
 Database
Mysql Tutorial
Comparative analysis of high availability solutions for Oracle and MySQL
Database
Mysql Tutorial
Comparative analysis of high availability solutions for Oracle and MySQL
Comparative analysis of high availability solutions for Oracle and MySQL

Regarding the high availability solutions of Oracle and MySQL, I have always wanted to summarize them, so I will briefly talk about them in several series. Through this comparison, you will have a basic understanding of the detailed differences in the design of the two database architectures. Oracle has a very mature solution. Judging from my ppt on OOW, it is MAA’s plan. This year is the 16th anniversary of this plan. This article mainly introduces the comparative analysis of the high availability solutions of Oracle and MySQL. It is very good and has reference value. Friends in need can refer to it.

Due to the open source nature of MySQL, more solutions have been launched in the community. In my personal opinion, InnoDB Cluster will be the standard high-availability solution for MySQL in the future.
At present, MGR is good, and there are also MySQL Cluster solutions, PXC, Galera and other solutions. Personally, I still prefer MHA.
So this article will be divided into several parts to interpret. Let’s first make a basic comparison between RAC and MHA.
Oracle’s solutions supported Alibaba’s core business needs during its rapid development period. It's probably this kind of architecture system, which looks very huge. The RAC inside is considered an aristocrat, using expensive commercial storage, extremely high network bandwidth requirements, and a large number of front-end small computer services and expensive license fees. A very typical IOE classic architecture.

If you want to consider off-site disaster recovery, then the resource configuration must be doubled and the budget must be doubled.
MySQL's architecture solution is relatively more civilian. An ordinary PC is enough, but the order of magnitude is higher. When doing business splitting, horizontal splitting can horizontally expand a lot of nodes. Many large Internet companies The scale of MySQL clusters is hundreds or hundreds, and thousands are not uncommon. With so many service resources, there is still a probability of failure. Ensuring sustainable access to business services is the key to technical solutions. If you follow the MHA architecture, the MHA Manager node is basically responsible for the status of the entire cluster. It is like a neighborhood committee aunt who knows all the big and small things about the residents.

Of course the above statement is too general, let’s start with some details. For example, let’s talk about the Internet first.
Oracle has very strict requirements for the network. Generally, it requires 2 physical network cards. Each server requires at least 3 IP, Public IP, private IP, VIP. In addition to shared storage, at least 2 are required. calculate node.
Private IP is for mutual trust between nodes. Public IP and VIP are in the same network segment. Simply put, VIP is external and is the drift IP of the network where the public IP is located. In 10g, it is done through VIP For load balancing, scan-IP has been introduced since 11g, and the original VIP is still retained, so the network configuration requirements in Oracle are still very high. Regardless of shared storage, the core of the construction is network configuration, and the network is general.
scan-IP can continue to be expanded, supporting up to 3 scan-ips, as shown in the figure below

Of course, the network level is not limited to these, this aspect The highlight of Oracle is that it is very professional. We need to understand TAF. In my book "Oracle DBA Work Notes", I wrote:
TAF (Transparent Application Failover) is an application-transparent failover in Oracle. In a RAC environment Especially widely used in. Load Balance in RAC has indeed been greatly improved. From the Load Balance of multiple VIP addresses starting with the 10g version, to the SCAN in the 11g version, it has been greatly simplified.
In the implementation of Failover, there are still certain usage restrictions. For example, the default implementation of SCAN-IP in 11g actually does not have a Failover option by default. If one of the two nodes hangs up, then If you continue to query in the original connection, you will be prompted that the session has been disconnected and needs to be reconnected. Client TAF will mainly discuss some simple contents of Failover Method and Failover Type.
(1)Failover Method
The main idea of Failover Method is to exchange failover time or exchange resources to achieve it.
It can be understood like this. Suppose we have two nodes. If a session is connected to node 2, but node 2 suddenly hangs up, in order to handle the Failover situation faster, the Failover Method has two types: preconnect and basic. kind.
— preconnect This pre-connection method will still occupy a lot of resources. It will pre-occupy some additional resources on each node. The switching will be relatively smoother and faster.
—Basic This method, when a Failover occurs, switches the corresponding resources. There will be some lag in the process, but the consumption of resources is relatively small.
To put it simply, the basic method will only judge when a fault occurs, while preconnect is to prepare for a rainy day; from a practical application, the basic method is more versatile and is also the default failover method.
(2)Failover Type
Failover Type implementation is richer, more flexible, and very powerful. At this time, the control granularity can be controlled based on the execution of user SQL. There are two types: select and session; let's illustrate with a small example.
For example, we have a large query on node 2, and node 2 suddenly hangs up. For the query being executed, for example, there are 10,000 pieces of data, and the result is detected just when the fault occurs. If you have 8,000 items, what should you do with the remaining 2,000?
The first way is to use select; that will complete the failover and continue to return the remaining 2,000 records. Of course, there will be some context switching in the middle, which is transparent to the user.
The second method is session; that is, disconnect directly and ask to query again.
In the 10g version, the configuration to achieve Load Balance+Failover with the help of VIP configuration is as follows:
racdb= (DESCRIPTION = (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.101)(PORT= 1521)) (ADDRESS= (PROTOCOL= TCP)(HOST=192.168.3.201)(PORT= 1521)) (LOAD_BALANCE = yes) (FAILOVER = ON) (CONNECT_DATA = (SERVER= DEDICATED) (SERVICE_NAME = racdb) (FAILOVER_MODE = (TYPE= SELECT) (METHOD= BASIC) (RETRIES = 30) (DELAY = 5)))) 如果11g的SCAN-IP也想进一步扩展Failover,同样也需要设置failover_mode和对应的类型。 RACDB = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = rac-scan)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = RACDB) ) )
From this perspective, Oracle's plan is really sophisticated. Let’s take a look at MySQL’s solution.
The distributed solution makes MySQL look like a Swiss knife. Regarding network level requirements, it can be said that MySQL has no requirements. If you apply for one master and one slave, you only need 4 IPs. (Master, slave, VIP, MHA_Manager (consider a manager node)), one master and two slaves are 5.

MySQL does not natively support so-called load balancing at this point. It can be diverted through front-end business, such as using middleware proxy, or continuous splitting, to achieve a certain level. After the granularity, the requirements are met through architectural design. Because logic-based replication is easy to expand, one master and multiple slaves are very common, and the cost is not high. The delay cannot be said to be zero, but just very low, and it can adapt to most Internet business needs.
Speaking of the conditions that trigger MHA switching, from a network perspective, the following red dots are potential hazards. Some are network interruptions, and some are network delays. When a failure occurs, it is better to protect the data. The performance is stable and can be customized based on your own needs. From this point of view, there is a probability of losing data. It is definitely not a lossless copy with strong consistency.
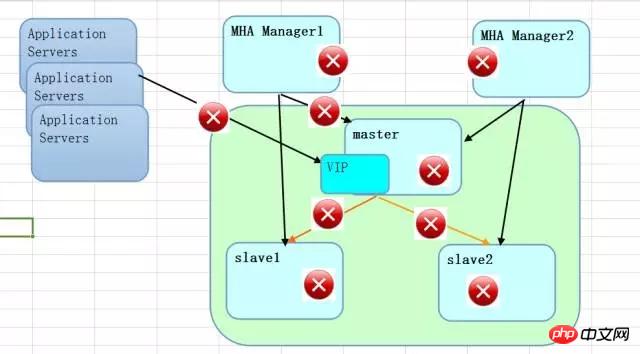
Looking at the two solutions overall, RAC is centralized sharing. In addition to sharing at the storage level, multicast at the network level will actually increase the cost of communication between nodes, so RAC has great demands on the network. If there is delay, it is very dangerous. If a split brain occurs, it will be very embarrassing. MySQL MHA's solution is distributed. Supporting high-volume environments, the cost of communication between nodes is relatively low. But from the perspective of data architecture, because it is a replicated data distribution method, although the storage is not shared storage, the cost of storage is still higher than RAC (not the price of storage, but the amount of data stored).
Related recommendations:
Oracle and Mysql generate sequence sequences respectively
Comparison of some simple commands between Oracle and MySQL_MySQL
For comparison of some simple commands between Oracle and mysql, please refer to [Photo]_MySQL
The above is the detailed content of Comparative analysis of high availability solutions for Oracle and MySQL. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
Why Use MySQL? Benefits and Advantages
Apr 12, 2025 am 12:17 AM
MySQL is chosen for its performance, reliability, ease of use, and community support. 1.MySQL provides efficient data storage and retrieval functions, supporting multiple data types and advanced query operations. 2. Adopt client-server architecture and multiple storage engines to support transaction and query optimization. 3. Easy to use, supports a variety of operating systems and programming languages. 4. Have strong community support and provide rich resources and solutions.
 MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL: An Introduction to the World's Most Popular Database
Apr 12, 2025 am 12:18 AM
MySQL is an open source relational database management system, mainly used to store and retrieve data quickly and reliably. Its working principle includes client requests, query resolution, execution of queries and return results. Examples of usage include creating tables, inserting and querying data, and advanced features such as JOIN operations. Common errors involve SQL syntax, data types, and permissions, and optimization suggestions include the use of indexes, optimized queries, and partitioning of tables.
 How to read the oracle awr report
Apr 11, 2025 pm 09:45 PM
How to read the oracle awr report
Apr 11, 2025 pm 09:45 PM
An AWR report is a report that displays database performance and activity snapshots. The interpretation steps include: identifying the date and time of the activity snapshot. View an overview of activities and resource consumption. Analyze session activities to find session types, resource consumption, and waiting events. Find potential performance bottlenecks such as slow SQL statements, resource contention, and I/O issues. View waiting events, identify and resolve them for performance. Analyze latch and memory usage patterns to identify memory issues that are causing performance issues.
 How to use triggers for oracle
Apr 11, 2025 pm 11:57 PM
How to use triggers for oracle
Apr 11, 2025 pm 11:57 PM
Triggers in Oracle are stored procedures used to automatically perform operations after a specific event (insert, update, or delete). They are used in a variety of scenarios, including data verification, auditing, and data maintenance. When creating a trigger, you need to specify the trigger name, association table, trigger event, and trigger time. There are two types of triggers: the BEFORE trigger is fired before the operation, and the AFTER trigger is fired after the operation. For example, the BEFORE INSERT trigger ensures that the age column of the inserted row is not negative.
 How to create oracle dynamic sql
Apr 12, 2025 am 06:06 AM
How to create oracle dynamic sql
Apr 12, 2025 am 06:06 AM
SQL statements can be created and executed based on runtime input by using Oracle's dynamic SQL. The steps include: preparing an empty string variable to store dynamically generated SQL statements. Use the EXECUTE IMMEDIATE or PREPARE statement to compile and execute dynamic SQL statements. Use bind variable to pass user input or other dynamic values to dynamic SQL. Use EXECUTE IMMEDIATE or EXECUTE to execute dynamic SQL statements.
 MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's Place: Databases and Programming
Apr 13, 2025 am 12:18 AM
MySQL's position in databases and programming is very important. It is an open source relational database management system that is widely used in various application scenarios. 1) MySQL provides efficient data storage, organization and retrieval functions, supporting Web, mobile and enterprise-level systems. 2) It uses a client-server architecture, supports multiple storage engines and index optimization. 3) Basic usages include creating tables and inserting data, and advanced usages involve multi-table JOINs and complex queries. 4) Frequently asked questions such as SQL syntax errors and performance issues can be debugged through the EXPLAIN command and slow query log. 5) Performance optimization methods include rational use of indexes, optimized query and use of caches. Best practices include using transactions and PreparedStatemen
 What to do if the oracle can't be opened
Apr 11, 2025 pm 10:06 PM
What to do if the oracle can't be opened
Apr 11, 2025 pm 10:06 PM
Solutions to Oracle cannot be opened include: 1. Start the database service; 2. Start the listener; 3. Check port conflicts; 4. Set environment variables correctly; 5. Make sure the firewall or antivirus software does not block the connection; 6. Check whether the server is closed; 7. Use RMAN to recover corrupt files; 8. Check whether the TNS service name is correct; 9. Check network connection; 10. Reinstall Oracle software.
 How to solve garbled code in oracle
Apr 11, 2025 pm 10:09 PM
How to solve garbled code in oracle
Apr 11, 2025 pm 10:09 PM
Oracle garbled problems can be solved by checking the database character set to ensure they match the data. Set the client character set to match the database. Convert data or modify column character sets to match database character sets. Use Unicode character sets and avoid multibyte character sets. Check that the language settings of the database and client are correct.
