
Abstract: Container creation or application deployment configuration is complicated and variable. In order to ensure system flexibility and reusability, this article focuses on how to use the template engine as the core , build a unified container deployment framework.
Everyone has an experience when using containers. There are about forty or fifty container configuration items, and it requires a certain technical background to understand them. During the deployment process, users often encounter various problems when starting containers, deploying applications, or upgrading due to a lack of understanding of configuration parameters. How users can speed up their understanding of different parameters and expand accordingly according to different application types and scenarios. This article will focus on exploring and solving these problems.
Container creation or application deployment configuration is complicated and variable. In order to ensure system flexibility and reusability, we decided to build a unified container deployment framework with the template engine as the core. This article focuses on how to build a template engine and the operating principle of building a container deployment framework with the template engine as the core. In the template engine, files that comply with certain format specifications are the basis. For locations that may change or need to be changed according to the deployment process, parameters are used to identify the site. The definition of the parameter identifier is appended to the end of the template file to perform semantic transformation of the parameter identifier. The specific content of the template or parameter identification can be read or received from the client request parameters through a specific configuration file.
The template engine consists of four modules: template definition, template parsing, template conversion, and template execution. The template definition depends on the management framework of the container cluster and is a non-executable file. The template parser is responsible for dividing the template into two parts: one part forms the non-executable deployment template; the other part forms the definition description of the parameters in the deployment template. The parameter definition description is unified with the site identifier in the deployment template through a unique site identifier. One correspondence. The template converter accepts parameter values and combines them with the deployment template generated in the parser. The parameter value identifier is associated with the placeholder identifier in the template. The parameter value is replaced by the placeholder identifier to generate an executable file. The template executor is responsible for creating objects based on the template, and is generally responsible for the scheduling framework or container engine.
The execution principle of the template engine is shown in Figure 1: 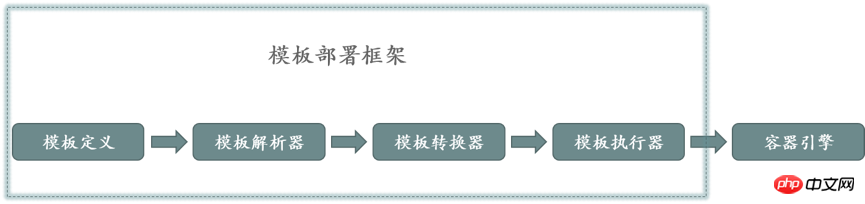
The template definition includes two types of information: deployment template; parameter identification.
Take the deployment template of kubernetes as an example. The deployment template involves four different types of definitions, namely: resources, versions, information descriptions, and data configurations.
Resource: Indicates the object type defined in kubernetes.
Version: Indicates the version of the object
Information description: Including object name, label, comments, etc., providing index for object search or scheduling.
Data configuration: Responsible for defining the standards that the container follows when it is running, including ports, environment variables, resources, scheduling, health checks, etc.
The parameter identifier consists of 6 attributes, namely parameters, name, description, displayname, value, and type.
parameters: parameter definition start flag
description: parameter prompt information
Taking the namespace object in kubernetes as an example, the complete definition of the template is as shown in the following code:
apiVersion: v1kind: Namespacemetadata:
name: ${name }
---
{"parameters":
[
{ "description": "命名空间", "displayName": "命名空间", "name": "name", "value": "", "type": "String"
}
]}The above code contains two parts: deployment template and parameter description.
The deployment template is shown in the following code block:
apiVersion: v1kind: Namespacemetadata:
name: ${name }The deployment template defines all content created by the object. The meaning of the fields in the template is described as follows:
apiVersion : Common options, defining version information
Kind: Defining object types, distinguishing different objects
Metadata: Defining parameter keys specified during deployment Value pair
${}: represents the reference value of the parameter, which can replace the parameter
parameter identifier, which defines the client’s dynamic acquisition of parameters. For the final display form, the following code example parameter identification definition:
{"parameters": [
{
"description": "命名空间",
"displayName": "命名空间",
"name": "name",
"value": "",
"type": "String"
}
]}Parameter identification defines a unified format. Through semantic transformation, complex configurations are transformed into a way that is easy for users to understand. The client reads the Parameters identifier, abstracts the input parameters through the template parser, displays the required Form form, and provides the user input function.
Template definitions are written by professionals who are familiar with Kubernetes or Docker. Real-time and dynamic adjustments can be made based on specific business scenarios to ensure deployment flexibility and scalability. At the same time, the system provides basic templates based on different objects. Users can also create and maintain templates based on a certain knowledge background.
Obtains the parameter identifiers in the template through the input and output streams, performs semantic conversion, and obtains easy-to-understand configuration parameters. The working principle of the template parser is shown in Figure 2 below:
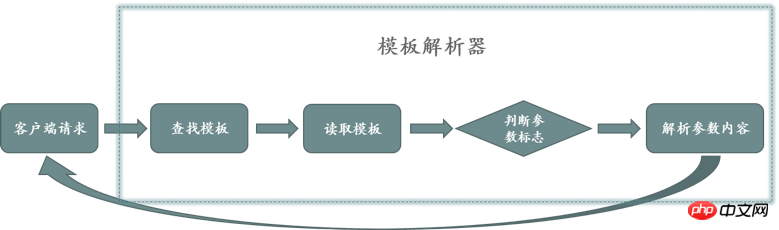
The client initiates a request to create an object. After the server receives the request, it will automatically associate the basic template according to the requested object type. The basic template is read through the file stream. During the reading process, the Parameters flag is used as the starting point to obtain parameter description information. After the parsing is completed, the parameters are returned to the client in the form of a Json string. The client dynamically generates a form that needs to be filled in by the user based on the Json string. The user completes the parameter input operation based on the content of the form.
The template parser focuses on parsing the parameter identifiers in the template definition. Through semantic transformation and information prompts, easily identifiable input items are formed. For users, complex technical indicators can be shielded after the analysis is completed, and the user's focus shifts from technology to business configuration. Minimize usage costs and increase ease of use.
The template converter is the core of the template engine and focuses on solving three problems: obtaining deployment templates, converting parameters and values, and building executable files. The client assigns real values to the parameters in the template parser and passes them to the server. The server reads the template content and ends when it encounters the flag bit of the parameter. It writes the read content to a new file through the file stream, generates a deployment file, and then Replace parameters in the deployment file with parameter values to generate the final executable file. The working principle of the template converter is shown in Figure 3:
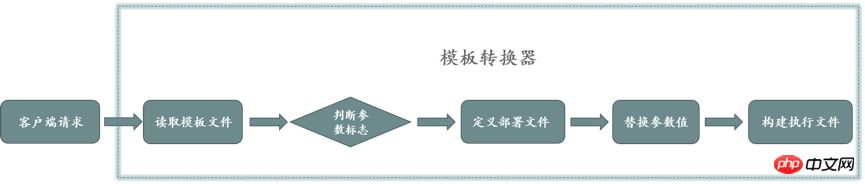
Get the deployment template: It can be seen from the template definition that the template contains two parts: deployment template and parameter identification. The template converter first needs to deploy the template and read the deployment template in the template definition through file stream. During the reading process, it is divided by parameters identifier to obtain the deployment template.
参数值转化:核心是解决参数与占位符关联和赋值问题。模板转换器通过模板参数定义的name属性key关联,模板转化器拿到参数值以后,获取参数值对应的key(key在部署模板唯一),并且根据key,替换部署模板中占位标识,完成参数替换。
构建可执行文件:通过文件流的方式,把前两部转化的字符流输出到文件,构建出可执行文件。
模板转换器执行以后,生成的可执行文件如下所示:
apiVersion: v1kind: Namespacemetadata: name: ruffy
模板执行器接收可执行的部署文件,对于文件中定义的部署类型进行解析,拆分成若干个可执行任务。容器引擎根据收到的任务执行操作,最终协同完成部署工作。模板执行器往往依赖于容器调度和执行引擎。以Kubernetes容器编排框架为例,模板转化器生成的可执行文件,以字符流的方式传输到Kubernetes的Server端,Kubernetes根据传入文件,自动解析文件内容,并且做出相关操作。对于模板引擎而言,无论是Kubernetes还是Swarmkit都能够得到友好的支持。模板执行器的工作原理如图4所示:

The result after the template executor is executed is shown in Figure 5: 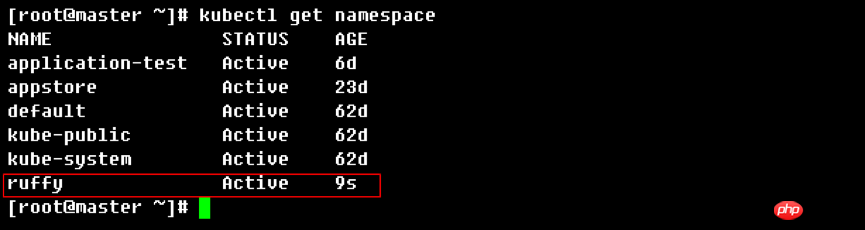
Through the template engine, the configuration of the container can be used flexibly, whether it is container deployment or other resource theme object creation, there are corresponding Template support. The template processing engine does not need to constantly modify the code according to template changes. At the same time, users can focus on configuration information from the semantics they understand, without paying attention to specific technical details and implementation methods, simplifying operating behaviors and reducing usage costs.
The above is the detailed content of PHP design pattern container deployment framework based on template engine. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



