

最近在学习python3,下面这篇文章主要给大家介绍了关于Python3实战爬虫之爬取京东图书图片的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面来一起看看吧。
前言
最近工作中遇到一个需求,需要将京东上图书的图片下载下来,假如我们想把京东商城图书类的图片类商品图片全部下载到本地,通过手工复制粘贴将是一项非常庞大的工程,此时,可以用Python网络爬虫实现,这类爬虫称为图片爬虫,接下来,我们将实现该爬虫。
实现分析
首先,打开要爬取的第一个网页,这个网页将作为要爬取的起始页面。我们打开京东,选择图书分类,由于图书所有种类的图书有很多,我们选择爬取所有编程语言的图书图片吧,网址为:https://list.jd.com/list.html?cat=1713,3287,3797&page=1&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main
如图:
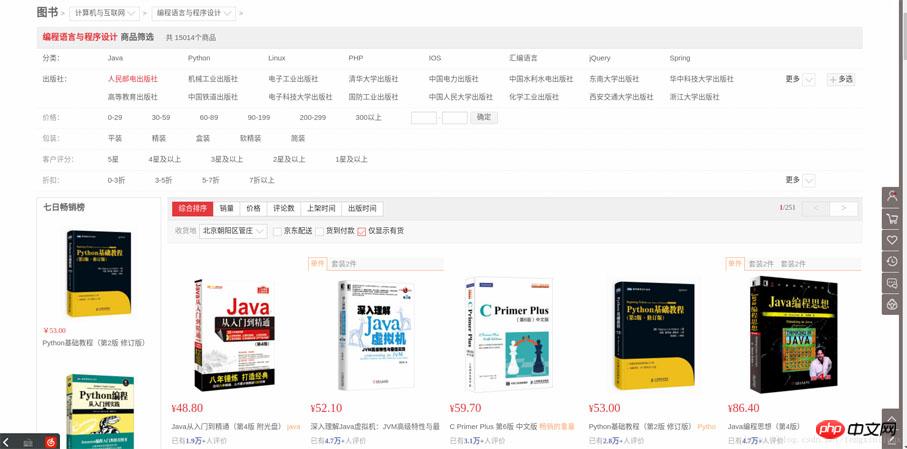
进去后,我们会发现总共有251页。
那么我们怎么才能自动爬取第一页以外的其他页面呢?
可以单击“下一页”,观察网址的变化。在单击了下一页之后,发现网址变成了https://list.jd.com/list.html?cat=1713,3287,3797&page=2&sort=sort_rank_asc&trans=1&JL=6_0_0#J_main。
我们可以发现,在这里要获取第几页是通过URL网址识别的,即通过GET方式请求的。在这个GET请求中,有多个字段,其中有一个字段为page,对应值为2,由此,我们可以得到该网址中的关键信息为:https://list.jd.com/list.html?cat=1713,3287,3797&page=2。接下来,我们根据推测,将page=2改成page=6,发现我们能够成功进入第6页。
由此,我们可以想到自动获取多个页面的方法:可以使用for循环实现,每次循环后,对应的网址中page字段加1,即自动切换到下一页。
在每页中,我们都要提取对应的图片,可以使用正则表达式匹配源码中图片的链接部分,然后通过urllib.request.urlretrieve()将对应链接的图片保存到本地。
但是这里有一个问题,该网页中的图片不仅包括列表中的商品图片,还包括旁边的一些无关图片,所以我们可以先进行一次信息过滤,第一次信息过滤将中间的商品列表部分数据留下,将其他部分的数据过滤掉。可以单击右键,然后查看网页的源代码,如图:
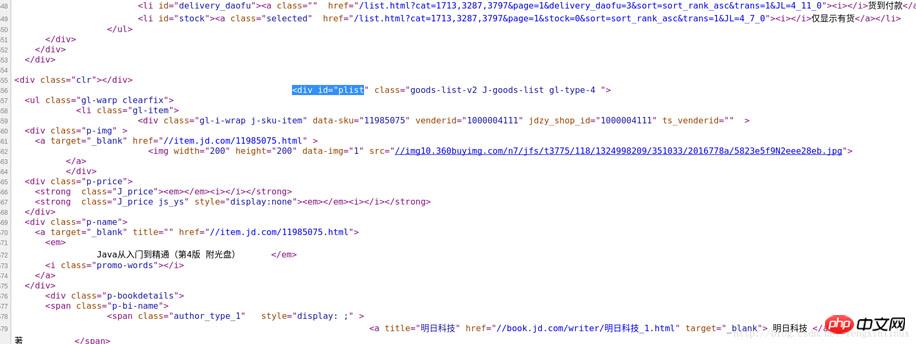
可以通过商品列表中的第一个商品名为“JAVA从入门到精通”快速定位到源码中的对应位置,然后观察其商品列表部分的特殊标识,可以看到,其上方有处“
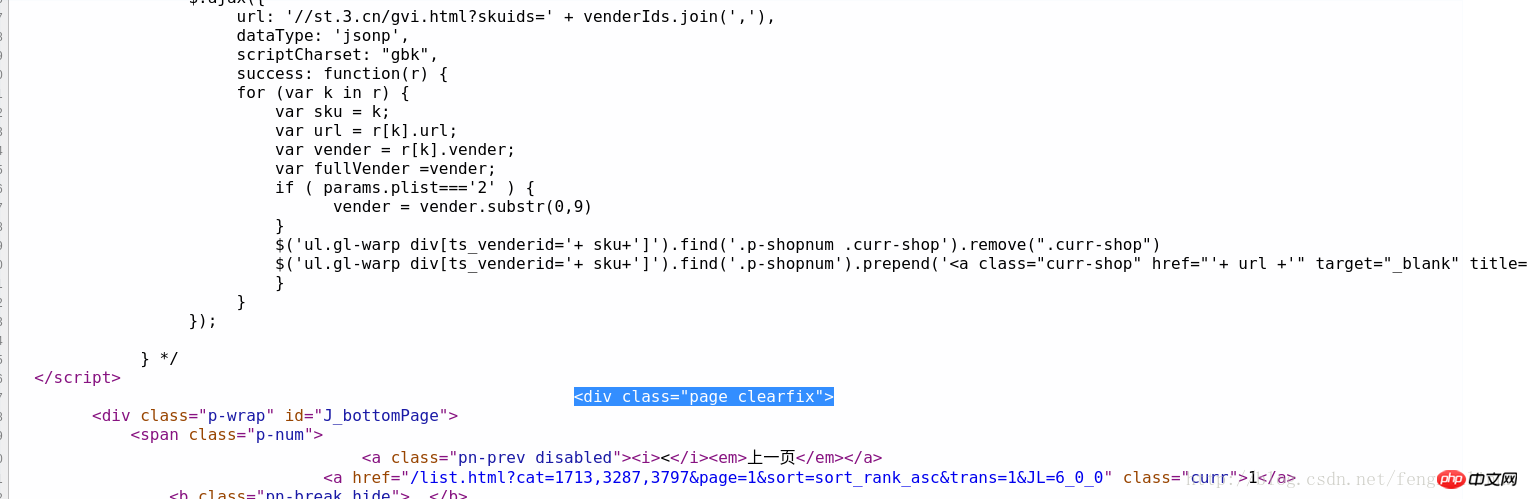
所以,如果要进行第一次过滤,我们的正则表达式可以构造为:
<p id="plist".+? <p class="page clearfix">
进行了第一次信息过滤后,留下来的图片链接就是我们想爬取的图片了,下一步需要在第一次过滤的基础上,再将图片链接信息过滤出来。
此时,需要观察网页中对应图片的源代码,我们观察到其中两张图片的对应源码:
图片1:
<img width="200" height="200" data-img="1" src="//img13.360buyimg.com/n7/jfs/t6130/167/771989293/235186/608d0264/592bf167Naf49f7f6.jpg">
图片2:
<img width="200" height="200" data-img="1" src="//img10.360buyimg.com/n7/g14/M03/0E/0D/rBEhV1Im1n8IAAAAAAcHltD_3_8AAC0FgC-1WoABweu831.jpg">
对比两张图片代码,发现其基本格式是一样的,只是图片的链接网址不一样,所以此时,我们根据该规律构造出提取图片链接的正则表达式:
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">
刚开始到这里,我以为就结束了,后来在爬取的过程中我发现每一页都少爬取了很多图片,再次查看源码发现,每页后面的几十张图片又是另一种格式:
<img width="200" height="200" data-img="1" src-img="//img10.360buyimg.com/n7/jfs/t3226/230/618950227/110172/7749a8bc/57bb23ebNfe011bfe.jpg">
所以,完整的正则表达式应该是这两种格式的或:
<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|
到这里,我们根据该正则表达式,就可以提取出一个页面中所有想要爬取的图片链接。
所以,根据上面的分析,我们可以得到该爬虫的编写思路与过程,具体如下:
建立一个爬取图片的自定义函数,该函数负责爬取一个页面下的我们想爬取的图片,爬取过程为:首先通过urllib.request.utlopen(url).read()读取对应网页的全部源代码,然后根据上面的第一个正则表达式进行第一次信息过滤,过滤完成之后,在第一次过滤结果的基础上,根据上面的第二个正则表达式进行第二次信息过滤,提取出该网页上所有的目标图片的链接,并将这些链接地址存储的一个列表中,随后遍历该列表,分别将对应链接通过urllib.request.urlretrieve(imageurl,filename=imagename)存储到本地,为了避免程序中途异常崩溃,我们可以建立异常处理。
通过for循环将该分类下的所有网页都爬取一遍,链接可以构造为url='https://list.jd.com/list.html?cat=1713,3287,3797&page=' + str(i)
完整的代码如下:
#!/usr/bin/env python3 # -*- coding: utf-8 -*- import re import urllib.request import urllib.error import urllib.parse sum = 0 def craw(url,page): html1=urllib.request.urlopen(url).read() html1=str(html1) pat1=r'<p id="plist".+? <p class="page clearfix">' result1=re.compile(pat1).findall(html1) result1=result1[0] pat2=r'<img width="200" height="200" data-img="1" src="//(.+?\.jpg)">|' imagelist=re.compile(pat2).findall(result1) x=1 global sum for imageurl in imagelist: imagename='./books/'+str(page)+':'+str(x)+'.jpg' if imageurl[0]!='': imageurl='http://'+imageurl[0] else: imageurl='http://'+imageurl[1] print('开始爬取第%d页第%d张图片'%(page,x)) try: urllib.request.urlretrieve(imageurl,filename=imagename) except urllib.error.URLError as e: if hasattr(e,'code') or hasattr(e,'reason'): x+=1 print('成功保存第%d页第%d张图片'%(page,x)) x+=1 sum+=1 for i in range(1,251): url='https://list.jd.com/list.html?cat=1713,3287,3797&page='+str(i) craw(url,i) print('爬取图片结束,成功保存%d张图'%sum)
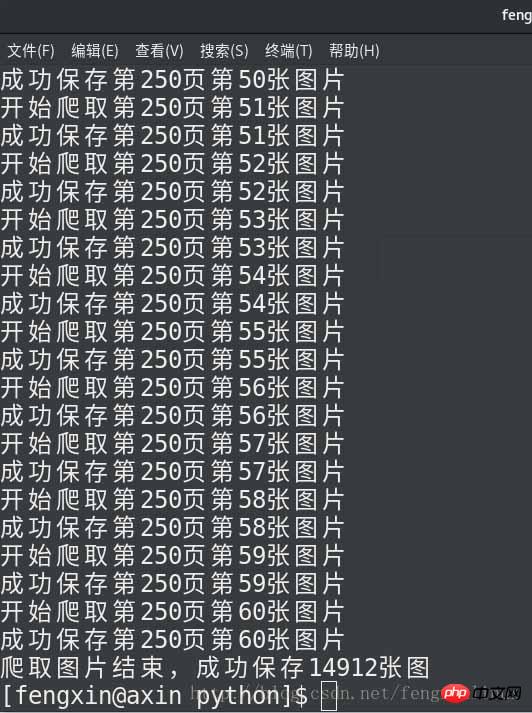
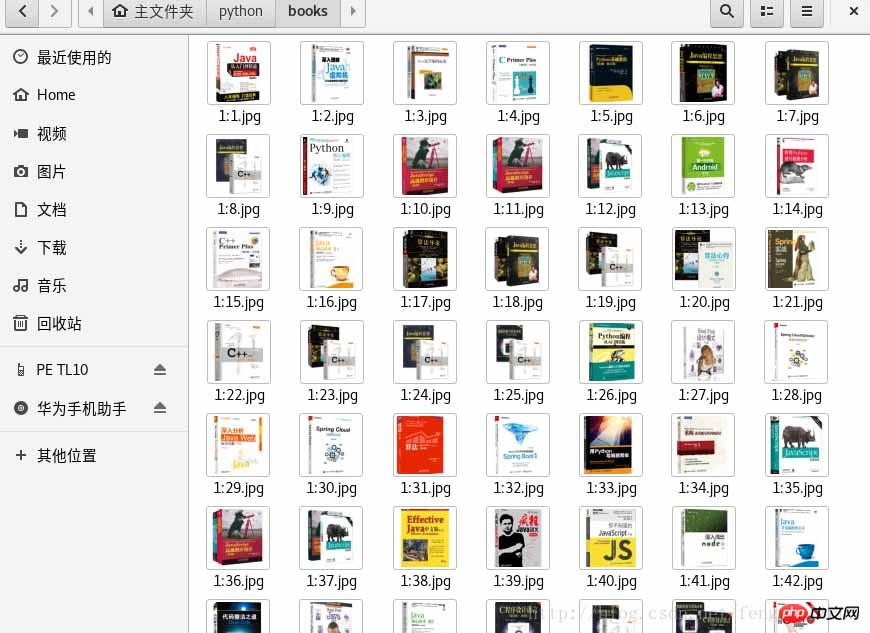
运行结果如下:
总结
The above is the detailed content of Detailed graphic and text explanation of Python3 practical crawler for crawling Jingdong books. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



