

How to implement CSS selector field parsing

Based on the basic CSS syntax knowledge learned above, now let’s implement field parsing. First, parse the title. Open the web developer tools and find the source code corresponding to the title. This article mainly introduces the relevant information about CSS selector implementation of field parsing. Friends who need it can refer to it. I hope it can help everyone
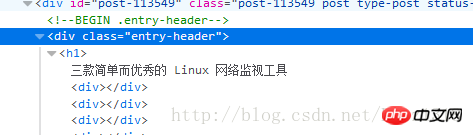
I found it in p class= "entry-header"In the h1 node below, I opened scrapy shell for debugging

But I don’t want the
tag, what should I do? At this time, you need to use the pseudo-class method in the CSS selector. As follows.

Note the two colons. Using CSS selectors is really convenient. In the same way, I use CSS to implement field parsing. The code is as follows
# -*- coding: utf-8 -*-
import scrapy
import re
class JobboleSpider(scrapy.Spider):
name = 'jobbole'
allowed_domains = ['blog.jobbole.com']
start_urls = ['http://blog.jobbole.com/113549/']
def parse(self, response):
# title = response.xpath('//p[@class = "entry-header"]/h1/text()').extract()[0]
# create_date = response.xpath("//p[@class = 'entry-meta-hide-on-mobile']/text()").extract()[0].strip().replace("·","").strip()
# praise_numbers = response.xpath("//span[contains(@class,'vote-post-up')]/h10/text()").extract()[0]
# fav_nums = response.xpath("//span[contains(@class,'bookmark-btn')]/text()").extract()[0]
# match_re = re.match(".*?(\d+).*",fav_nums)
# if match_re:
# fav_nums = match_re.group(1)
# comment_nums = response.xpath("//a[@href='#article-comment']/span").extract()[0]
# match_re = re.match(".*?(\d+).*", comment_nums)
# if match_re:
# comment_nums = match_re.group(1)
# content = response.xpath("//p[@class='entry']").extract()[0]
#通过CSS选择器提取字段
title = response.css(".entry-header h1::text").extract()[0]
create_date = response.css(".entry-meta-hide-on-mobile::text").extract()[0].strip().replace("·","").strip()
praise_numbers = response.css(".vote-post-up h10::text").extract()[0]
fav_nums = response.css("span.bookmark-btn::text").extract()[0]
match_re = re.match(".*?(\d+).*", fav_nums)
if match_re:
fav_nums = match_re.group(1)
comment_nums = response.css("a[href='#article-comment'] span::text").extract()[0]
match_re = re.match(".*?(\d+).*", comment_nums)
if match_re:
comment_nums = match_re.group(1)
content = response.css("p.entry").extract()[0]
tags = response.css("p.entry-meta-hide-on-mobile a::text").extract()[0]
pass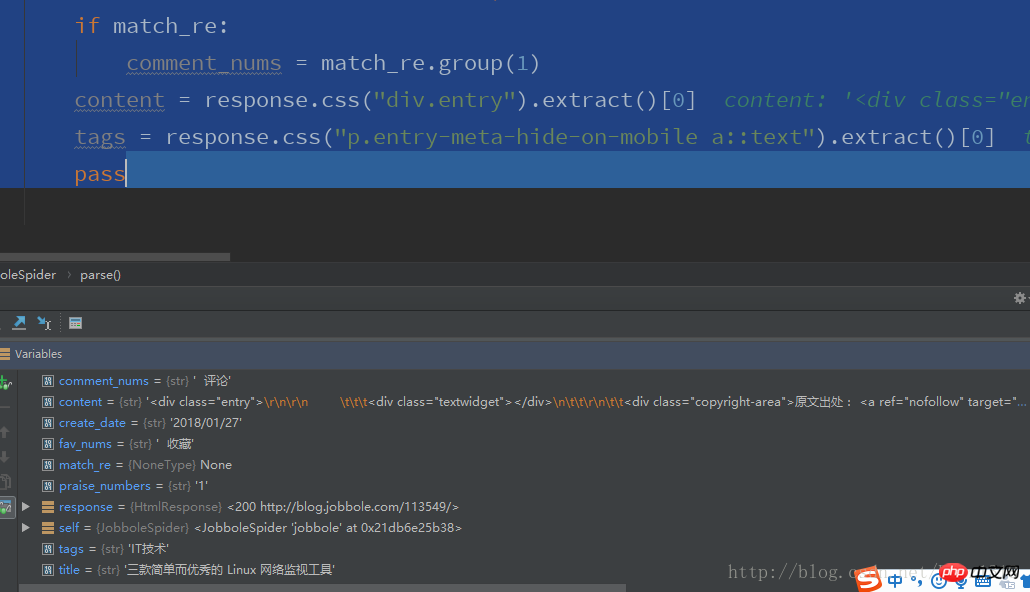
Related recommendations:
OpenERP employee (employee) table and user Table related field analysis
The above is the detailed content of How to implement CSS selector field parsing. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to write split lines on bootstrap
Apr 07, 2025 pm 03:12 PM
How to write split lines on bootstrap
Apr 07, 2025 pm 03:12 PM
There are two ways to create a Bootstrap split line: using the tag, which creates a horizontal split line. Use the CSS border property to create custom style split lines.
 How to insert pictures on bootstrap
Apr 07, 2025 pm 03:30 PM
How to insert pictures on bootstrap
Apr 07, 2025 pm 03:30 PM
There are several ways to insert images in Bootstrap: insert images directly, using the HTML img tag. With the Bootstrap image component, you can provide responsive images and more styles. Set the image size, use the img-fluid class to make the image adaptable. Set the border, using the img-bordered class. Set the rounded corners and use the img-rounded class. Set the shadow, use the shadow class. Resize and position the image, using CSS style. Using the background image, use the background-image CSS property.
 How to resize bootstrap
Apr 07, 2025 pm 03:18 PM
How to resize bootstrap
Apr 07, 2025 pm 03:18 PM
To adjust the size of elements in Bootstrap, you can use the dimension class, which includes: adjusting width: .col-, .w-, .mw-adjust height: .h-, .min-h-, .max-h-
 How to set up the framework for bootstrap
Apr 07, 2025 pm 03:27 PM
How to set up the framework for bootstrap
Apr 07, 2025 pm 03:27 PM
To set up the Bootstrap framework, you need to follow these steps: 1. Reference the Bootstrap file via CDN; 2. Download and host the file on your own server; 3. Include the Bootstrap file in HTML; 4. Compile Sass/Less as needed; 5. Import a custom file (optional). Once setup is complete, you can use Bootstrap's grid systems, components, and styles to create responsive websites and applications.
 The Roles of HTML, CSS, and JavaScript: Core Responsibilities
Apr 08, 2025 pm 07:05 PM
The Roles of HTML, CSS, and JavaScript: Core Responsibilities
Apr 08, 2025 pm 07:05 PM
HTML defines the web structure, CSS is responsible for style and layout, and JavaScript gives dynamic interaction. The three perform their duties in web development and jointly build a colorful website.
 How to use bootstrap button
Apr 07, 2025 pm 03:09 PM
How to use bootstrap button
Apr 07, 2025 pm 03:09 PM
How to use the Bootstrap button? Introduce Bootstrap CSS to create button elements and add Bootstrap button class to add button text
 How to use bootstrap in vue
Apr 07, 2025 pm 11:33 PM
How to use bootstrap in vue
Apr 07, 2025 pm 11:33 PM
Using Bootstrap in Vue.js is divided into five steps: Install Bootstrap. Import Bootstrap in main.js. Use the Bootstrap component directly in the template. Optional: Custom style. Optional: Use plug-ins.
 How to view the date of bootstrap
Apr 07, 2025 pm 03:03 PM
How to view the date of bootstrap
Apr 07, 2025 pm 03:03 PM
Answer: You can use the date picker component of Bootstrap to view dates in the page. Steps: Introduce the Bootstrap framework. Create a date selector input box in HTML. Bootstrap will automatically add styles to the selector. Use JavaScript to get the selected date.
