

Introduction to Python3 basic crawler
Python3 basic crawler getting started experience
It’s my first time writing a blog, so I’m a little nervous, so don’t comment if you don’t like it.
If there are any shortcomings, I hope readers will point them out and I will correct them.
学习爬虫之前你需要了解(个人建议,铁头娃可以无视): - **少许网页制作知识,起码要明白什么标签...** - **相关语言基础知识。比如用java做爬虫起码会用Java语言,用python做爬虫起码要会用python语言...** - **一些网络相关知识。比如TCP/IP、cookie之类的知识,明白网页打开的原理。** - **国家法律。知道哪些能爬,哪些不能爬,别瞎爬。**
As the title states, all codes in this article use python3.6.X.
First, you need to install (pip3 install xxxx and it will be OK)
requests module
BeautifulSoup module (or lxml module)
These two libraries are very powerful. requests are used to send web page requests and open web pages, while beautifulsoup and lxml are used to parse content and extract what you want. BeautifulSoup favors regular expressions, lxml favors XPath. Because I am more accustomed to using the beautifulsoup library, this article mainly uses the beautifulsoup library without going into too much detail about lxml. (It is recommended to read the documentation before using it)
The main structure of the crawler:
Manager: Manage the addresses you want to crawl.
Downloader: Download web page information.
Filter: Filter out the content you need from the downloaded web page information.
Storage: Save the downloaded things where you want to save them. (Depending on the actual situation, it is optional.)
Basically all the web crawlers I have come into contact with can't escape this structure, ranging from sracpy to urllib. As long as you know this structure, you don’t need to memorize it. The advantage of knowing it is that you can at least know what you are writing when writing, and you will know where to debug when a bug occurs.
There is a lot of nonsense in the front... The text is as follows:
This article uses crawling https://baike.baidu.com/item/Python (the Baidu entry of python as an example):
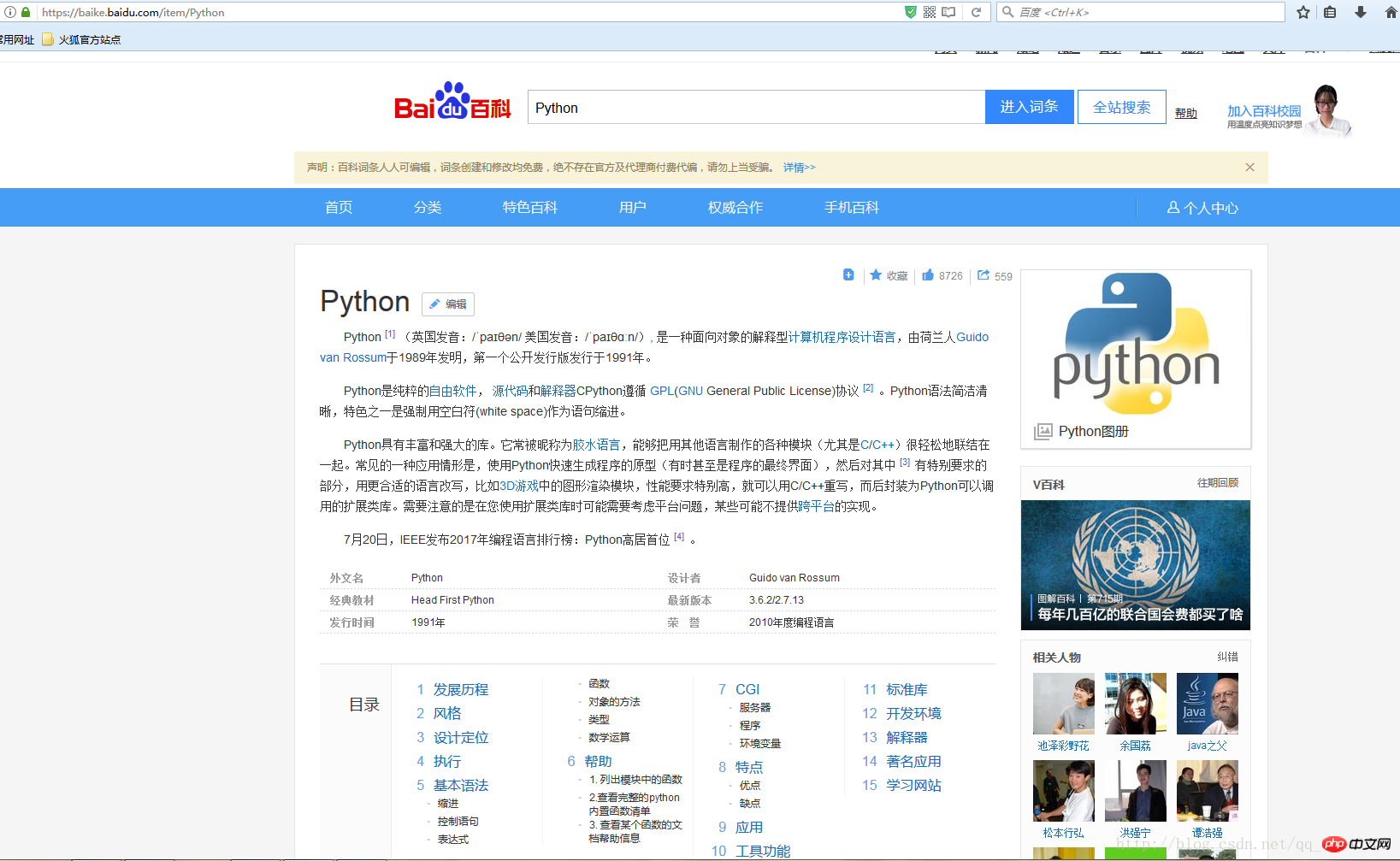
(Because taking screenshots is too troublesome...this will be the only picture in this article)
If you want to crawl the python entry content, first, you need to Know the URL you want to crawl:
url = 'https://baike.baidu.com/item/Python'
Because you only need to crawl this page, the manager is OK.
html = request.urlopen(url)
Call the urlopen() function, the downloader is OK
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary')Use the beautifulsoup function in the Beautifulsoup library together with the find_all function, the parser is OK
Let me say something here, the return of the find_all function Value is a list. So the output needs to be printed in a loop.
Since this example does not need to be saved, it can be printed directly, so:
for content in baike: print (content.get_text())
get_text() is used to extract the text in the label.
Sort out the above code:
import requestsfrom bs4 import BeautifulSoupfrom urllib import requestimport reif __name__ == '__main__':
url = 'https://baike.baidu.com/item/Python'
html = request.urlopen(url)
Soup = BeautifulSoup(html,"html.parser")
baike = Soup.find_all("p",class_='lemma-summary') for content in baike: print (content.get_text())The entry in Baidu Encyclopedia will appear.
Similar methods can also crawl some novels, pictures, headlines, etc., and are by no means limited to entries.
If you can write this program after closing this article, congratulations, you are getting started. Remember, never memorize the code.
The steps are omitted...The whole process is a bit rough...Sorry...it slipped ( ̄ー ̄)...
The above is the detailed content of Introduction to Python3 basic crawler. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1387
1387
 52
52

 Python ORM Performance Benchmark: Comparing Different ORM Frameworks
Mar 18, 2024 am 09:10 AM
Python ORM Performance Benchmark: Comparing Different ORM Frameworks
Mar 18, 2024 am 09:10 AM
Object-relational mapping (ORM) frameworks play a vital role in python development, they simplify data access and management by building a bridge between object and relational databases. In order to evaluate the performance of different ORM frameworks, this article will benchmark against the following popular frameworks: sqlAlchemyPeeweeDjangoORMPonyORMTortoiseORM Test Method The benchmarking uses a SQLite database containing 1 million records. The test performed the following operations on the database: Insert: Insert 10,000 new records into the table Read: Read all records in the table Update: Update a single field for all records in the table Delete: Delete all records in the table Each operation
 Introduction to Yii Framework: Understand the core concepts of Yii
Jun 21, 2023 am 09:39 AM
Introduction to Yii Framework: Understand the core concepts of Yii
Jun 21, 2023 am 09:39 AM
The Yii framework is a high-performance, highly scalable, and highly maintainable PHP development framework that is highly efficient and reliable when developing Web applications. The main advantage of the Yii framework is its unique features and development methods, while also integrating many practical tools and functions. The core concept of the Yii framework, the MVC pattern, Yii adopts the MVC (Model-View-Controller) pattern, which is a pattern that divides the application into three independent parts, namely the business logic processing model and the user interface presentation model.
 PHP Basics Tutorial: From Beginner to Master
Jun 18, 2023 am 09:43 AM
PHP Basics Tutorial: From Beginner to Master
Jun 18, 2023 am 09:43 AM
PHP is a widely used open source server-side scripting language that can handle all tasks in web development. PHP is widely used in web development, especially for its excellent performance in dynamic data processing, so it is loved and used by many developers. In this article, we will explain the basics of PHP step by step to help beginners from getting started to becoming proficient. 1. Basic syntax PHP is an interpreted language whose code is similar to HTML, CSS and JavaScript. Every PHP statement ends with a semicolon; Note
 Application of Python ORM in big data projects
Mar 18, 2024 am 09:19 AM
Application of Python ORM in big data projects
Mar 18, 2024 am 09:19 AM
Object-relational mapping (ORM) is a programming technology that allows developers to use object programming languages to manipulate databases without writing SQL queries directly. ORM tools in python (such as SQLAlchemy, Peewee, and DjangoORM) simplify database interaction for big data projects. Advantages Code Simplicity: ORM eliminates the need to write lengthy SQL queries, which improves code simplicity and readability. Data abstraction: ORM provides an abstraction layer that isolates application code from database implementation details, improving flexibility. Performance optimization: ORMs often use caching and batch operations to optimize database queries, thereby improving performance. Portability: ORM allows developers to
 Get an in-depth understanding of 7 commonly used Java design patterns
Dec 23, 2023 pm 01:01 PM
Get an in-depth understanding of 7 commonly used Java design patterns
Dec 23, 2023 pm 01:01 PM
Understanding Java Design Patterns: An introduction to 7 commonly used design patterns, specific code examples are required. Java design patterns are a universal solution to software design problems. It provides a set of widely accepted design ideas and codes of conduct. Design patterns help us better organize and plan the code structure, making the code more maintainable, readable and scalable. In this article, we will introduce 7 commonly used design patterns in Java and provide corresponding code examples. Singleton Patte
 Implement efficient data persistence using Python ORM
Mar 18, 2024 am 09:25 AM
Implement efficient data persistence using Python ORM
Mar 18, 2024 am 09:25 AM
Object-relational mapping (ORM) is a technology that allows building a bridge between object-oriented programming languages and relational databases. Using pythonORM can significantly simplify data persistence operations, thereby improving application development efficiency and maintainability. Advantages Using PythonORM has the following advantages: Reduce boilerplate code: ORM automatically generates sql queries, thereby avoiding writing a lot of boilerplate code. Simplify database interaction: ORM provides a unified interface for interacting with the database, simplifying data operations. Improve security: ORM uses parameterized queries, which can prevent security vulnerabilities such as SQL injection. Promote data consistency: ORM ensures synchronization between objects and databases and maintains data consistency. Choose ORM to have
 Add GUI charm to your projects with Python Tkinter
Mar 24, 2024 am 09:46 AM
Add GUI charm to your projects with Python Tkinter
Mar 24, 2024 am 09:46 AM
Tkinter is a powerful library for creating graphical user interfaces (GUIs) in python. It is known for its simplicity, cross-platform compatibility, and seamless integration with the Python ecosystem. By using Tkinter, you can add a user-friendly interface to your project, improving user experience and simplifying interaction with your application. Creating a Tkinter GUI application To create a GUI application using Tkinter, perform the following steps: Import the Tkinter library: importtkinterastk Create the Tkinter main window: root=tk.Tk() Configure the main window: Set the window title, size, position, etc. Add GUI elements: Using Tki
 From Novice to Master: A Crash Course in Java Git
Mar 27, 2024 pm 10:41 PM
From Novice to Master: A Crash Course in Java Git
Mar 27, 2024 pm 10:41 PM
Git is a distributed version control system that helps teams collaborate on software development. For Java developers, understanding Git is crucial because it provides a platform for managing code changes, tracking code history, and collaborating with others. Install Git for newbies (understand the basics): Install Git software and set environment variables. Create repository: Use gitinit to create a local repository. Add files: Use gitadd to add files to the staging area. Commit changes: Use gitcommit to commit changes in the staging area to the local repository. Intermediate (collaboration and version control) cloning a repository: Use gitclone to clone a local copy from a remote repository. Branching and Merging: Use branches to create isolated copies of your code
