

What is the fundamental cause of garbled web pages?
先看段代码:
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>网页编码</title> </head> <body> </body> </html>
HTML代码中的 指定了网页的编码为utf-8。
网页编码涉及的知识点比较多,总的说来它也是一个历史遗留问题。
第一台计算机(ENIAC)于1946年2月诞生于美国,当时美国只考虑自己使用,并在计算机诞生后的几年里制定了一套ASCII码标准(American Standard Code for Information Interchange,美国信息交换标准代码),它是基于拉丁字母的一套电脑编码系统,主要用于显示现代英语和其他西欧语言。
ASCII码使用8位二进制数组合来表示256种可能的字符(2的8次方=256),包含了大小写字母,数字0到9,标点符号,以及在美式英语中使用的特殊控制字符。一个字符占1个字节。ASCII码表部分编码如下:
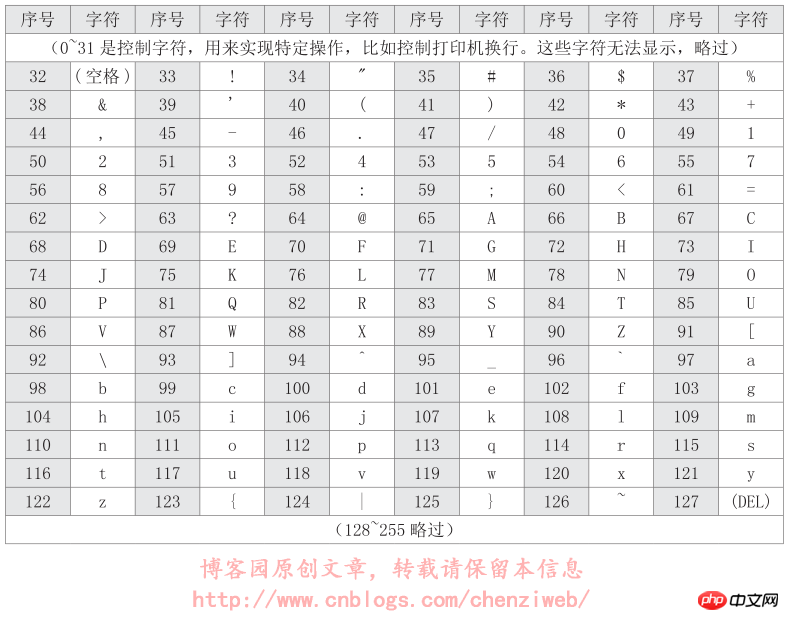
HTML的转义符(字符实体),比如符号“<”的转义符为“<”或“<”,其中的数字编号“60”即是ASCII码表的第60序号。类似的,大写字母“K”也可以转义为“K”。
我们使用转义符做个试验:
美国制定ASCII码的意思是:ASCII码可以满足在计算机领域所有字符和表示上的需要。不过这只是美国自己的意思,毕竟所有的英文单词都可以拆分来自26个英文字母,ASCII码表能表达256个字符,确实足够美国使用。
后来世界各地也都开始使用计算机,很多国家的语言文字并不是英文,这些国家的文字都没被包含在ASCII码表里。以我们中国为例,汉字近10万个,根本无法排进ASCII码表。于是我们国家对ASCII码表进行拓展并形成自己的的一套标准,在标准中一个汉字占2个字节,新的码表可以表达65536个汉字。但一开始并没有将码表全部填充使用完,只收录了常用的6000多个汉字、英文及其它符号,这套标准称为GB2312(信息交换用汉字编码字符集,GB是“国家标准”的简化词“国标”的拼音首字母缩写,2312是国标序号)。后来又制定了一套收录更多汉字的标准(收录的汉字有2万多个),称为GBK(汉字编码扩展规范,K是“扩”的拼音首字母)。
在GB2312或GBK里,许多标点符号都使用2个字节进行了重新编码,这类占2个字节的标点符号称为“全角”字符(“全角”也称“全形”或“全宽”或“全码”),原来ASCII码表中占1个字节的标点符号则称为“半角”字符(“半角”也称“半形”或“半宽”或“半码”)。全角的逗号、括号、句号等与半角是不一样的:
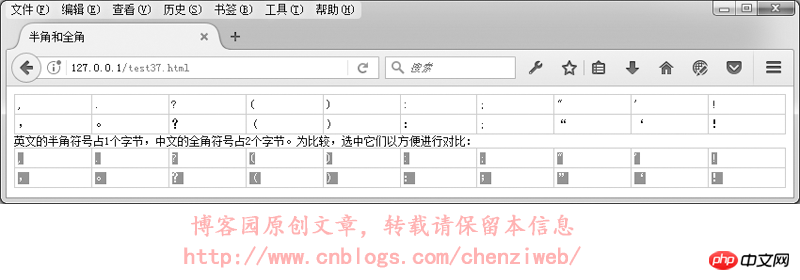
Under the Chinese input method, the default punctuation marks are full-width characters; under the English input method, the punctuation marks are half-width characters.
We continue to tell the story: As more and more countries use computers, more and more countries are formulating their own computer coding standards. The result is that the computer coding in various countries does not support or understand each other. For example, if you want to display Chinese characters on a computer in the United States, you must install a Chinese character system. Otherwise, Chinese files will be garbled when opened on a computer with an American system.
In this way, during this period, an international organization called ISO (International Organization for Standardization, International Organization for Standardization) was born to set out to solve the coding problems of various countries. ISO has uniformly produced a coding scheme called UNICODE (Universal Multiple-Octet Coded Character Set, also referred to as UCS), which is used to record all words and symbols on the earth. UNICODE characters are divided into 17 groups, and each group is called a plane. Each plane has 65536 code points, and a total of 1114112 characters can be recorded (1.11 million characters, a large enough capacity). UNICODE encoding unified one character occupies 2 bytes.
But UNICODE could not be promoted for a long time. Until the emergence of the Internet, the transmission and exchange of data made it urgent to unify coding between countries. However, early hard disks and network traffic were very expensive. Each character in UNICODE encoding occupied 2 bytes of capacity. Therefore, in order to save the hard disk space occupied when storing files, and also to save the time required for characters to be transmitted over the network, Occupying network traffic, many transmission-oriented standards based on UNICODE have been formulated. These transmission-oriented standards are collectively called UTF (UCS Transfer Format). UNICODE encoding and UTF encoding do not have a direct one-to-one correspondence, but must be converted through some algorithms and rules. The relationship between UNICODE and UTF is: UNICODE is the foundation, foundation, and purpose, while UTF is just a means, method, and process to realize UNICODE.
Common UTF formats are: UTF-8, UTF-16, UTF-32. Among them, UTF-8 is the most widely used UNICODE implementation on the Internet. It is specially designed for transmission. Precisely because UTF-8 is a transmission implementation method designed based on UNICODE, it can make encoding without borders, and text from any country can be displayed normally in a computer browser in any country. One of the biggest features of UTF-8 is that it is a variable-length encoding method. It can use 1 to 4 bytes to represent a symbol. The byte length changes according to different symbols. When it can use 1 byte to represent a When a symbol is represented, 1 byte is used to represent it. If a symbol requires 2 bytes to be represented, 2 bytes are used to represent it, and so on, up to 4 bytes, thus saving hard disk storage space and network traffic.
So if we use GB2312 or GBK encoding when developing our website, and computers in other countries do not support Chinese character encoding, what you will see will be garbled codes, which will be displayed like this: 口口口口口. If the website uses UTF-8 encoding, the content will be automatically converted to UNICODE encoding when a computer in any country opens the website, and since all modern computers support UNICODE encoding, any text can be displayed normally!
However, many domestic websites still use GB2312 or GBK encoding. Such websites usually only provide services to domestic users and will not have display problems for domestic users. However, if faced by viewers from other countries, such websites will largely appear garbled when opened.
For the sake of high compatibility and internationalization of the website, it is recommended that the website use UTF-8 encoding instead of GB2312 or GBK encoding.
The tags for specifying web pages as UTF-8, GB2312 and GBK are:
<meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <meta http-equiv="Content-Type" content="text/html; charset=gb2312"> <meta http-equiv="Content-Type" content="text/html; charset=gbk">
那么有一个问题出现了:网页各种编码的区别,仅仅是在于这一行meta标签的设置差别吗?仅仅是“utf-8”这5个字符换成“gb2312”这6个字符之类的这种“小差别”吗?
不是的,差别不仅仅是这几个字符的差别。当网页指定meta标签中的编码为utf-8后,DreamWeaver在保存网页时会自动将网页文件保存为utf-8的编码格式(二进制码使用utf-8的编码格式),meta标签中的utf-8编码是为了告诉浏览器:这个网页用的是utf-8编码,请在显示时使用utf-8编码的格式解析并呈现出来;而如果meta标签中指定编码为gb2312,DreamWeaver在保存网页时会自动将网页文件保存为gb2312的编码格式(二进制码使用gb2312的编码格式),同样,meta标签中的gb2312编码只是为了告诉浏览器:这个网页用的是gb2312编码,请在显示时使用gb2312编码的格式解析并呈现出来。我们做个试验,将一个文本文件分别保存为utf-8格式(打开记事本新建文本文件,输入内容后,选择菜单:文件→另存为,编码选择为UTF-8)和gb2312格式(另存时编码选择为ANSI,ANSI代表当前操作系统的默认编码,在简体中文Windows操作系统中,ANSI 编码代表 GBK 编码;在繁体中文Windows操作系统中,ANSI编码代表Big5;在日文Windows操作系统中,ANSI 编码代表 Shift_JIS 编码,类推),对比其二进制数据。这里使用UltraEdit-32文件编辑器对文本文件进行16进制查看,即使用16进制查看文件的二进制数据: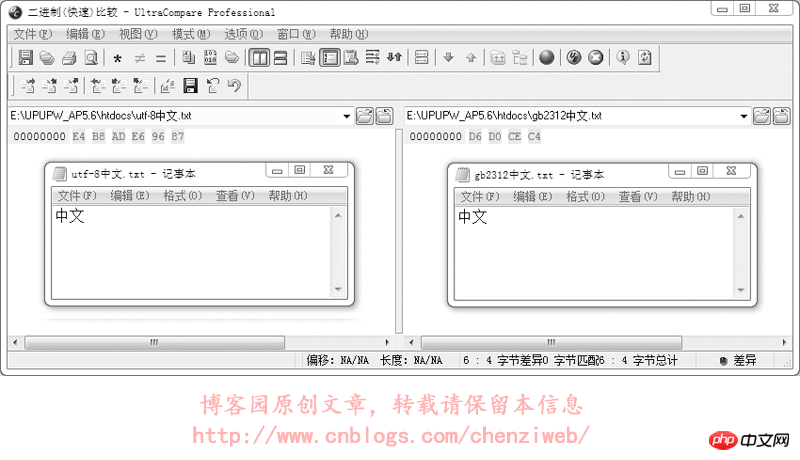
从上图中可以看到,使用utf-8编码和使用gb2312编码保存的文件,其二进制数据是不一样的,即这两个文件的二进制数据内容是不一样的。记事本软件在打开文本文件时,会尝试识别文件的编码并进行解析和显示,即文字保存在记事本里,无论保存成utf-8编码还是gb2312编码,通常情况下记事本都能正常识别和显示,不需要在文件里额外记录数据以告知记事本该文件是什么编码。但很多软件却无法做到智能识别文本文件的编码,这就要求文本文件在保存时,必须附带一些特殊的内容(额外的数据)以告知该文件是什么编码。UNICODE规范中有一个BOM(Byte Order Mark)的概念,就是字节序标记,在文件头部开始位置写入三个字节(EF BB BF)以告知该文件是utf-8编码格式。但这个BOM又带出了新的问题:不是所有的软件或处理程序都支持BOM,即不是所有的软件或处理程序都能识别文件开头的(EF BB BF)这三个字节。当不支持识别时,这三个字节又会被当成文件的实际数据内容。早期的火狐不支持对BOM的识别,当遇到BOM时会对这三个字节显示出特殊的乱码符号;而到目前为止,PHP处理程序仍然不支持BOM,即当一个PHP文件保存为utf-8时,如果附带了BOM,那么PHP处理程序会将BOM解析为PHP文件的实际数据内容而导致出错!在DreamWeaver中,选择软件头部菜单:修改→页面属性(也可以直接按快捷键ctrl+j),在弹出的页面属性面板中点选“标题/编码”,即可看到可供选择的编码。通常在改变网页的编码时,使用这种方式改变。如下图: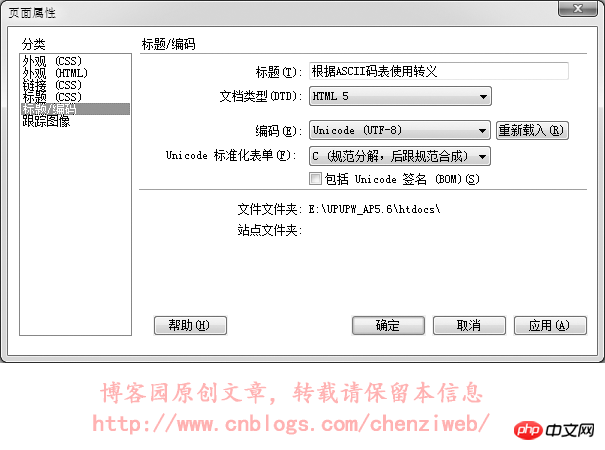
所以:当我们在meta标签中设置为utf-8编码格式时,网页文件就必须要存储为utf-8格式,这样浏览器才能正常显示网页而不是显示乱码。如果在meta标签中设置utf-8编码格式,网页文件却保存为gbk或其它格式,那么在打开网页时浏览器会接到网页meta标签中格式的通知:使用utf-8编码格式来解析和显示网页,而网页的二进制码(数据内容)却为gbk编码或其它格式,显示出来就会是乱码!这好比相亲时,红娘手里的资料有误,错误的告知男方:女方讲英语(meta标签中设置为utf-8编码)。结果女方却不懂英语(文件却不是utf-8编码)。男方开口一句“Hello”就让女方不知所谓了(乱码)。
我们来实验一下,网页指定meta标签中的编码为utf-8,文件却保存为gbk格式:我们先用DreamWeaver编辑一个utf-8格式的网页并保存,然后再用记事本打开该网页,另存为,编码选择为ANSI。
<!DOCTYPE HTML> <html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8"> <title>中文</title> </head> <body> 本文件使用dreamweaver保存后,再使用记事本打开,并另存为ANSI编码。 </body> </html>
在浏览器中的执行结果如下:
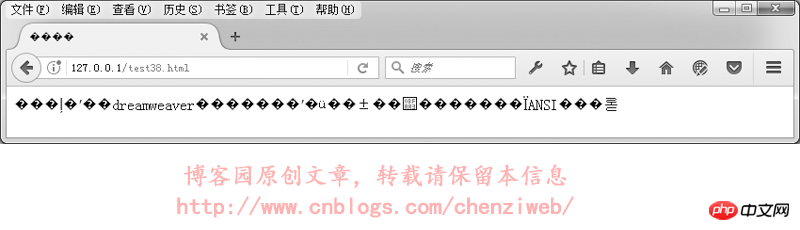
In summary: When developing web pages, try to use utf-8 encoding format, and when saving files, save them as utf-8 encoding. (When dreamweaver saves web page files, it will automatically save them in the correct encoding according to the encoding specified by Corresponding encoding, but if you use other website code editors, such as Notepad, Editplus, etc., you need to pay attention to selecting the correct encoding when saving the file).
The above is the detailed content of What is the fundamental cause of garbled web pages?. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 What is the reason why screencasting fails? 'A must-read for newbies: How to solve the problem of unsuccessful wireless screencasting connection'
Feb 07, 2024 pm 05:03 PM
What is the reason why screencasting fails? 'A must-read for newbies: How to solve the problem of unsuccessful wireless screencasting connection'
Feb 07, 2024 pm 05:03 PM
Why does wireless screencasting fail to connect? Some friends have reported that the connection fails when using wireless screen mirroring. What is going on? What should I do if the wireless screen mirroring connection fails? Please confirm whether your computer, TV and mobile phone are connected to the same WiFi network. Screen mirroring software requires devices to be on the same network to work properly, and Quick Screen Mirroring is no exception. Therefore, please quickly check your network settings. It is important to determine whether the screen mirroring function is supported. Smart TVs and mobile phones usually support DLNA or AirPlay functionality. If the screencast function is not supported, screencasting will not be possible. Confirm whether the device is connected correctly: There may be multiple devices under the same WiFi. Make sure you are connecting to the device you want to share the screen with. 4. Ensure that the network
 What causes WPS Office to be unable to start a print job?
Mar 20, 2024 am 09:52 AM
What causes WPS Office to be unable to start a print job?
Mar 20, 2024 am 09:52 AM
When connecting a printer to a local area network and starting a print job, some minor problems may occur. For example, the problem "wpsoffice cannot start the print job..." occasionally occurs, resulting in the inability to print out files, etc., delaying our work and study, and causing a bad impact. , let me tell you how to solve the problem that wpsoffice cannot start the print job? Of course, you can upgrade the software or upgrade the driver to solve the problem, but this will take you a long time. Below I will give you a solution that can be solved in minutes. First of all, I noticed that wpsoffice cannot start the print job, resulting in the inability to print. To solve this problem, we need to investigate one by one. Also, make sure the printer is powered on and connected. Generally, abnormal connection will cause
 How to solve Chinese garbled characters in Linux
Feb 21, 2024 am 10:48 AM
How to solve Chinese garbled characters in Linux
Feb 21, 2024 am 10:48 AM
The Linux Chinese garbled problem is a common problem when using Chinese character sets and encodings. Garbled characters may be caused by incorrect file encoding settings, system locale not being installed or set, and terminal display configuration errors, etc. This article will introduce several common workarounds and provide specific code examples. 1. Check the file encoding setting. Use the file command to view the file encoding. Use the file command in the terminal to view the encoding of the file: file-ifilename. If there is "charset" in the output
 Comprehensive Guide to PHP 500 Errors: Causes, Diagnosis and Fixes
Mar 22, 2024 pm 12:45 PM
Comprehensive Guide to PHP 500 Errors: Causes, Diagnosis and Fixes
Mar 22, 2024 pm 12:45 PM
A Comprehensive Guide to PHP 500 Errors: Causes, Diagnosis, and Fixes During PHP development, we often encounter errors with HTTP status code 500. This error is usually called "500InternalServerError", which means that some unknown errors occurred while processing the request on the server side. In this article, we will explore the common causes of PHP500 errors, how to diagnose them, and how to fix them, and provide specific code examples for reference. Common causes of 1.500 errors 1.
 How to solve the problem of Chinese garbled characters in Windows 10
Jan 16, 2024 pm 02:21 PM
How to solve the problem of Chinese garbled characters in Windows 10
Jan 16, 2024 pm 02:21 PM
In the Windows 10 system, garbled characters are common. The reason behind this is often that the operating system does not provide default support for some character sets, or there is an error in the set character set options. In order to prescribe the right medicine, we will analyze the actual operating procedures in detail below. How to solve Windows 10 garbled code 1. Open settings and find "Time and Language" 2. Then find "Language" 3. Find "Manage Language Settings" 4. Click "Change System Regional Settings" here 5. Check the box as shown and click Just make sure.
 Why is Apple mobile phone charging so slow?
Mar 08, 2024 pm 06:28 PM
Why is Apple mobile phone charging so slow?
Mar 08, 2024 pm 06:28 PM
Some users may encounter slow charging speeds when using Apple phones. There are many reasons for this problem. It may be caused by low power of the charging device, device failure, problems with the USB interface of the mobile phone, or even battery aging and other factors. Why does Apple mobile phone charge very slowly? Answer: charging equipment problem, mobile phone hardware problem, mobile phone system problem. 1. When users use charging equipment with relatively low power, the charging speed of the mobile phone will be very slow. 2. Using third-party inferior chargers or charging cables will also cause slow charging. 3. It is recommended that users use the official original charger, or replace it with a regular certified high-power charger. 4. There is a problem with the user’s mobile phone hardware. For example, the USB interface of the mobile phone cannot be contacted.
 Revealing the root causes of win11 blue screen
Jan 04, 2024 pm 05:32 PM
Revealing the root causes of win11 blue screen
Jan 04, 2024 pm 05:32 PM
I believe many friends have encountered the problem of system blue screen, but I don’t know what is the cause of win11 blue screen. In fact, there are many reasons for system blue screen, and we can investigate and solve them in order. Reasons for win11 blue screen: 1. Insufficient memory 1. It may occur when running too many software or the game consumes too much memory. 2. Especially now there is a memory overflow bug in win11, so it is very likely to be encountered. 3. At this time, you can try to set up virtual memory to solve the problem, but the best way is to upgrade the memory module. 2. CPU overclocking and overheating 1. The causes of CPU problems are actually similar to those of memory. 2. It usually occurs when using post-processing, modeling and other software, or when playing large-scale games. 3. If the CPU consumption is too high, a blue screen will appear.
 Editing method to solve the problem of garbled characters when opening dll files
Jan 06, 2024 pm 07:53 PM
Editing method to solve the problem of garbled characters when opening dll files
Jan 06, 2024 pm 07:53 PM
When many users use computers, they will find that there are many files with the suffix dll, but many users do not know how to open such files. For those who want to know, please take a look at the following details. Tutorial~How to open and edit dll files: 1. Download a software called "exescope" and download and install it. 2. Then right-click the dll file and select "Edit resources with exescope". 3. Then click "OK" in the pop-up error prompt box. 4. Then on the right panel, click the "+" sign in front of each group to view the content it contains. 5. Click on the dll file you want to view, then click "File" and select "Export". 6. Then you can
