
 Backend Development
Python Tutorial
Pandas data processing example display: global listed company data collection
Backend Development
Python Tutorial
Pandas data processing example display: global listed company data collection
Pandas data processing example display: global listed company data collection
I currently have a piece of data on Forbes’ 2016 Global 2000 List of Listed Companies, but the original data is not standardized and needs to be processed before further use.
This article introduces the use of pandas for data organization through practical examples.
As usual, let me first talk about my operating environment, as follows:
windows 7, 64-bit
python 3.5
pandas 0.19.2 version
After getting the original data, let’s first take a look at the data and think about what we need data results.
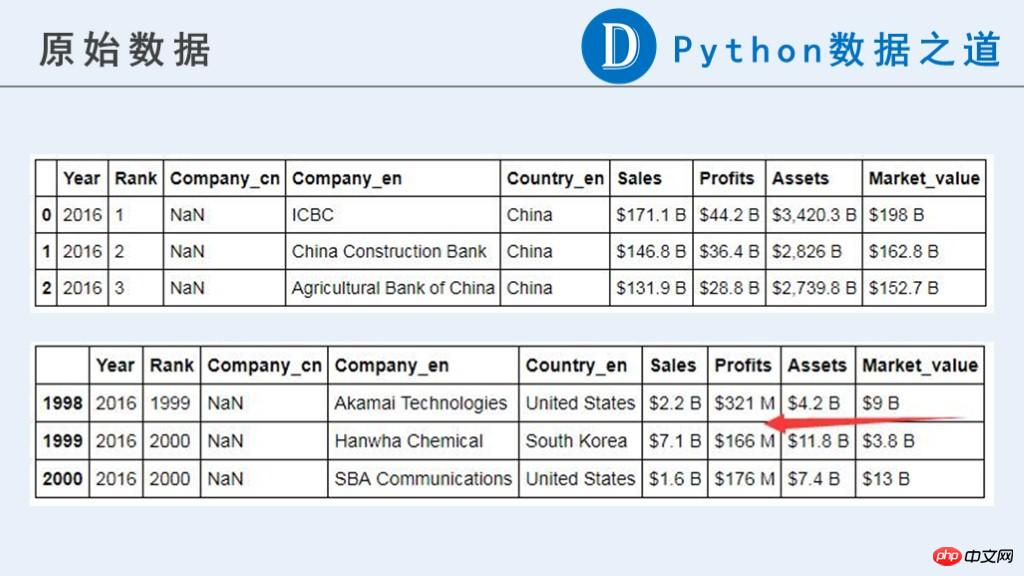
Below is the raw data:
In this article, we need the following preliminary results for future continued use.
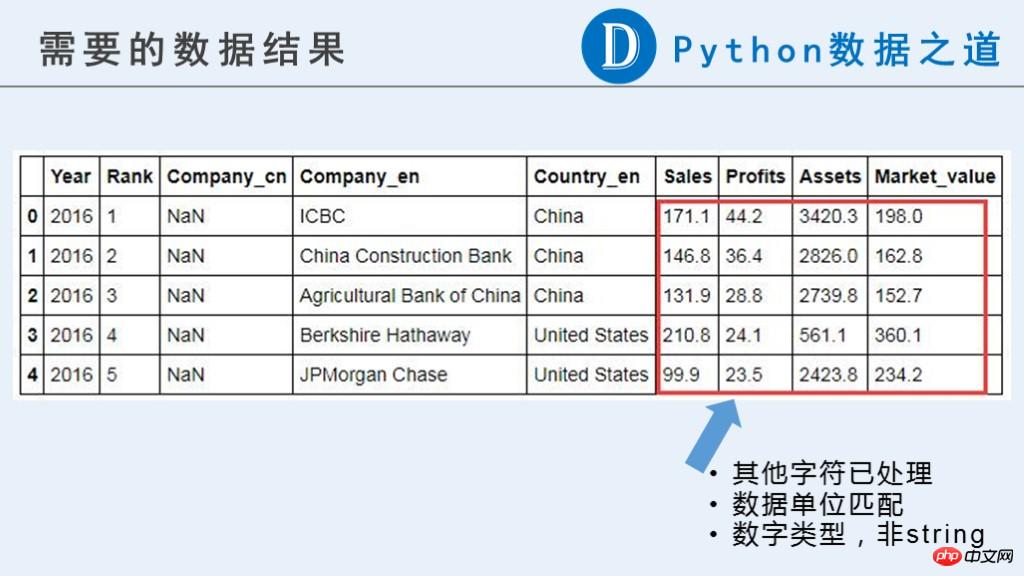
You can see that in the original data, the data related to the enterprise ("Sales", "Profits", "Assets", "Market_value") are currently Not a numeric type that can be used for calculations.
The original content contains currency symbols "$", "-", strings composed of pure letters, and other information that we consider abnormal. What's more, the units for these data are not consistent. They are represented by "B" (Billion, one billion) and "M" (Million, one million) respectively. Unit unification is required before subsequent calculations.
1 Processing method Method-1
The first processing idea that comes to mind is to split the data information into billions ('B') and millions ('M'), respectively. processed and finally merged together. The process is as follows.
Load the data and add the column name
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)Get the unit in billions ('B') Data
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_bGet data in millions ('M')
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_mThis method is easy to understand It is relatively simple, but the operation will be more cumbersome, especially if there are many columns of data to be processed, it will take a lot of time.
I won’t describe further processing here. Of course, you can try this method.
The following is a slightly simpler method.
2 Processing method Method-2
2.1 Loading data
The first step is to load data, which is the same as Method-1.
Let’s process the 'Sales' column
2.2 Replace relevant abnormal characters
First, replace the relevant abnormal characters, including the dollar currency symbol '$', the alphabetical string 'undefined', and 'B'. Here, we want to uniformly organize the data units into billions, so 'B' can be directly replaced. And 'M' requires more processing steps.
2.3 Processing data related to 'M'
Processing data containing millions of "M" units, that is, data ending with "M", the idea is as follows:
(1) Set the search condition mask;
(2) Replace the string "M" with an empty value
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
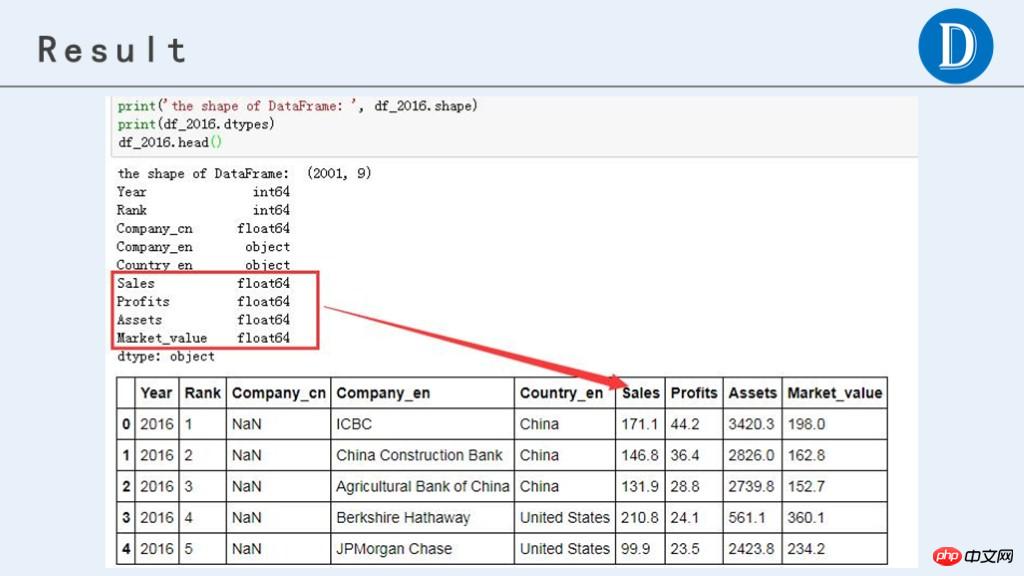
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()最终处理后,获得的数据结果如下:
The above is the detailed content of Pandas data processing example display: global listed company data collection. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1385
1385
 52
52

 Solving common pandas installation problems: interpretation and solutions to installation errors
Feb 19, 2024 am 09:19 AM
Solving common pandas installation problems: interpretation and solutions to installation errors
Feb 19, 2024 am 09:19 AM
Pandas installation tutorial: Analysis of common installation errors and their solutions, specific code examples are required Introduction: Pandas is a powerful data analysis tool that is widely used in data cleaning, data processing, and data visualization, so it is highly respected in the field of data science . However, due to environment configuration and dependency issues, you may encounter some difficulties and errors when installing pandas. This article will provide you with a pandas installation tutorial and analyze some common installation errors and their solutions. 1. Install pandas
 How to read txt file correctly using pandas
Jan 19, 2024 am 08:39 AM
How to read txt file correctly using pandas
Jan 19, 2024 am 08:39 AM
How to use pandas to read txt files correctly requires specific code examples. Pandas is a widely used Python data analysis library. It can be used to process a variety of data types, including CSV files, Excel files, SQL databases, etc. At the same time, it can also be used to read text files, such as txt files. However, when reading txt files, we sometimes encounter some problems, such as encoding problems, delimiter problems, etc. This article will introduce how to read txt correctly using pandas
 Practical tips for reading txt files using pandas
Jan 19, 2024 am 09:49 AM
Practical tips for reading txt files using pandas
Jan 19, 2024 am 09:49 AM
Practical tips for reading txt files using pandas, specific code examples are required. In data analysis and data processing, txt files are a common data format. Using pandas to read txt files allows for fast and convenient data processing. This article will introduce several practical techniques to help you better use pandas to read txt files, along with specific code examples. Reading txt files with delimiters When using pandas to read txt files with delimiters, you can use read_c
 Revealing the efficient data deduplication method in Pandas: Tips for quickly removing duplicate data
Jan 24, 2024 am 08:12 AM
Revealing the efficient data deduplication method in Pandas: Tips for quickly removing duplicate data
Jan 24, 2024 am 08:12 AM
The secret of Pandas deduplication method: a fast and efficient way to deduplicate data, which requires specific code examples. In the process of data analysis and processing, duplication in the data is often encountered. Duplicate data may mislead the analysis results, so deduplication is a very important step. Pandas, a powerful data processing library, provides a variety of methods to achieve data deduplication. This article will introduce some commonly used deduplication methods, and attach specific code examples. The most common case of deduplication based on a single column is based on whether the value of a certain column is duplicated.
 Simple pandas installation tutorial: detailed guidance on how to install pandas on different operating systems
Feb 21, 2024 pm 06:00 PM
Simple pandas installation tutorial: detailed guidance on how to install pandas on different operating systems
Feb 21, 2024 pm 06:00 PM
Simple pandas installation tutorial: Detailed guidance on how to install pandas on different operating systems, specific code examples are required. As the demand for data processing and analysis continues to increase, pandas has become one of the preferred tools for many data scientists and analysts. pandas is a powerful data processing and analysis library that can easily process and analyze large amounts of structured data. This article will detail how to install pandas on different operating systems and provide specific code examples. Install on Windows operating system
 FAQ for pandas reading txt files
Jan 19, 2024 am 09:19 AM
FAQ for pandas reading txt files
Jan 19, 2024 am 09:19 AM
Pandas is a data analysis tool for Python, especially suitable for cleaning, processing and analyzing data. During the data analysis process, we often need to read data files in various formats, such as Txt files. However, some problems will be encountered during the specific operation. This article will introduce answers to common questions about reading txt files with pandas and provide corresponding code examples. Question 1: How to read txt file? txt files can be read using the read_csv() function of pandas. This is because
 How does Golang improve data processing efficiency?
May 08, 2024 pm 06:03 PM
How does Golang improve data processing efficiency?
May 08, 2024 pm 06:03 PM
Golang improves data processing efficiency through concurrency, efficient memory management, native data structures and rich third-party libraries. Specific advantages include: Parallel processing: Coroutines support the execution of multiple tasks at the same time. Efficient memory management: The garbage collection mechanism automatically manages memory. Efficient data structures: Data structures such as slices, maps, and channels quickly access and process data. Third-party libraries: covering various data processing libraries such as fasthttp and x/text.
 Use Redis to improve data processing efficiency of Laravel applications
Mar 06, 2024 pm 03:45 PM
Use Redis to improve data processing efficiency of Laravel applications
Mar 06, 2024 pm 03:45 PM
Use Redis to improve the data processing efficiency of Laravel applications. With the continuous development of Internet applications, data processing efficiency has become one of the focuses of developers. When developing applications based on the Laravel framework, we can use Redis to improve data processing efficiency and achieve fast access and caching of data. This article will introduce how to use Redis for data processing in Laravel applications and provide specific code examples. 1. Introduction to Redis Redis is a high-performance memory data
