

A brief introduction to React

This article mainly shares with you the origin and development of React. I hope it can help you.
Character Splicing Era - 2004
Back in 2004, Mark Zuckerberg was still working on the original version of Facebook in his dormitory.
This year, everyone is using PHP’s String Concatenation function to develop websites.
$str = '<ul>';
foreach ($talks as $talk) {
$str += '<li>' . $talk->name . '</li>';
}
$str += '</ul>';This method of website development seemed very correct at the time, because no matter it is back-end development or front-end development, or even without development experience at all, you can use this method to build a large website.
The only drawback is that this development method can easily cause XSS injection and other security issues. If $talk->name contains malicious code and no protective measures are taken, the attacker can inject arbitrary JS code. This gave rise to the security rule of "never trust user input".
The simplest solution is to escape (Escape) any input from the user. However, this also brings other troubles. If the string is escaped multiple times, the number of anti-escaping must also be the same, otherwise the original content will not be obtained. If you accidentally escape the HTML tag (Markup), the HTML tag will be displayed directly to the user, resulting in a poor user experience.
XHP Era - 2010
In 2010, in order to code more efficiently and avoid errors of escaping HTML tags, Facebook developed XHP. XHP is a grammar extension to PHP, which allows developers to use HTML tags directly in PHP instead of using strings.
$content = <ul />;
foreach ($talks as $talk) {
$content->appendChild(<li>{$talk->name}</li>);
}In this case, all HTML tags use syntax different from PHP, and we can easily distinguish which ones need to be escaped and which ones do not.
Soon later, Facebook engineers discovered that they could also create custom tags, and that combining custom tags could help build large applications.
And this is exactly one way to implement the concept of Semantic Web and Web Components.
$content = <talk:list />;
foreach ($talks as $talk) {
$content->appendChild(<talk talk={$talk} />);
}After that, Facebook tried more new technical methods in JS to reduce the delay between the client and the server. Such as cross-browser DOM libraries and data binding, but they are not ideal.
JSX - 2013
Wait until 2013, and suddenly one day, front-end engineer Jordan Walke proposed a bold idea to his manager: migrate the extended functions of XHP to JS. At first everyone thought he was crazy because it was incompatible with the JS framework that everyone was optimistic about at the time. But he eventually convinced his manager to give him six months to test the idea. I have to say here that Facebook’s good engineering management philosophy is admirable and worth learning from.
Attachment: Lee Byron talks about Facebook engineer culture: Why Invest in Tools
To migrate the extended functions of XHP to JS, the first task is to need an extension to allow JS to support XML syntax. The extension is called JSX. At that time, with the rise of Node.js, there was already considerable engineering practice within Facebook for converting JS. So implementing JSX was a piece of cake and only took about a week.
const content = (
<TalkList>
{ talks.map(talk => <Talk talk={talk} />)}
</TalkList>
);React
Since then, React’s long march has begun, and greater difficulties are still to come. Among them, the trickiest thing is how to reproduce the update mechanism in PHP.
In PHP, whenever the data changes, you only need to jump to a new page rendered by PHP.
From a developer's perspective, developing applications in this way is very simple, because it does not need to worry about changes, and all content is synchronized when user data on the interface changes.
As long as there is a data change, the entire page will be re-rendered.
Although simple and crude, the shortcoming of this method is also particularly prominent, that is, it is very slow.
"You need to be right before being good" means that in order to verify the feasibility of the migration plan, developers must quickly implement a usable version, regardless of performance issues for the time being.
DOM
Inspired by PHP, the simplest way to implement re-rendering in JS is: when any content changes, rebuild the entire DOM, Then replace the old DOM with the new DOM.
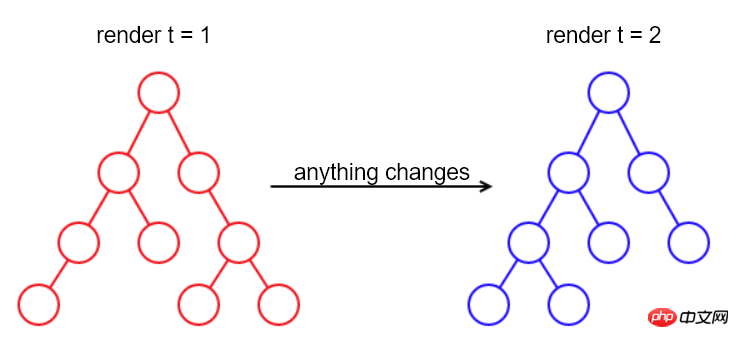
This method can work, but it is not applicable in some scenarios.
For example, it will lose the currently focused element and cursor, as well as text selection and page scroll position, which are the current state of the page.
In other words, DOM nodes are that contain state.
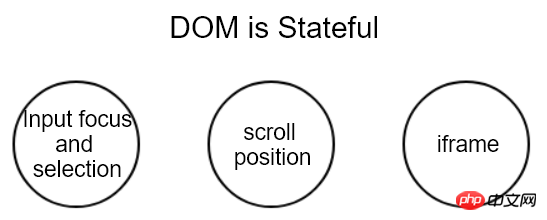
Since it contains state, wouldn’t it be enough to record the state of the old DOM and then restore it on the new DOM?
But unfortunately, this method is not only complicated to implement but also cannot cover all situations.
When scrolling the page on an OSX computer, there will be a certain amount of scrolling inertia. However, JS does not provide a corresponding API to read or write scrolling inertia.
For pages containing iframe, the situation is more complicated. If it comes from another domain, browser security policy restrictions won't allow us to view the content inside it at all, let alone restore it.
So it can be seen that DOM not only has state, it also contains hidden and unreachable state.
Since restoring the state doesn't work, then find another way to get around it.
For DOM nodes that have not changed, leave them as they are, and only create and replace the changed DOM nodes.
This method implements DOM node reuse (Reuse).
At this point, as long as we can identifywhich nodes have changed, we can update the DOM. So the question turns into How to compare the differences between the two DOM.
Diff
Speaking of comparison differences, I believe everyone can immediately think of Version Control (Version Control). Its principle is very simple. Record multiple code snapshots, and then use the diff algorithm to compare the two snapshots before and after, thereby generating a series of changes such as "delete 5 lines", "add 3 lines", "replace words", etc.; through Apply this series of changes to the previous code snapshot to get the subsequent code snapshot.
This is exactly what React needs, except that it processes DOM instead of text files.
No wonder some people say: "I tend to think of React as Version Control for the DOM".
DOM is a tree structure, so the diff algorithm must be based on the tree structure. The complexity of the currently known complete tree structure diff algorithm is O(n^3).
If there are 10,000 DOM nodes in the page, this number may seem huge, but it is not unimaginable. To calculate the order of magnitude of this complexity, we also assume that we can complete a single comparison operation in one CPU cycle (although this is impossible), and that the CPU is clocked at 1 GHz. In this case, the time the diff takes is as follows:
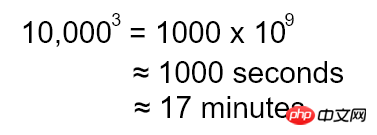
A full 17 minutes long, which is simply unimaginable!
Although the verification phase does not consider performance issues for the time being, we can still briefly understand how the algorithm is implemented.
Attachment: Complete Tree diff implementation algorithm.
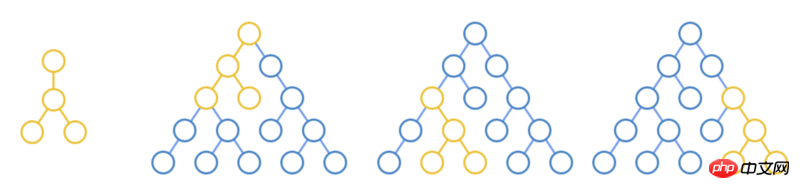
Compare each node on the new tree with each node on the old tree
If the parent nodes are the same, continue to loop and compare the subtrees
In the tree above, according to the principle of minimum operations, you can find three nested loop comparisons.
But if you think about it carefully, in web applications, there are very few scenarios where you move an element to another place. An example might be to drag and drop an element to another place, but it's not common.
The only common scenario is to move elements between sub-elements, such as adding, deleting and moving elements in a list. In this case, you can only compare nodes at the same level.
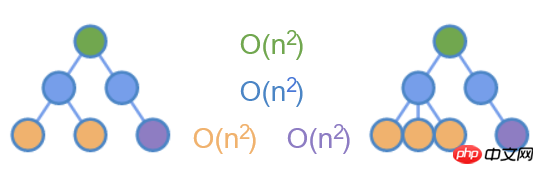
As shown in the figure above, only diffing nodes of the same color can reduce the time complexity to O(n^2).
key

Another problem is introduced for the comparison of elements at the same level.
When the names of elements at the same level are different, they can be directly identified as mismatches; when they are the same, it is not that simple.
Suppose under a certain node, three <input /> were rendered last time, and then two were rendered the next time. What will be the result of diff at this time?
The most intuitive result is to keep the first two unchanged and delete the third one.
Of course, you can also delete the first one while keeping the last two.
If you don't mind it, you can delete all three old ones and add two new elements.
This shows that for nodes with the same label name, we do not have enough information to compare the differences before and after.

What if we add the attributes of the element? For example, value, if the tag name and value attribute are the same twice before and after, then the element is considered to be matching and does not need to be changed. But the reality is that this doesn't work, because the value is always changing when the user enters, which will cause the element to be replaced all the time, causing it to lose focus; what's worse, not all HTML elements have this attribute.

那使用所有元素都有的 id 属性呢?这是可以的,如上图,我们可以容易的识别出前后 DOM 的差异。考虑表单情况,表单模型的输入通常跟 id 关联,但如果使用 AJAX 来提交表单的话,我们通常不会给 input 设置 id 属性。因此,更好的办法是引入一个新的属性名称,专门用来辅助 diff 算法。这个属性最终确定为 key 。这也是为什么在 React 中使用列表时会要求给子元素设置 key 属性的原因。
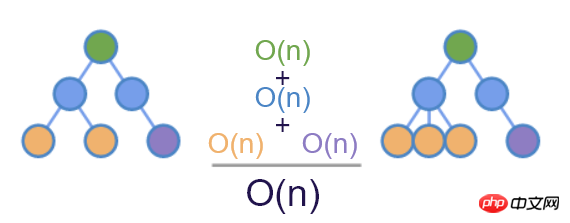
结合 key ,再加上哈希表,diff 算法最终实现了 O(n) 的最优复杂度。
至此,可以看到从 XHP 迁移到 JS 的方案可行的。接下来就可以针对各个环节进行逐步优化。
附:详细的 diff 理解:不可思议的 react diff 。
持续优化
Virtual DOM
前面说到,React 其实实现了对 DOM 节点的版本控制。
做过 JS 应用优化的人可能都知道,DOM 是复杂的,对它的操作(尤其是查询和创建)是非常慢非常耗费资源的。看下面的例子,仅创建一个空白的 p,其实例属性就达到 231 个。
// Chrome v63
const p = document.createElement('p');
let m = 0;
for (let k in p) {
m++;
}
console.log(m); // 231之所以有这么多属性,是因为 DOM 节点被用于浏览器渲染管道的很多过程中。
浏览器首先根据 CSS 规则查找匹配的节点,这个过程会缓存很多元信息,例如它维护着一个对应 DOM 节点的 id 映射表。
然后,根据样式计算节点布局,这里又会缓存位置和屏幕定位信息,以及其他很多的元信息,浏览器会尽量避免重新计算布局,所以这些数据都会被缓存。
可以看出,整个渲染过程会耗费大量的内存和 CPU 资源。
现在回过头来想想 React ,其实它只在 diff 算法中用到了 DOM 节点,而且只用到了标签名称和部分属性。
如果用更轻量级的 JS 对象来代替复杂的 DOM 节点,然后把对 DOM 的 diff 操作转移到 JS 对象,就可以避免大量对 DOM 的查询操作。这种方式称为 Virtual DOM 。
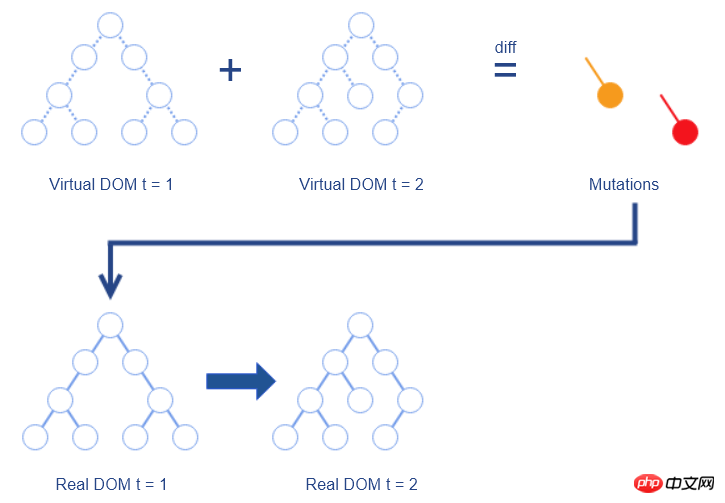
其过程如下:
维护一个使用 JS 对象表示的 Virtual DOM,与真实 DOM 一一对应
对前后两个 Virtual DOM 做 diff ,生成变更(Mutation)
把变更应用于真实 DOM,生成最新的真实 DOM
可以看出,因为要把变更应用到真实 DOM 上,所以还是避免不了要直接操作 DOM ,但是 React 的 diff 算法会把 DOM 改动次数降到最低。
至此,React 的两大优化:diff 算法和 Virtual DOM ,均已完成。再加上 XHP 时代尝试的数据绑定,已经算是一个可用版本了。
这个时候 Facebook 做了个重大的决定,那就是把 React 开源!
React 的开源可谓是一石激起千层浪,社区开发者都被这种全新的 Web 开发方式所吸引,React 因此迅速占领了 JS 开源库的榜首。
很多大公司也把 React 应用到生产环境,同时也有大批社区开发者为 React 贡献了代码。
接下来要说的两大优化就是来自于开源社区。
批处理(Batching)
著名浏览器厂商 Opera 把重排和重绘(Reflow and Repaint)列为影响页面性能的三大原因之一。
我们说 DOM 是很慢的,除了前面说到的它的复杂和庞大,还有另一个原因就是重排和重绘。
当 DOM 被修改后,浏览器必须更新元素的位置和真实像素;
当尝试从 DOM 读取属性时,为了保证读取的值是正确的,浏览器也会触发重排和重绘。
因此,反复的“读取、修改、读取、修改...”操作,将会触发大量的重排和重绘。
另外,由于浏览器本身对 DOM 操作进行了优化,比如把两次很近的“修改”操作合并成一个“修改”操作。
所以如果把“读取、修改、读取、修改...”重新排列为“读取、读取...”和“修改、修改...”,会有助于减小重排和重绘的次数。但是这种刻意的、手动的级联写法是不安全的。
与此同时,常规的 JS 写法又很容易触发重排和重绘。
在减小重排和重绘的道路上,React 陷入了尴尬的处境。
In the end, community contributor Ben Alpert used batch processing to save this embarrassing situation.
In React, developers tell React that the current component is going to change by calling the component's setState method.
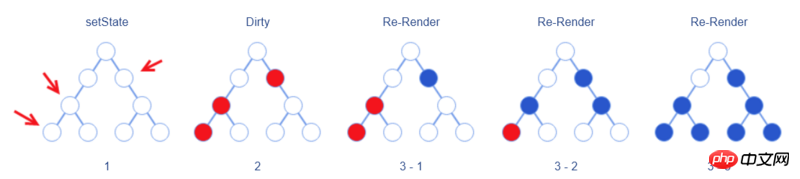
Ben Alpert’s approach is to not immediately synchronize the changes to the Virtual DOM when calling setState, but only to Elements are marked "to be updated". If setState is called multiple times in the component, the same marking operation will be performed.
After the initialization event is completely broadcast, the re-rendering (Re-Render) process from top to bottom begins. This ensures that React only renders the element once.
Two points should be noted here:
The re-rendering here refers to synchronizing the
setStatechanges to the Virtual DOM; only proceed after this The diff operation generates actual DOM changes.Different from the "re-rendering the entire DOM" mentioned above, the real re-rendering only renders the marked element and its sub-elements, that is to say, only the blue element in the above picture is The element represented by the colored circle will be re-rendered
This also reminds developers that should keep stateful components as close as possible to leaf nodes, so that the re-rendering time can be reduced scope.
Pruning
As the application becomes larger and larger, React will manage more and more component states, which means that the scope of re-rendering will also become larger and larger. .
Carefully observing the above batch processing process, we can find that the three elements in the lower right corner of the Virtual DOM have not actually changed, but because the change of their parent nodes also caused their re-rendering, it is useless to do more. operate.
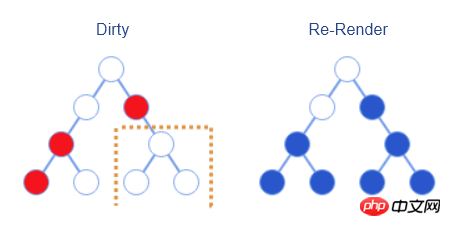
For this situation, React itself has already taken this into consideration and provides bool shouldComponentUpdate(nextProps, nextState) interface. Developers can manually implement this interface to compare the before and after status and properties to determine whether re-rendering is needed. In this case, re-rendering becomes the process shown in the figure below.
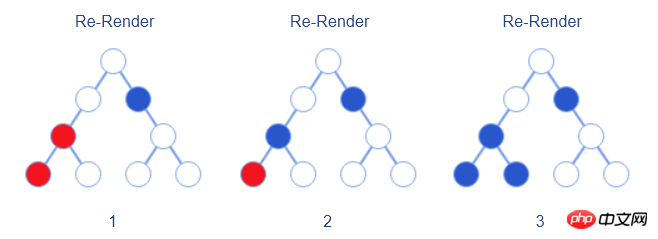
At that time, although React provided the shouldComponentUpdate interface, it did not provide a default implementation (always rendering) , developers must implement it manually to achieve the desired effect.
The reason is that in JS, we usually use objects to save state, and when modifying the state, we directly modify the state object. In other words, the two different states before and after the modification point to the same object, so when directly comparing whether the two objects have changed, they are the same, even if the state has changed.
In this regard, David Nolen proposed a solution based on Immutable Data Structure.
This solution is inspired by ClojureScript. In ClojureScript, most values are immutable. In other words, when a value needs to be updated, the program does not modify the original value, but creates a new value based on the original value, and then uses the new value for assignment.
David used ClojureScript to write an immutable data structure solution for React: Om, which provides a default implementation for shouldComponentUpdate.
However, because immutable data structures were not widely accepted by web engineers, this feature was not incorporated into React at that time.
Unfortunately, as of now, shouldComponentUpdate still does not provide a default implementation.
But David has opened up a good research direction for developers.
If you really want to use immutable data structures to improve React performance, you can refer to Facebook Immutable.js, which comes from the same school as React. It is a good partner for React!
Conclusion
The optimization of React is still continuing. For example, Fiber is newly introduced in React 16. It is a reconstruction of the core algorithm, that is, it redesigns the method and timing of detecting changes, allowing The rendering process can be done in stages rather than all at once.
Due to space limitations, this article will not introduce Fiber in depth. Those who are interested can refer to What React Fiber is.
Related recommendations:
Detailed explanation of React component life cycle
Detailed explanation of react controlled components and uncontrolled components
Example of writing a paging component using react
The above is the detailed content of A brief introduction to React. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1390
1390
 52
52

 The easiest way to query the hard drive serial number
Feb 26, 2024 pm 02:24 PM
The easiest way to query the hard drive serial number
Feb 26, 2024 pm 02:24 PM
The hard disk serial number is an important identifier of the hard disk and is usually used to uniquely identify the hard disk and identify the hardware. In some cases, we may need to query the hard drive serial number, such as when installing an operating system, finding the correct device driver, or performing hard drive repairs. This article will introduce some simple methods to help you check the hard drive serial number. Method 1: Use Windows Command Prompt to open the command prompt. In Windows system, press Win+R keys, enter "cmd" and press Enter key to open the command
 Detailed introduction to what wapi is
Jan 07, 2024 pm 09:14 PM
Detailed introduction to what wapi is
Jan 07, 2024 pm 09:14 PM
Users may have seen the term wapi when using the Internet, but for some people they definitely don’t know what wapi is. The following is a detailed introduction to help those who don’t know to understand. What is wapi: Answer: wapi is the infrastructure for wireless LAN authentication and confidentiality. This is like functions such as infrared and Bluetooth, which are generally covered near places such as office buildings. Basically they are owned by a small department, so the scope of this function is only a few kilometers. Related introduction to wapi: 1. Wapi is a transmission protocol in wireless LAN. 2. This technology can avoid the problems of narrow-band communication and enable better communication. 3. Only one code is needed to transmit the signal
 Detailed explanation of whether win11 can run PUBG game
Jan 06, 2024 pm 07:17 PM
Detailed explanation of whether win11 can run PUBG game
Jan 06, 2024 pm 07:17 PM
Pubg, also known as PlayerUnknown's Battlegrounds, is a very classic shooting battle royale game that has attracted a lot of players since its popularity in 2016. After the recent launch of win11 system, many players want to play it on win11. Let's follow the editor to see if win11 can play pubg. Can win11 play pubg? Answer: Win11 can play pubg. 1. At the beginning of win11, because win11 needed to enable tpm, many players were banned from pubg. 2. However, based on player feedback, Blue Hole has solved this problem, and now you can play pubg normally in win11. 3. If you meet a pub
 PHP, Vue and React: How to choose the most suitable front-end framework?
Mar 15, 2024 pm 05:48 PM
PHP, Vue and React: How to choose the most suitable front-end framework?
Mar 15, 2024 pm 05:48 PM
PHP, Vue and React: How to choose the most suitable front-end framework? With the continuous development of Internet technology, front-end frameworks play a vital role in Web development. PHP, Vue and React are three representative front-end frameworks, each with its own unique characteristics and advantages. When choosing which front-end framework to use, developers need to make an informed decision based on project needs, team skills, and personal preferences. This article will compare the characteristics and uses of the three front-end frameworks PHP, Vue and React.
 Introducing the latest Win 11 sound tuning method
Jan 08, 2024 pm 06:41 PM
Introducing the latest Win 11 sound tuning method
Jan 08, 2024 pm 06:41 PM
After updating to the latest win11, many users find that the sound of their system has changed slightly, but they don’t know how to adjust it. So today, this site brings you an introduction to the latest win11 sound adjustment method for your computer. It is not difficult to operate. And the choices are diverse, come and download and try them out. How to adjust the sound of the latest computer system Windows 11 1. First, right-click the sound icon in the lower right corner of the desktop and select "Playback Settings". 2. Then enter settings and click "Speaker" in the playback bar. 3. Then click "Properties" on the lower right. 4. Click the "Enhance" option bar in the properties. 5. At this time, if the √ in front of "Disable all sound effects" is checked, cancel it. 6. After that, you can select the sound effects below to set and click
 PyCharm Beginner's Guide: Comprehensive Analysis of Replacement Functions
Feb 25, 2024 am 11:15 AM
PyCharm Beginner's Guide: Comprehensive Analysis of Replacement Functions
Feb 25, 2024 am 11:15 AM
PyCharm is a powerful Python integrated development environment with rich functions and tools that can greatly improve development efficiency. Among them, the replacement function is one of the functions frequently used in the development process, which can help developers quickly modify the code and improve the code quality. This article will introduce PyCharm's replacement function in detail, combined with specific code examples, to help novices better master and use this function. Introduction to the replacement function PyCharm's replacement function can help developers quickly replace specified text in the code
 Integration of Java framework and front-end React framework
Jun 01, 2024 pm 03:16 PM
Integration of Java framework and front-end React framework
Jun 01, 2024 pm 03:16 PM
Integration of Java framework and React framework: Steps: Set up the back-end Java framework. Create project structure. Configure build tools. Create React applications. Write REST API endpoints. Configure the communication mechanism. Practical case (SpringBoot+React): Java code: Define RESTfulAPI controller. React code: Get and display the data returned by the API.
 Detailed information on the location of the printer driver on your computer
Jan 08, 2024 pm 03:29 PM
Detailed information on the location of the printer driver on your computer
Jan 08, 2024 pm 03:29 PM
Many users have printer drivers installed on their computers but don't know how to find them. Therefore, today I bring you a detailed introduction to the location of the printer driver in the computer. For those who don’t know yet, let’s take a look at where to find the printer driver. When rewriting content without changing the original meaning, you need to The language is rewritten to Chinese, and the original sentence does not need to appear. First, it is recommended to use third-party software to search. 2. Find "Toolbox" in the upper right corner. 3. Find and click "Device Manager" below. Rewritten sentence: 3. Find and click "Device Manager" at the bottom 4. Then open "Print Queue" and find your printer device. This time it is your printer name and model. 5. Right-click the printer device and you can update or uninstall it.
