
Recently, we need to compare a series of data year-on-year, and we need to use numpy and pandas for calculation. The following article mainly introduces you to the relevant information about the use of Numpy and Pandas in the python learning tutorial. The article introduces it through sample code. Very detailed, friends in need can refer to it.
Preface
This article mainly introduces relevant information about the use of Numpy and Pandas in python, and shares it for your reference and study. Below Not much to say, let’s take a look at the detailed introduction.
what are they?
NumPy is an extension library for the Python language. It supports advanced and large-scale dimensional array and matrix operations, and also provides a large number of mathematical function libraries for array operations.
Pandas is a tool based on NumPy, which was created to solve data analysis tasks. Pandas incorporates a number of libraries and some standard data models to provide the tools needed to efficiently manipulate large data sets. Pandas provides a large number of functions and methods that allow us to process data quickly and easily.
List, Numpy and Pandas
The similarities between Numpy and List
:
can all be accessed using subscripts, for example a[0]
can be accessed by slicing, for example a[1:3]
You can use a for loop to traverse
The difference:
Each element in Numpy The types must be the same; multiple types of elements can be mixed in List
Numpy is more convenient to use and encapsulates many functions, such as mean, std, sum, min, max, etc.
Numpy can be a multi-dimensional array
Numpy is implemented in C and operates faster
The similarities between Pandas and Numpy
:
Accessing elements is the same, you can use subscripts or slices to access
You can use a For loop to traverse
There are many convenient functions, such as mean, std, sum, min, max, etc.
Vector operations can be performed
Implemented in C, faster
The difference: Pandas has some methods that Numpy does not have, such as the describe function . The main difference is: Numpy is like an enhanced version of List, while Pandas is like a collection of lists and dictionaries, and Pandas has indexes.
Numpy use
1. Basic operations
import numpy as np #创建Numpy p1 = np.array([1, 2, 3]) print p1 print p1.dtype
[1 2 3] int64
#求平均值 print p1.mean()
2.0
#求标准差 print p1.std()
0.816496580928
#求和、求最大值、求最小值 print p1.sum() print p1.max() print p1.min()
6 3 1
#求最大值所在位置 print p1.argmax()
2
2. Vector operations
p1 = np.array([1, 2, 3]) p2 = np.array([2, 5, 7])
#向量相加,各个元素相加 print p1 + p2
[ 3 7 10]
#向量乘以1个常数 print p1 * 2
[2 4 6]
#向量相减 print p1 - p2
[-1 -3 -4]
#向量相乘,各个元素之间做运算 print p1 * p2
[ 2 10 21]
#向量与一个常数比较 print p1 > 2
[False False True]
3. Index array
First, look at the picture below to understand
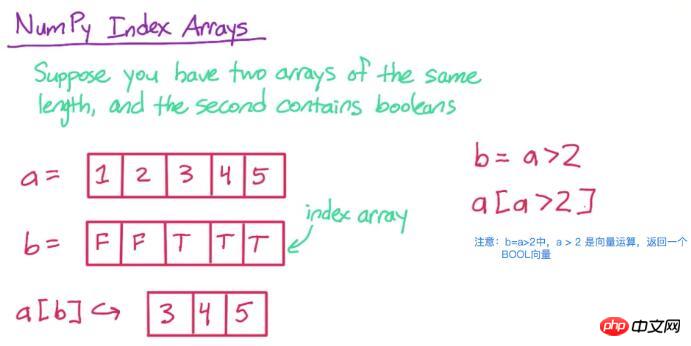
Then, let’s implement it in code
a = np.array([1, 2, 3, 4, 5]) print a
[1 2 3 4 5]
b = a > 2 print b
[False False True True True]
print a[b]
[3 4 5]
a[b], only the b position corresponding to a will be retained as Elements of True
4. In-situ and non-situ
Let’s first look at a set of operations:
a = np.array([1, 2, 3, 4]) b = a a += np.array([1, 1, 1, 1]) print b
[2 3 4 5]
a = np.array([1, 2, 3, 4]) b = a a = a + np.array([1, 1, 1, 1]) print b
[1 2 3 4]
As can be seen from the above results, += changes the original array, while + does not . This is because:
+=: it is calculated in place and does not create a new array, changing elements
5. Slices in Numpy and slices in List
l1 = [1, 2, 3, 5] l2 = l1[0:2] l2[0] = 5 print l2 print l1
[5, 2] [1, 2, 3, 5]
p1 = np.array([1, 2, 3, 5]) p2 = p1[0:2] p2[0] = 5 print p1 print p2
[5 2 3 5] [5 2]
6. Operation of two-dimensional array
p1 = np.array([[1, 2, 3], [7, 8, 9], [2, 4, 5]]) #获取其中一维数组 print p1[0]
[1 2 3]
#获取其中一个元素,注意它可以是p1[0, 1],也可以p1[0][1] print p1[0, 1] print p1[0][1]
2 2
#求和是求所有元素的和 print p1.sum()
41 [10 14 17]
但,当设置axis参数时,当设置为0时,是计算每一列的结果,然后返回一个一维数组;若是设置为1时,则是计算每一行的结果,然后返回一维数组。对于二维数组,Numpy中很多函数都可以设置axis参数。
#获取每一列的结果 print p1.sum(axis=0)
[10 14 17]
#获取每一行的结果 print p1.sum(axis=1)
[ 6 24 11]
#mean函数也可以设置axis print p1.mean(axis=0)
[ 3.33333333 4.66666667 5.66666667]
Pandas使用
Pandas有两种结构,分别是Series和DataFrame。其中Series拥有Numpy的所有功能,可以认为是简单的一维数组;而DataFrame是将多个Series按列合并而成的二维数据结构,每一列单独取出来是一个Series。
咱们主要梳理下Numpy没有的功能:
1、简单基本使用
import pandas as pd pd1 = pd.Series([1, 2, 3]) print pd1
0 1 1 2 2 3 dtype: int64
#也可以求和和标准偏差 print pd1.sum() print pd1.std()
6 1.0
2、索引
(1)Series中的索引
p1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) print p1
a 1 b 2 c 3 dtype: int64
print p1['a']
(2)DataFrame数组
p1 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print p1age name 0 18 Jack 1 19 Lucy 2 21 Coke
#获取name一列 print p1['name']
0 Jack 1 Lucy 2 Coke Name: name, dtype: object
#获取姓名的第一个 print p1['name'][0]
Jack
#使用p1[0]不能获取第一行,但是可以使用iloc print p1.iloc[0]
age 18 name Jack Name: 0, dtype: object
总结:
获取一列使用p1[‘name']这种索引
获取一行使用p1.iloc[0]
3、apply使用
apply可以操作Pandas里面的元素,当库里面没用对应的方法时,可以通过apply来进行封装
def func(value): return value * 3 pd1 = pd.Series([1, 2, 5])
print pd1.apply(func)
0 3 1 6 2 15 dtype: int64
同样可以在DataFrame上使用:
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke'],
'age': [18, 19, 21]
})
print pd2.apply(func)age name 0 54 JackJackJack 1 57 LucyLucyLucy 2 63 CokeCokeCoke
4、axis参数
Pandas设置axis时,与Numpy有点区别:
当设置axis为'columns'时,是计算每一行的值
当设置axis为'index'时,是计算每一列的值
pd2 = pd.DataFrame({
'weight': [120, 130, 150],
'age': [18, 19, 21]
})0 138 1 149 2 171 dtype: int64
#计算每一行的值 print pd2.sum(axis='columns')
0 138 1 149 2 171 dtype: int64
#计算每一列的值 print pd2.sum(axis='index')
age 58 weight 400 dtype: int64
5、分组
pd2 = pd.DataFrame({
'name': ['Jack', 'Lucy', 'Coke', 'Pol', 'Tude'],
'age': [18, 19, 21, 21, 19]
})
#以年龄分组
print pd2.groupby('age').groups{18: Int64Index([0], dtype='int64'), 19: Int64Index([1, 4], dtype='int64'), 21: Int64Index([2, 3], dtype='int64')}6、向量运算
需要注意的是,索引数组相加时,对应的索引相加
pd1 = pd.Series( [1, 2, 3], index = ['a', 'b', 'c'] ) pd2 = pd.Series( [1, 2, 3], index = ['a', 'c', 'd'] )
print pd1 + pd2
a 2.0 b NaN c 5.0 d NaN dtype: float64
出现了NAN值,如果我们期望NAN不出现,如何处理?使用add函数,并设置fill_value参数
print pd1.add(pd2, fill_value=0)
a 2.0 b 2.0 c 5.0 d 3.0 dtype: float64
同样,它可以应用在Pandas的dataFrame中,只是需要注意列与行都要对应起来。
总结
这一周学习了优达学城上分析基础的课程,使用的是Numpy与Pandas。对于Numpy,以前在Tensorflow中用过,但是很不明白,这次学习之后,才知道那么简单,算是有一定的收获。
The above is the detailed content of Introduction to the use of Numpy and Pandas in python. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



