

Redis cluster building tutorial and problem solving
This article mainly tells you how to build a redis cluster and the issues that need to be paid attention to during the process. It is very good and recommended to everyone. Friends in need can refer to it
Here , build a 6-node redis pseudo-cluster on a Linux virtual machine. The idea is very simple. Open 6 redis instances on a virtual machine, and each redis instance has its own port. In this case, it is equivalent to simulating 6 machines, and then building a redis cluster using these 6 instances.
Premise: redis has been installed, the directory is /usr/local/redis-4.0.1 If not, you can refer to the article Installing redis under windows Installing redis under Linux
redis cluster is used ruby script, so to execute the script, a ruby environment is required. Corresponding to redis-trib.rb in the src directory of the redis source code, redis-trib.rb is a tool officially launched by redis to manage redis clusters. It is based on the cluster commands provided by redis and is encapsulated into a simple, convenient and practical operating tool. so
Install ruby environment:
1.yum install ruby
2 .yum install rubygems

3.gem install redis

Centos supports ruby to 2.0.0 by default, and redis requires a minimum of 2.2.2. The solution is to install rvm first and then upgrade the ruby version to 2.3.3.
1.sudo yum install curl
2. Install rvm
##curl -L get.rvm.io | bash -s stable
source /usr/local/rvm/scripts/rvm
rvm list known
rvm install 2.3.3
rvm remove 2.0.0
ruby --version
gem install redis
redis cluster construction
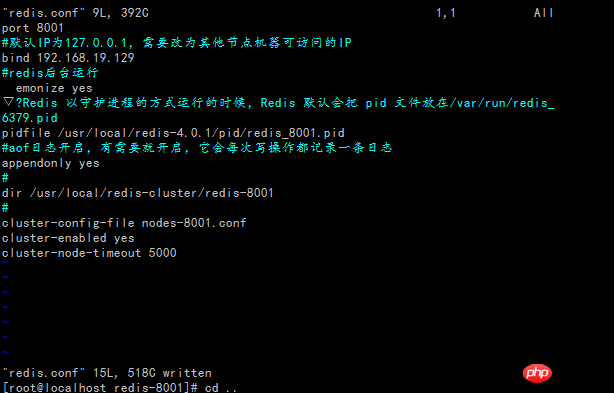
Modify the redis-conf files under the node respectively, because On a machine (192.16819.129), so each instance should have a different port; at the same time, each instance will obviously have its own place to store data; turn on AOF mode; turn on cluster configuration; turn on background mode;

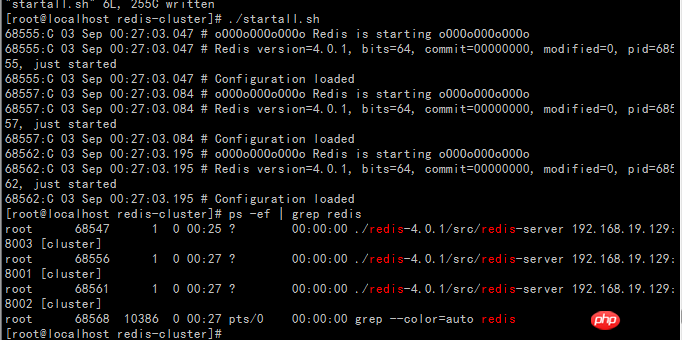
Start the redis service and see if it can be started. ok no problem.
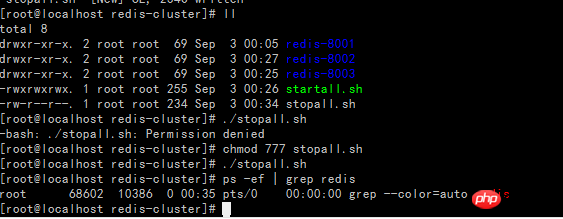
Create the startall.sh script (the prompt permission denied indicates insufficient permissions, execute the command chmod 777 startall.sh to modify the permissions)
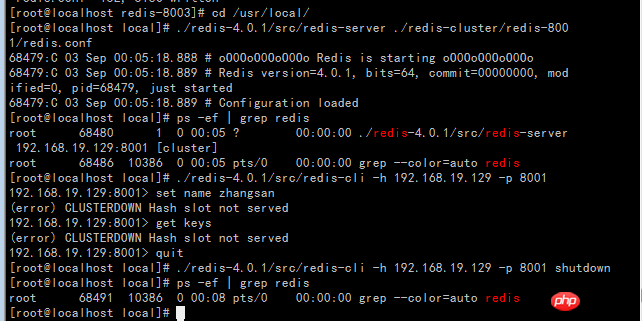
Start the startall.sh script
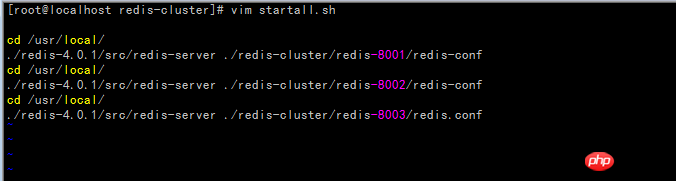
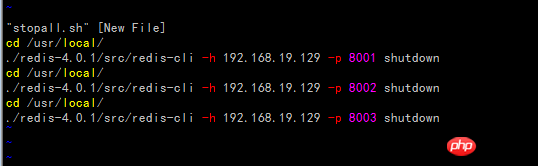
Create the stopall.sh script
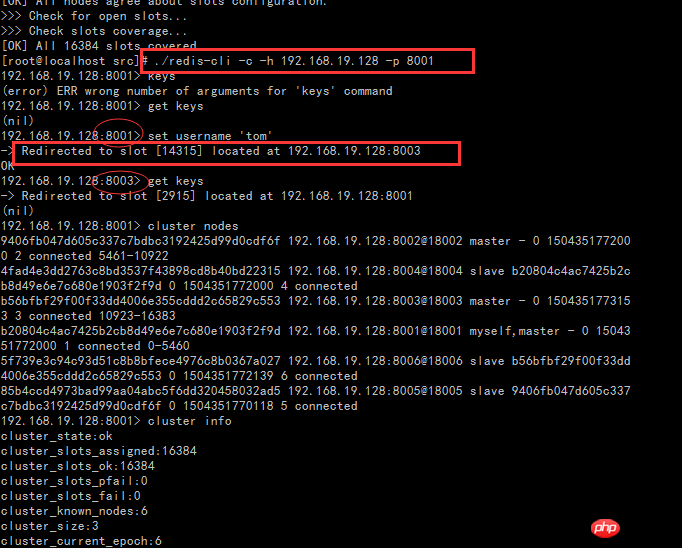
You can see that redis-trib.rb has the following functions:
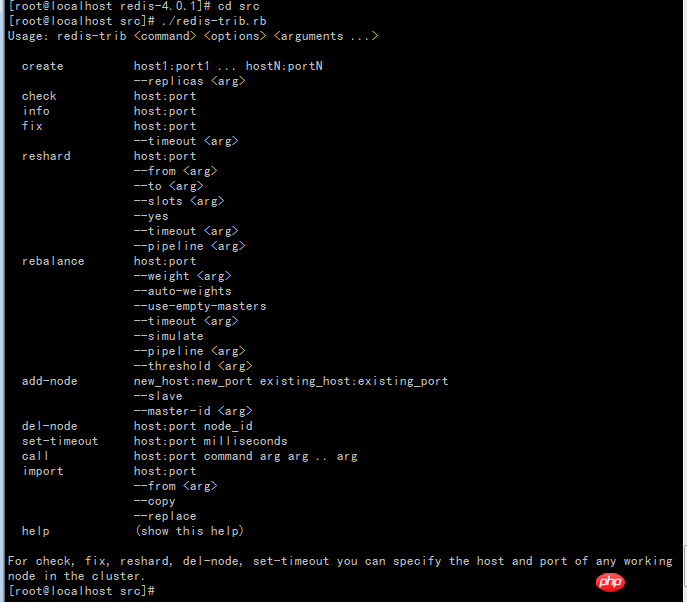
- check: Check the cluster
- info: View the cluster information
- fix: Repair the cluster
- reshard: Online migration slot
- rebalance: Balance the number of cluster node slots
- add-node: Add new nodes to the cluster
- del-node: Delete the node from the cluster
- set-timeout: Set the timeout for the heartbeat connection between cluster nodes
- call: Execute the command on all nodes in the cluster
- import: Import external redis data into the cluster
redis-trib.rb mainly has two classes: ClusterNode and RedisTrib. ClusterNode saves the information of each node, RedisTrib is the implementation of each function of redis-trib.rb

Note: It prompts at least 3 master cluster nodes. It was said that 6 are created before, but in actual operation I only created 3 nodes, so it can be concluded that when we create a redis cluster, we need at least three master nodes, and it should be an odd number, so, no Be lazy and create three more.
Special note: The key here is the optional replicas parameter. --replicas 2 means to allocate 2 slaves to each master. replicas means how many slaves are needed. It can be successfully created without filling in this parameter, so there are three masters. We will introduce the replicas parameter later
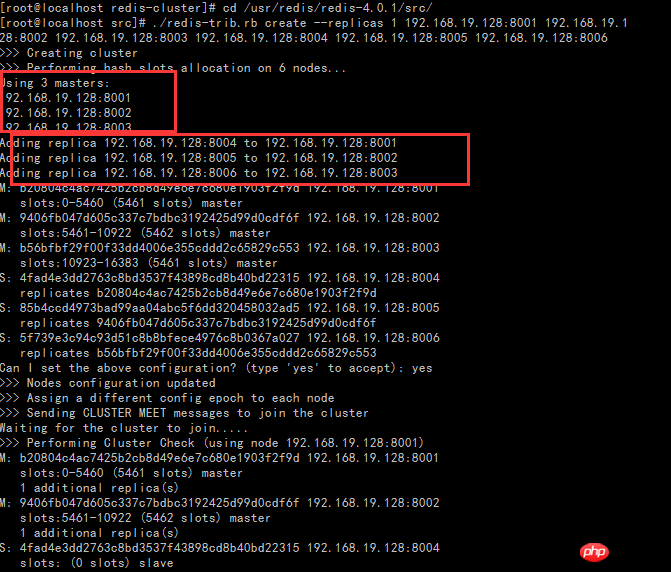
First of all, --replicas 1 1 actually represents a ratio, which is the number of master nodes/ The proportion of slave nodes. So think about it, when creating a cluster, which nodes are the master nodes? Which nodes are slave nodes? The answer is that the order of IP:PORT in the command will be followed, first 3 master nodes, then 3 slave nodes.
Secondly, pay attention to the concept of slot in the picture. For Redis cluster, slot is a place to store data, it is a slot. For each Master, there will be a slot range, but the Slave does not. In the Redis cluster, the Master can still read and write, while the Slave can only read. The writing of data is actually distributed and stored in slots, which is different from the previous master-slave mode of 1.X (Master/Slave data storage in master-slave mode is completely consistent), because 3 The data storage of each Master is different. This will be verified in subsequent essays.
The above is the detailed content of Redis cluster building tutorial and problem solving. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1382
1382
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear redis data
Apr 10, 2025 pm 10:06 PM
How to clear Redis data: Use the FLUSHALL command to clear all key values. Use the FLUSHDB command to clear the key value of the currently selected database. Use SELECT to switch databases, and then use FLUSHDB to clear multiple databases. Use the DEL command to delete a specific key. Use the redis-cli tool to clear the data.
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to read redis queue
Apr 10, 2025 pm 10:12 PM
How to read redis queue
Apr 10, 2025 pm 10:12 PM
To read a queue from Redis, you need to get the queue name, read the elements using the LPOP command, and process the empty queue. The specific steps are as follows: Get the queue name: name it with the prefix of "queue:" such as "queue:my-queue". Use the LPOP command: Eject the element from the head of the queue and return its value, such as LPOP queue:my-queue. Processing empty queues: If the queue is empty, LPOP returns nil, and you can check whether the queue exists before reading the element.
 How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
How to use single threaded redis
Apr 10, 2025 pm 07:12 PM
Redis uses a single threaded architecture to provide high performance, simplicity, and consistency. It utilizes I/O multiplexing, event loops, non-blocking I/O, and shared memory to improve concurrency, but with limitations of concurrency limitations, single point of failure, and unsuitable for write-intensive workloads.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
Redis uses hash tables to store data and supports data structures such as strings, lists, hash tables, collections and ordered collections. Redis persists data through snapshots (RDB) and append write-only (AOF) mechanisms. Redis uses master-slave replication to improve data availability. Redis uses a single-threaded event loop to handle connections and commands to ensure data atomicity and consistency. Redis sets the expiration time for the key and uses the lazy delete mechanism to delete the expiration key.
