

Example analysis of Java parsing DICOM diagram to obtain hexadecimal data

DICOM stands for Medical Digital Imaging and Communication. It is the international standard for medical images and related information (ISO 12052). The following article mainly introduces you to the relevant information on how to obtain hexadecimal data by using Java to parse DICOM diagrams. The article introduces it in detail through sample code. Friends in need can refer to it.
Preface
In a recent project, JAVA was needed to parse DICOM images. DICOM is widely used in radiological medicine, cardiovascular imaging and Radiation diagnosis and treatment diagnostic equipment (X-ray, CT, MRI, ultrasound, etc.), and has been increasingly widely used in other medical fields such as ophthalmology and dentistry. Some problems encountered during implementation will be recorded below.
First find a *.dcm file. Open it with the editor and you will see the following interface. The editor I use is UltraEdit
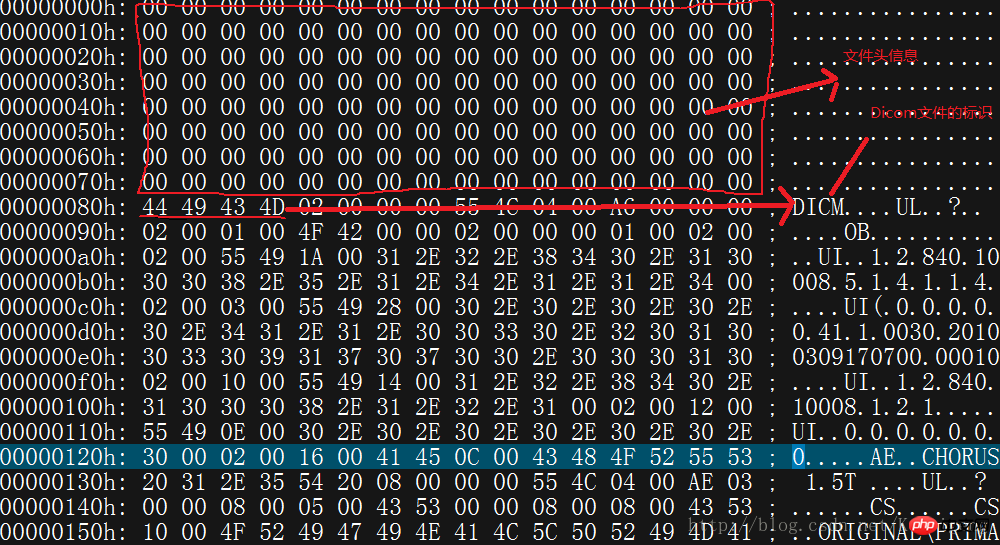
The red letters mark the bytecode marks. The first 8 lines of code are the header information of the file and are generally useless. The four hexadecimal numbers "44,49,43,4D" starting on the ninth line are important. The ASCll code explanation is DICM. Indicates that this is a DICOM file. If these four hexadecimal numbers are lost or damaged, the DICOM image cannot be opened.
The following uses java to read these hexadecimal numbers
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
|
(because the file is too There are 130,000 bytes, so for the sake of demonstration, we only loop 10,000 times. Read the first 10,000 bytes)
The above code is very common, which is to read the file stream into a byte array. Use Integer.toHexString(b[i]) to convert it to hexadecimal.
A problem occurred.
After running:
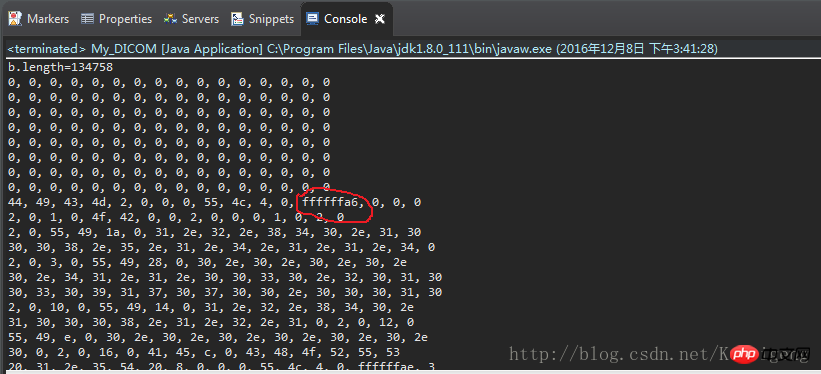
#Compare the hexadecimal list opened by the editor above. The red letter should be a6, but it is not ffffffa6 is printed.
Find the problem
The pen calculation error byte position is 140. Printsystem.out.pritln(b[140]);The result is -90. Why -90?.
Pushing backwards to a6 and converting it into decimal should be 166.
Okay, I found the problem. 166+90=256 This is no coincidence. One problem overlooked is that the maximum value of the byte array is only 127. Therefore, when the array read in the file is greater than 127, an error will occur when reading the byte array.
Solution
##
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
|
Summary
The above is the detailed content of Example analysis of Java parsing DICOM diagram to obtain hexadecimal data. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!
Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Perfect Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Perfect Number in Java. Here we discuss the Definition, How to check Perfect number in Java?, examples with code implementation.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Guide to Weka in Java. Here we discuss the Introduction, how to use weka java, the type of platform, and advantages with examples.
 Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Smith Number in Java
Aug 30, 2024 pm 04:28 PM
Guide to Smith Number in Java. Here we discuss the Definition, How to check smith number in Java? example with code implementation.
 Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
Java Spring Interview Questions
Aug 30, 2024 pm 04:29 PM
In this article, we have kept the most asked Java Spring Interview Questions with their detailed answers. So that you can crack the interview.
 Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Break or return from Java 8 stream forEach?
Feb 07, 2025 pm 12:09 PM
Java 8 introduces the Stream API, providing a powerful and expressive way to process data collections. However, a common question when using Stream is: How to break or return from a forEach operation? Traditional loops allow for early interruption or return, but Stream's forEach method does not directly support this method. This article will explain the reasons and explore alternative methods for implementing premature termination in Stream processing systems. Further reading: Java Stream API improvements Understand Stream forEach The forEach method is a terminal operation that performs one operation on each element in the Stream. Its design intention is
 TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
TimeStamp to Date in Java
Aug 30, 2024 pm 04:28 PM
Guide to TimeStamp to Date in Java. Here we also discuss the introduction and how to convert timestamp to date in java along with examples.
 Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Java Program to Find the Volume of Capsule
Feb 07, 2025 am 11:37 AM
Capsules are three-dimensional geometric figures, composed of a cylinder and a hemisphere at both ends. The volume of the capsule can be calculated by adding the volume of the cylinder and the volume of the hemisphere at both ends. This tutorial will discuss how to calculate the volume of a given capsule in Java using different methods. Capsule volume formula The formula for capsule volume is as follows: Capsule volume = Cylindrical volume Volume Two hemisphere volume in, r: The radius of the hemisphere. h: The height of the cylinder (excluding the hemisphere). Example 1 enter Radius = 5 units Height = 10 units Output Volume = 1570.8 cubic units explain Calculate volume using formula: Volume = π × r2 × h (4
 Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Create the Future: Java Programming for Absolute Beginners
Oct 13, 2024 pm 01:32 PM
Java is a popular programming language that can be learned by both beginners and experienced developers. This tutorial starts with basic concepts and progresses through advanced topics. After installing the Java Development Kit, you can practice programming by creating a simple "Hello, World!" program. After you understand the code, use the command prompt to compile and run the program, and "Hello, World!" will be output on the console. Learning Java starts your programming journey, and as your mastery deepens, you can create more complex applications.
