbus.
NimbusEstablish a local directory for this topology, calculate task based on the configuration of topology, allocate task, and establish assignmentsnode storage task and supervisor on zookeeper Machine Correspondence of woker in the node.
Create taskbeatsnodes on zooke eper to monitor task heartbeat; start topology.
Supervisor go to zookeeper to get the assigned tasks, start multiple woker to proceed, each woker generates task, one taska thread ; Based on the topology information, the connection between task is established ; the connection between Task and Task is managed through zeroMQ; after , the entire topology is running.
Tuple is the basic processing unit of the stream, which is a message, Tuple is in task In the middle of the transfer, the sending and receiving process of Tuple is as follows:
Sending Tuple, Worker provides a transfer function for the current task to transfer tuple Send it to other task. With the purpose taskid and tuple parameters, serialize the tuple data and put it into the transfer queue.
Before the 0.8 version, this queue was LinkedBlockingQueue, and after 0.8 it was DisruptorQueue.
After version 0.8, each woker is bound to an inbound transfer queue and an outbond queue, inbound queue is used to receive message , outbond queue is used to send messages.
When sending a message, a single thread pulls data from transferqueue and passes this tuple through zeroMQ Send to other woker middle.
receives Tuple, Every woker will listen to zeroMQ’s tcp port to receive messages, and the messages are placed in DisruptorQueue After middle, after from queue Obtain message(taskid,tuple) in , and route it to task for execution based on the value of purpose taskid, tuple. Each tuple can be emit to direct steam, or can be sent to regular stream, in Reglular mode, by Stream Group(stream id-->component id-- >outbond tasks) function completes the destination of the current tuple to be sent. As you can see from the above analysis,
StormIn terms of scalability, fault tolerance, and high performance, it is supported from the perspective of architectural design; at the same time, in terms of reliability, Storm’s ack component uses the XOR xor algorithm to ensure that every while the message is fully processed.
11) Real-time push
real-time chat, etc. There are many technologies to achieve real-time push, including the
Comet method, the websocket method, etc. Comet"Server Push" technology based on long server connection, including two types: Long Polling: The server hangs after receiving the request, and when there is an update, the connection is returned and disconnected, and then the client initiates a new one Connection Streammethod: The connection will not be closed each time the server data is transmitted. The connection will only be closed when a communication error occurs or when the connection is reestablished (some firewalls are often set to discard overly long connections, the server The client can set a timeout period, and after the timeout, the client will be notified to re-establish the connection and close the original connection). Websocket: Long connection, full-duplex communication is a new protocol of HTML5. It implements two-way communication between the browser and the server. In webSocket API , the browser and the server only need to pass a handshake action to form a fast two-way channel between the browser and the client, so that data can be quickly transmitted in both directions. Socket.io is a NodeJS websocket library, including client-side js and server-side nodejs, used to quickly build real-time web applications. To be added Database storage is roughly divided into the following categories, including relational (transactional) databases, to Oracle, mysql are represented, there are keyvaluedatabases, represented by redis and memcached db, there are document databases such as mongodb, columnar distributed databases such as HBase, cassandra, Represented by dynamo, there are other graph databases, object databases, xml databases, etc. The business fields of each type of database application are different. The following is an analysis of the performance, availability and other aspects of related products from the three dimensions of memory, relational and distributed. In-memory database aims at high concurrency and high performance, is not so strict in terms of transactionality, and is open source nosqldatabasemongodb, redisfor example Ø Mongodb communication method multi-threading method, the main thread monitors new connections, and after connection, starts a new thread to do Data operations (IO switching). Data structure Database-->collection-->record MongoDB is divided by namespace on data storage, a collection is a Namespace, an index is also a namespace. Data in the same namespace is divided into many Extent, and Extent are connected using a doubly linked list. In each Extent, specific data of each row is saved, and these data are also connected through two-way links. The data storage space of each row not only includes the space occupied by the data, but may also include a part of additional space, which allows the position to not be moved after the data update becomes larger. The index is implemented in the BTree structure. If you enable jorunalinglog, there will also be some files that store all your operation records. Persistent storage MMap method maps the file address to the memory address space. You can operate the file by directly operating the memory address space, without calling write, read operations. Performance comparison high. mongodb calls mmap to map the data in the disk to the memory, so there must be a mechanism to flush data to the hard disk at all times to ensure reliability. How often to flush is related to the syncdelay parameter. journal (used for recovery) is the redo log in Mongodb, while Oplog is responsible for replication binlog. If journal is turned on, even if the power is cut off, only 100ms of data will be lost, which is tolerable for most applications. From 1.9.2+, mongodb will turn on the journal function by default to ensure data security. Moreover, the refresh time of journal can be changed, within the range of 2-300ms, use the --journalCommitInterval command. The time for Oplog and data to be refreshed to the disk is 60s. For replication, there is no need to wait for oplog to refresh the disk, it can be copied directly to the Sencondary node in memory. Transaction support Only supports pair Atomic operations of single row records HA clusters Replica Sets, which use election algorithms to automatically conduct leader elections, while ensuring availability, they can be strong Consistency requirements. mongodb also provides a data sharding architecture Sharding. communication method CPU switching overhead, so it is a single-threaded mode (the logical processing thread and the main thread are one). reactor mode, implement your own multiplexing NIO mechanism (epoll, select, kqueue, etc.) Single thread processing multi-tasking Data structure hash+bucket structure, when the length of the linked list is too long, migration measures will be taken (expand the original twice the hash table, migrate the data there, expand+rehash) Persistent storage a, full persistence RDB (traverse redisDB, read key, value in bucket), save command blocks the main thread, bgsaveStart the sub-process to perform snapshotpersistence operation and generate rdbfile. When shutdown, the save operation will be called When the data changes, how many seconds will it trigger? bgsave sync, master accepts commands from slave b, incremental persistence (aofsimilar to redolog), write it first Log buffer , then flush into the log file (the strategy of flush can be configured, and it can be single or in batches). Only the flush to the file is actually returned to the client. The aof file and the rdb file must be merged regularly (during the snapshot process, the changed data is first written to aof buf and the child process is completed After taking the snapshot <memorysnapshot>, merge the changed parts of aofbuf and the full image data). 12) Recommendation engine
6. Data storage
1) In-memory database

In high concurrent access mode, RDB mode causes obvious jitters in the performance indicators of the service. aof is better than RDB in terms of performance overhead, but it recovers The time to reload into memory is proportional to the amount of data.
ClusterHA
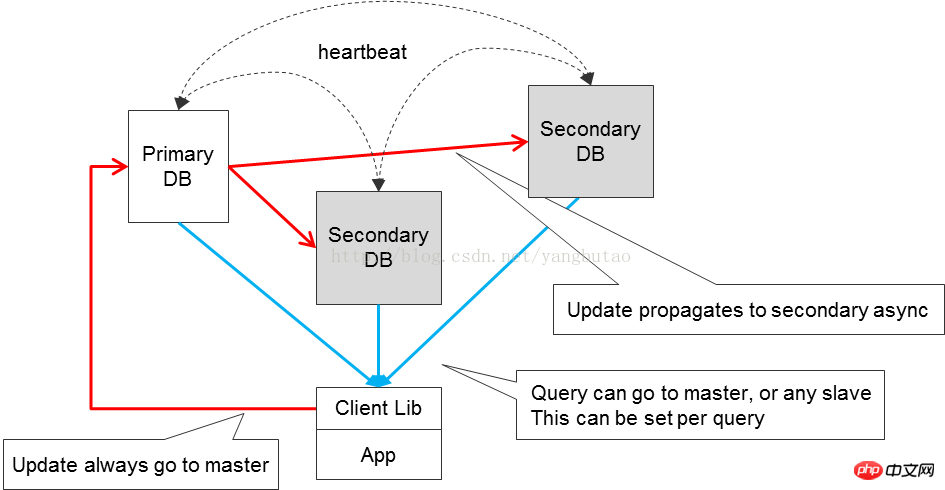
The common solution is master-slave backup switching, using HA software so that the failed master redis can be quickly switched to the slave redis. The master-slave data synchronization adopts the replication mechanism, and this scenario can separate reading and writing.
Currently, in terms of replication, a problem is that when the network is unstable, Slave and Master are disconnected (including flash interruptions), which will cause Master to need to transfer memory All the data in the rdb file (snapshot file) is regenerated and then transferred to Slave. After Slave receives the rdb file passed by Master, it will clear its own memory and reload the rdb file into the memory. This method is relatively inefficient. In the future version Redis2.8, the author has implemented part of the copy function.
Relational databases need to meet transactionality while meeting concurrency performance. mysqldatabase Take an example to describe the architectural design principles, performance considerations, and how to meet availability requirements.
Ø The architectural principle of mysql(innodb)
In terms of architecture, mysql is divided into the server layer and the storage engine layer.
ServerThe architecture of the server layer is the same for different storage engines, including connection/thread processing, query processing (parser, optimizer) and other system tasks. There are many types of storage engine layers. mysql provides a plug-in structure of storage engines and supports multiple storage engines. The most widely used ones are innodb and myisamin; inodb is mainly for OLTP applications , supports transaction processing, myisam does not support transactions, table locks, and operates quickly on OLAP.
The following mainly introduces theinnodb storage engine.

In terms of thread processing, Mysql is a multi-threaded architecture, consisting of a master thread, a lock monitoring thread, an error monitoring thread, and multiple IO threads. And a thread will be opened for a connection to serve. io threads are divided into insert buffer to save random IO, redo log similar to oracle for transaction control, and multiple write, multiple read hard disks and memory Exchanged IO threads. In terms of memory allocation, including innodb buffer pool , and log buffer. Among them, innodb buffer pool includes insert buffer, datapage, index page, data dictionary, and adaptive hash. Log buffer is used to cache transaction logs to improve performance.
In terms of data structure, innodb includes table spaces, segments, regions, pages / blocks, and rows. The index structure is a B+tree structure, including a secondary index and a primary key index. The leaf node of the secondary index is the primary key PK, and the leaf node indexed according to the primary key points to the stored data block. This B+tree storage structure can better meet the random query operation IO requirements. It is divided into data pages and secondary index pages. Modifying the secondary index pages involves random operations. In order to improve the performance during writing, adopt insert buffer does sequential writing, and then the background thread merges multiple inserts into the secondary index page at a certain frequency. In order to ensure the consistency of the database(memory and hard disk data files), and shorten the instance recovery time, the relational database also has a checkpoint function, which is used to convert the previous dirty pages in the memory buffer according to the The ratio
( old LSN) is written to the disk, so that the LSN previous logs of the redolog file can be overwritten and recycled; during failure recovery, only LSN points need to be clicked from the log Just restore it. In terms of transaction feature support, relational databases need to meet ACIDfour features. Different transaction isolation levels need to be defined based on different transaction concurrency and data visibility requirements, and they are inseparable from the lock mechanism for resource contention. , to avoid deadlocks, mysql performs concurrency control at the Server layer and storage engine layer, mainly reflected in read-write locks. Depending on the lock granularity, there are various levels of locks (table locks, row locks, page locks Lock, MVCC); Based on the consideration of improving concurrency performance, multi-version concurrency control MVCC is used to support transaction isolation, and is implemented based on undo. When doing transaction rollback, undo will also be used part. mysql Use redolog to ensure the performance of data writing and failure recovery. When modifying data, you only need to modify the memory, and then record the modification behavior to the transaction log (Sequential IO) , without the need to The data modification itself is persisted to the hard disk(randomIO), greatly improving performance. at In terms of reliability, the innodb storage engine provides a twice-write mechanismdouble writer Used to prevent errors on flush pages to storage and solve the problem of disk half-writern. Ø For high concurrency and high performance mysql, performance tuning can be performed in multiple dimensions. a, hardware level, log and data storage need to be separated. Logs are written sequentially, which requires raid1+0 and use buffer-IO; data is read and written discretely , just use direct IO to avoid the overhead caused by the file system cache. Storage capacity, SASdiskraidoperation (raidcard cache, turn off readcache, turn off disk cache, turn off read-ahead, only use writebackbuffer , but the issue of charging and discharging needs to be considered). Of course, if the data size is not large, high-speed equipment can be used for data storage, Fusion IO, SSD. For data writing, control the frequency of dirty page refresh, and for data reading, control the cache hit rate; therefore, estimate the system needs IOPS, evaluate the number of hard disks required (fusion io up to IOPS above 10w, ordinary hard disk 150). CpuIn terms of single instance, NUMA is turned off, mysql does not support multi-core very well, and CPU can be bound to multiple instances. b, operating system level, optimization of kernel and socket, network optimizationbond, file system, IOscheduling innodb Mainly used in OLTP applications are generally IOintensive applications. On the basis of improving IO capabilities, they make full use of the cache mechanism. Things that need to be considered are: On the basis of ensuring the available memory of the system, expand the innodb buffer pool as much as possible, which is generally set to 3/4 Use of the file system, only use the file system's cache when recording transaction logs; try to avoid mysql using swap (you can set vm.swappiness=0, when memory is tight, release the file system cache ) IO Scheduling optimization, reducing unnecessary blocking and reducing the latency of random IO access (CFQ, Deadline, NOOP) + d. Application level (such as index considerations, optimization with appropriate redundancy; optimizing CPU problems and memory problems caused by sql queries, reducing the scope of locks, reducing table back scans, and covering indexes) Ø In terms of high availability practice, supports the master-master and master-slave modes. In the mode, one acts as the master and is responsible for reading and writing, and the other acts as standby to provide disaster. For backup, maser-slave is one that provides write operations as the master, and several other nodes serve as read operations, supporting read and write separation. For node primary and secondary failure detection and switching, you can use HA software. Of course, you can also use zookeeper as the cluster coordination service from the perspective of more fine-grained customization. For distributed systems, the consistency of database primary and backup switching is always a problem. There are several methods: a, cluster method, such as oracle’s rack, The disadvantage is that it is more complicated b, shared SAN storage method, the relevant data files and log files are placed on the shared storage. The advantage is that the data remains consistent during the active and standby switchover and will not be lost. However, due to the standby machine being pulled up for a period of time, There will be a short-term unavailable state c, the main and backup data synchronization method, the common one is log synchronization, which can ensure hot backup and good real-time performance, but during the switch, some data may not be synchronized. , which brings about the problem of data consistency. You can record the operation log while operating the main database. When switching to standby, a check will be done with the operation log to make up for the unsynchronized data; d. Another way is to standby database Switch to the storage of regolog in the main library to ensure that data is not lost. The efficiency of database master-slave replication is not too high on mysql. The main reason is that transactions strictly maintain the order. The index mysql includes two processes in terms of replication: log IO and relog log They are all single-threaded serial operations. In terms of data copy optimization, the impact of IO is minimized. However, as of Mysql5.6 version, parallel replication on different libraries can be supported. Ø Access methods based on different business requirements In platform business, different businesses have different access requirements, such as the two typical business users and orders, users generally Generally speaking, the total amount is controllable, but the orders are constantly increasing. For the user table, we first divide it into sub-databases, and each sharding does one master and multiple reads. Similarly, for orders, due to more needs, users query themselves. The order library also needs to be divided according to users, and supports multiple reads from one master. In terms of hardware storage, because transaction logs are written sequentially, the advantage of flash memory is not much higher than that of hard disks, so battery-protected write cache raidcard storage is adopted; for data files, whether for users or orders There will be a large number of random read and write operations. Of course, increasing the memory is one aspect. In addition, high-speed IO device flash memory can be used, such as PCIecard fusion-io. The use of flash memory is also suitable for single-threaded workloads, such as master-slave replication. You can configure fusion-IO cards on the slave nodes to reduce replication latency. For order business, the volume is constantly increasing, PCIe card storage capacity is relatively limited, and the hot data of order business is only for the recent period(For example, recently 3months), here are two solutions. One is the flashcache method, which uses an open source hybrid storage method based on flash memory and hard disk storage to store hotspot data in flash memory. Another method is to regularly export old data to the distributed database HBase. When users query the order list, the recent data is obtained from mysql. Old data can be queried from HBase. Of course, is required. HBase's well-designed rowkey is designed to suit query needs. For high-concurrency access to data, traditional relational databases provide a read-write separation solution, but it brings about data consistency problems and provides a data segmentation solution; for more and more For large amounts of data, traditional databases use sub-databases and sub-tables, which are more complex to implement and require continuous migration and maintenance in the future. For high availability and scaling, traditional data uses master-standby, master-slave, and multi-master. solution, but its scalability is relatively poor. Adding nodes and downtime require data migration. For the problems raised above, the distributed database HBase has a complete set of solutions that are suitable for high-concurrency massive data access requirements. Ø HBase Column-based efficient storage reduces IO High performance LSM Tree Suitable for high-speed writing scenarios Strong consistent data access MVCC HBase's consistent data access is implemented through MVCC. HBaseIn the process of writing data, you need to go through several stages, writing HLog, writing memstore, and updating MVCC; To be considered a true memstore write success, the isolation of transactions needs to be controlled by mvcc. For example, reading data cannot obtain data that has not been submitted by other threads. Highly reliable HBase’s data storage is based on HDFS, which provides a redundancy mechanism. Region flushed into files. Scalable, automatic splitting, migration to locate the target , and finally locate the . Region Server is expanded by publishing itself to Master, and Master is evenly distributed. AvailabilityThere is a single point of failure. After the Region Server goes down, the maintained by the becomes inaccessible in a short period of time, waiting for the failover to take effect. maintains the health status and Region distribution of each Region Server through Master. Multiple Master, Masterdowntime has zookeeper’s paxosvoting mechanism to select the next Master. Even if Master is completely down, it will not affect the reading and writing of Region. Master only acts as an automatic operation and maintenance role. HDFS is a distributed storage engine, one backup, three backups, high reliability, 0data loss. HDFS’s namenode is a SPOF. In order to avoid too frequent access to a single region and excessive pressure on a single machine, a split mechanism HBase is written using the LSM-TREE architecture. With the data There are more and more append and HFile, HBase provides HFile file processing compact to clear expired data and improve query performance. Schema free HBaseThere is no strict schema like a relational database, you can add and delete schema freely fields in . HBase distributed database does not support secondary indexes very well. Currently it only supports indexes on rowkey, so the design of rowkey is very critical for query performance. . Unified configuration library Deployment platform Large-scale distributed systems involve various devices, such as network switches , ordinary PC machines, various types of network cards, hard disks, memories, etc., as well as application business-level monitoring. When the number is very large, the probability of errors will also increase, and some monitoring requirements are relatively timely. High, some reaching the second level; abnormal data needs to be filtered in a large number of data streams, and sometimes complex context-related calculations are performed on the data to determine whether an alarm is needed. Therefore, the performance, throughput, and availability of the monitoring platform are more important. It is necessary to plan a unified and integrated monitoring platform to monitor the system at all levels. Data classification of the platform Application business level: application events, business logs, audit logs, request logs, exceptions, request businessmetrics, performance metrics System level: CPU , memory, network, IO timeliness requirements threshold, alarm: real-time calculation: near real-time minute calculation offline analysis by hour and day real-time query Architecture The Agent agent in the node can receive logs, application events and collect data through probes. One principle of data collection by agent is to be asynchronously isolated from the business application process. Does not affect the transaction process. Data is collected uniformly through the collector cluster, and distributed to different computing clusters according to different types of data for processing; some data are not timely, such as hourly statistics, and put into the hadoop cluster; some data are requests If the circulating tracking data needs to be queryable, it can be put into the solr cluster for indexing; some data that needs to be calculated in real time and then alerted needs to be put into the storm cluster for processing. After the data is processed by the computing cluster, the results are stored in Mysql or HBase. The monitoring web application can push the real-time monitoring results to the browser, and can also provide API for display and search of results. 3) Distributed database
Usual queries do not require all fields in a row, most only require a few fields
With row-oriented storage systems, each query will Take out all the data, and then select the required fields from it
The column-oriented storage system can query a column separately, thereby greatly reducingIO
Improving compression efficiency
Data in the same column has high similarity, which will increase compression efficiency
Hbase Many of its features are determined by column storage
 through
through 7. Management and deployment configuration
8. Monitoring and statistics

The above is the detailed content of Build a high-concurrency and high-availability architecture. For more information, please follow other related articles on the PHP Chinese website!
 How to solve Java stack overflow exception
How to solve Java stack overflow exception
 es6 new features
es6 new features
 Laptop sound card driver
Laptop sound card driver
 How many types of usb interfaces are there?
How many types of usb interfaces are there?
 The installer cannot create a new system partition solution
The installer cannot create a new system partition solution
 A collection of common computer commands
A collection of common computer commands
 How to use unlocker
How to use unlocker
 vs2010 key
vs2010 key
 How to solve the problem that scanf return value is ignored
How to solve the problem that scanf return value is ignored








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



