

Installation and use of Redis

Introduction to Redis
Already have Membercache and various databases, why did Redis come about? Redis is purely for applications. It is a high-performance key-value database. The emergence of redis has largely compensated for the shortcomings of keyvalue storage such as memcached and solved the situation of complete data loss after power outage; in some cases, it can play a very good supplementary role to the relational database. Performance test results show that SET operations can reach 110,000 times per second, and GET operations can reach 81,000 times per second (of course, different server configurations have different performance).
Redis is a distributed NoSQL database system for "key/value" pair type data. It is characterized by high performance, persistent storage, and adaptability. Highly concurrent application scenarios. Similar to Memcached, it supports relatively more stored value types, including string (string), list (linked list), set (set) and zset (ordered set). These data types support push/pop, add/remove, intersection union and difference, and richer operations, and these operations are atomic and support various different ways of sorting. Like redis and memcached, in order to ensure efficiency, data is cached in memory. The difference is that redis will periodically write updated data to disk or write modification operations to additional record files, and on this basis, master-slave (master-slave) synchronization is achieved.
Redis currently provides four data types: string, list, set and zset (sorted set).
The storage of Redis is divided into three parts: memory storage, disk storage and log file. There are three parameters in the configuration file to configure it.
save seconds updates: Indicate how many update operations there are within a long period of time, and then synchronize the data to the data file.
appendonly yes/no: Whether to log after each update operation. If not turned on, it may result in data loss for a period of time during a power outage. Because redis itself synchronizes data files according to the above save conditions, some data will only exist in memory for a period of time.
appendfsync no/always/everysec: How the data cache is synchronized to disk. no means to wait for the operating system to synchronize the data cache to the disk, always means to manually call fsync() to write the data to the disk after each update operation, and everysec means to synchronize once per second.
## redis-server.exe redis server daemon startup program redis.conf redis configuration file
redis -cli.exe redis command line operation tool. Of course, you can also use telnet to operate according to its plain text protocol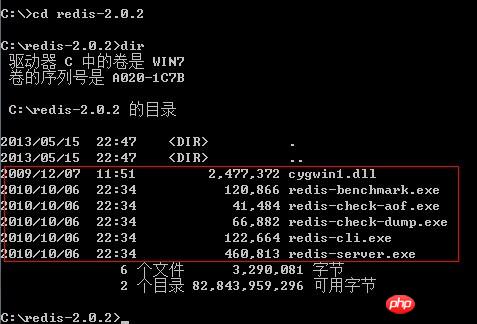 redis-check-dump.exe Local database check
redis-check-dump.exe Local database check
redis-benchmark.exe Performance test, used to simulate sending M SETs/GETs queries by N clients at the same time (similar to Apache's ab tool)
benchmark tool test information: Send 100,000 requests to the redis server, each request comes with 60 Concurrent clients
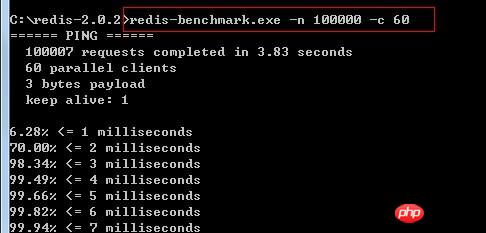
Oops, my computer was a little overwhelmed, but it finally showed that the test of 100,000 requests was completed in 4.03 seconds,
Some screenshots of the results are as follows:

Start the Redis service (conf file to set the configuration file (redis-server.exe redis.conf ), if not specified, the default is):
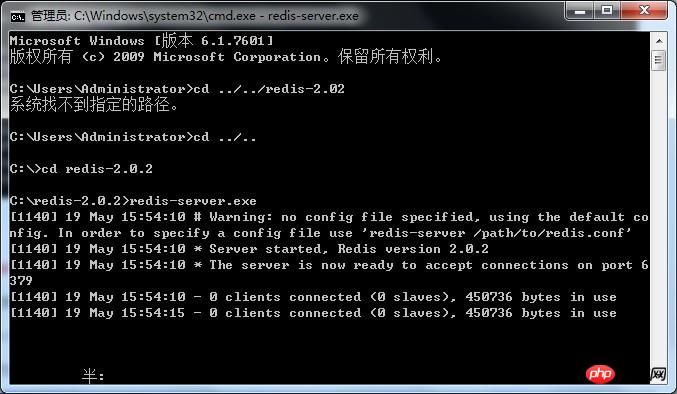
The startup cmd window should always be open. After closing, The Redis service is shut down.
At this time, the service is open. Open another cmd window to set up the client:
C:\redis-2.0.2> redis-cli.exe -h 127.0.0.1 -p 6379
Then we can enter the command we want to enter here. A very important operation of redis is set and get
The client is as follows:
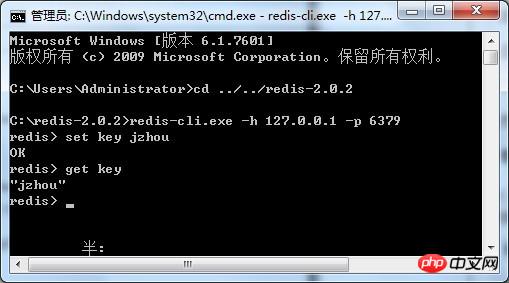
At this time, the server side (here is also the local machine) displays as follows (with A client is connected):

The key set above on the client is resident in memory, which means closing the window , the value of get key will still be "jzhou" when you open the window next time, haha.
(Note that during operation, the server must enable the service, otherwise the client cannot connect.)
Redis provides multiple languages Clients, including Java, C++, python.
The above is the detailed content of Installation and use of Redis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 PostgreSQL performance optimization under Debian
Apr 12, 2025 pm 08:18 PM
PostgreSQL performance optimization under Debian
Apr 12, 2025 pm 08:18 PM
To improve the performance of PostgreSQL database in Debian systems, it is necessary to comprehensively consider hardware, configuration, indexing, query and other aspects. The following strategies can effectively optimize database performance: 1. Hardware resource optimization memory expansion: Adequate memory is crucial to cache data and indexes. High-speed storage: Using SSD SSD drives can significantly improve I/O performance. Multi-core processor: Make full use of multi-core processors to implement parallel query processing. 2. Database parameter tuning shared_buffers: According to the system memory size setting, it is recommended to set it to 25%-40% of system memory. work_mem: Controls the memory of sorting and hashing operations, usually set to 64MB to 256M
 How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
How to optimize the performance of debian readdir
Apr 13, 2025 am 08:48 AM
In Debian systems, readdir system calls are used to read directory contents. If its performance is not good, try the following optimization strategy: Simplify the number of directory files: Split large directories into multiple small directories as much as possible, reducing the number of items processed per readdir call. Enable directory content caching: build a cache mechanism, update the cache regularly or when directory content changes, and reduce frequent calls to readdir. Memory caches (such as Memcached or Redis) or local caches (such as files or databases) can be considered. Adopt efficient data structure: If you implement directory traversal by yourself, select more efficient data structures (such as hash tables instead of linear search) to store and access directory information

 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 Understanding NoSQL: Key Features of Redis
Apr 13, 2025 am 12:17 AM
Understanding NoSQL: Key Features of Redis
Apr 13, 2025 am 12:17 AM
Key features of Redis include speed, flexibility and rich data structure support. 1) Speed: Redis is an in-memory database, and read and write operations are almost instantaneous, suitable for cache and session management. 2) Flexibility: Supports multiple data structures, such as strings, lists, collections, etc., which are suitable for complex data processing. 3) Data structure support: provides strings, lists, collections, hash tables, etc., which are suitable for different business needs.
 How to configure slow query log in centos redis
Apr 14, 2025 pm 04:54 PM
How to configure slow query log in centos redis
Apr 14, 2025 pm 04:54 PM
Enable Redis slow query logs on CentOS system to improve performance diagnostic efficiency. The following steps will guide you through the configuration: Step 1: Locate and edit the Redis configuration file First, find the Redis configuration file, usually located in /etc/redis/redis.conf. Open the configuration file with the following command: sudovi/etc/redis/redis.conf Step 2: Adjust the slow query log parameters in the configuration file, find and modify the following parameters: #slow query threshold (ms)slowlog-log-slower-than10000#Maximum number of entries for slow query log slowlog-max-len
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
 vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
vscode cannot install extension
Apr 15, 2025 pm 07:18 PM
The reasons for the installation of VS Code extensions may be: network instability, insufficient permissions, system compatibility issues, VS Code version is too old, antivirus software or firewall interference. By checking network connections, permissions, log files, updating VS Code, disabling security software, and restarting VS Code or computers, you can gradually troubleshoot and resolve issues.
