

How to increase page views using threads and httpclient

I am just thinking of a request here. I verify the request once and the number of views increases by 1. So I pressed F5 to refresh, but it didn't actually increase every time. I continued to verify and found that it would increase by 1 if I pressed F5 again. Now that the basic feature analysis is complete, dear, do you have any ideas? I think of the previous crawlers here, which just request the page, get the returned HTML and then parse the string. So I also learned from this idea and used the server to request the link, and then the rest is the waiting time. If I keep browsing regardless, there may be suspicion of malicious requests, and my account will be banned. So what technology is suitable for this scenario? Have you thought about it? Yes, you can use threads to set the sleep time after each request.
Then the general idea is clear: httpClient sends a request, and the thread controls the pause time. Without further ado, let me get down to the code:
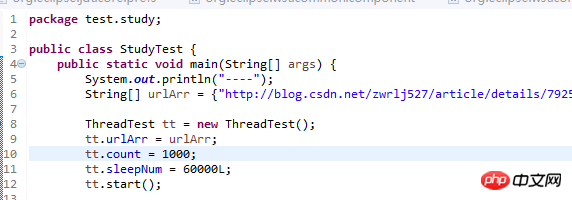
Everyone should be familiar with the main above. My idea here is that there are three variables in the thread class. Before I use , set the variables first after new comes out, so that they can be used later in the thread run method. Here are 4 ways to implement multi-threading. This seems to have been mentioned in a blog post before.
There are four ways to implement multi-threading, most of which are the first two without return values.
1. Inherit the Thread class to create a thread
The Thread class is essentially an instance that implements the Runnable interface and represents an instance of a thread. The only way to start a thread is through the start() instance method of the Thread class. The start() method is a native method that will start a new thread and execute the run() method. It is very simple to implement multi-threading in this way. By extending Thread directly through your own class and overriding the run() method, you can start a new thread and execute your own defined run() method. For example:
public class MyThread extends Thread { public void run() { System.out.println("MyThread.run()"); } } MyThread myThread1 = new MyThread(); MyThread myThread2 = new MyThread (); myThread1.start(); myThread2.start();
2. Implement the Runnable interface to create a thread
If your own class already extends another class, you cannot directly extend Thread. At this time, a Runnable interface can be implemented, as follows:
public class MyThread extends OtherClass implements Runnable { public void run() { System.out.println("MyThread.run()"); } }
In order to start MyThread, you need to instantiate a Thread first and pass in your own MyThread instance:
MyThread myThread = new MyThread(); Thread thread = new Thread(myThread); thread.start( );
In fact, when a Runnable target parameter is passed to Thread, Thread's run() method will call target.run(), refer to the JDK source code:
public void run() { if (target != null) { target.run(); } }
3. Implement the Callable interface and create a Thread thread through the FutureTask wrapper
Callable interface (also only A method) is defined as follows:
public interface Callable
public class SomeCallable
Callable
4. Use ExecutorService, Callable, and Future to implement threads that return results.
The three interfaces of ExecutorService, Callable, and Future actually belong to the Executor framework. The thread that returns the result is a new feature introduced in JDK1.5. With this feature, you no longer need to go through a lot of trouble to get the return value. And even if you implement it yourself, it may be full of loopholes.
Tasks that can return values must implement the Callable interface. Similarly, tasks that do not return a value must implement the Runnable interface.
After executing the Callable task, you can obtain a Future object. By calling get on the object, you can obtain the Object returned by the Callable task.
Note: The get method is blocking, that is: the thread returns no result, and the get method will wait forever.
Combined with the thread pool interface ExecutorService, the legendary multi-threading with returned results can be realized.
Getting back to the subject, I am using the first one here because I don’t need a return value.
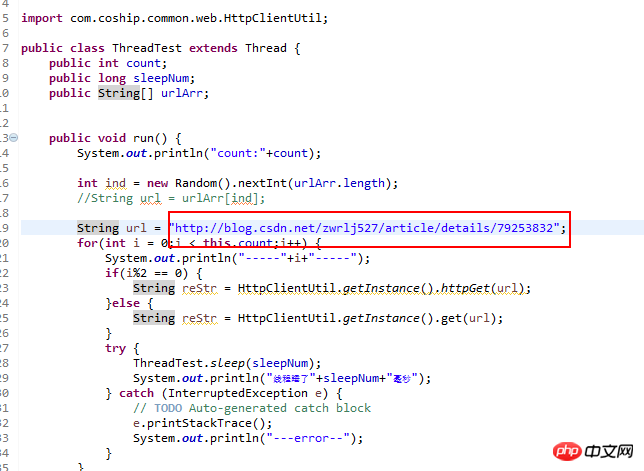
What is added here is the idea of swiping multiple addresses, as well as the odd and even request method to avoid using the same request method every time and avoid being blocked by the system. Listed as a risk for malicious requests. And the sleep time can be set in main. Let’s take a look at the reading volume before the refresh:
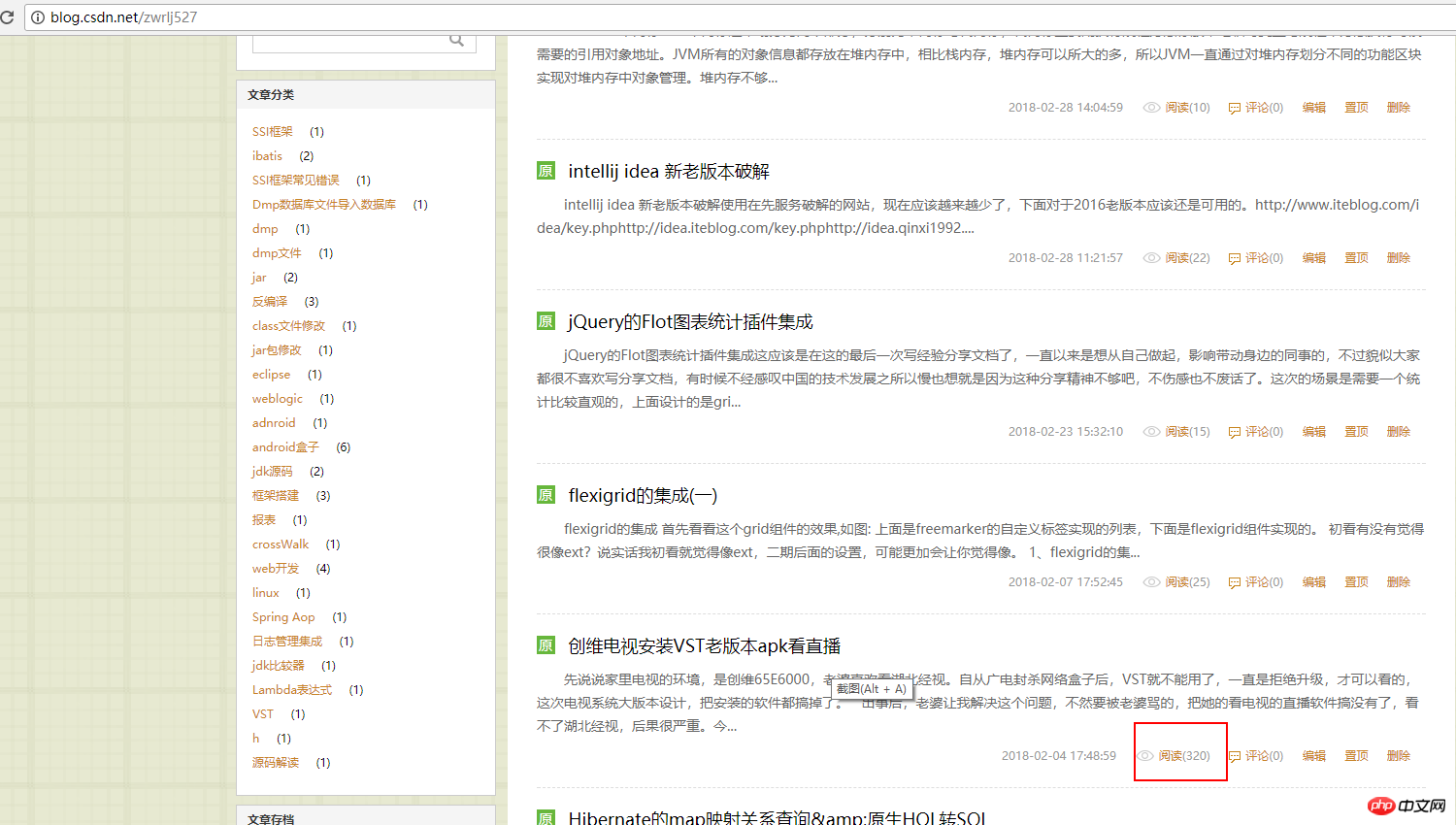
I went to bed after writing this last night, and the computer was not turned off. Take a look at this How many requests have been received in the evening:
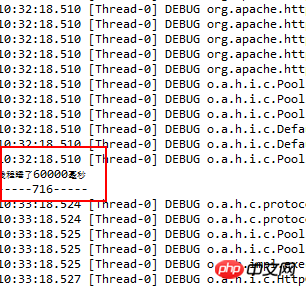
Then, I refresh the following list page and look at the reading volume again:
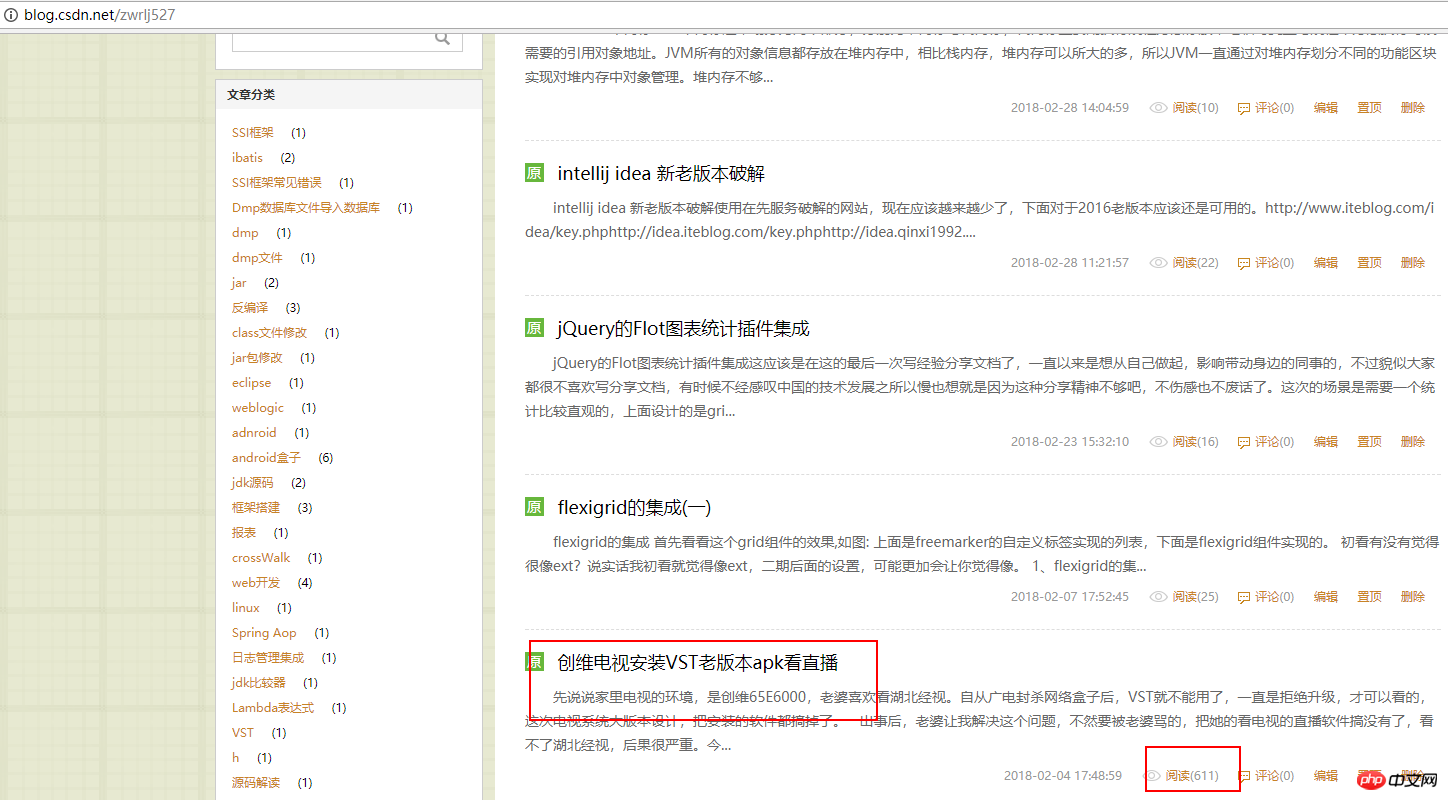
Did you see that the number of reads is now more than 600, compared with only more than 300 before.
Because the IP has always been this, the sleep time in the middle is a bit long. If there is an IP for switching and switching logic is added, the effect will be better.
Theoretically speaking, all reading volume can be increased by this method, of course, provided that the client does not implement strict policies such as requesting the same IP multiple times and counting it as one reading. I can’t find out how to rate those articles in Baidu Wenku as excellent documents, but I think it must have something to do with the number of requests. If you have the opportunity, you can try this idea. You can modify it to create two threads and alternate them, one thread brushes one website, haha.
But don’t blame me if your account is banned, haha.
Related recommendations:
How to use thinkPHP+ajax to achieve statistical page pv views
The above is the detailed content of How to increase page views using threads and httpclient. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics



 What are some ways to increase Douyin views? What are the techniques?
Mar 07, 2024 pm 08:07 PM
What are some ways to increase Douyin views? What are the techniques?
Mar 07, 2024 pm 08:07 PM
With the popularity and development of social media, Douyin has become a platform for many people to showcase their talents and gain attention. However, while posting a video is easy, getting a lot of views is not. So, how to increase TikTok views? Some effective methods and techniques will be introduced below. 1. Methods to increase TikTok views 1. Carefully select content: Choosing high-quality, engaging, and unique content is crucial to attracting viewers. Continuing to innovate and provide useful information piques your audience's interest and makes them want to share it with others. Leveraging trending topics can help you gain more attention and viewers on TikTok. There are often popular topics or challenges on TikTok that you can participate in to make your videos more discoverable. Hot attention
 What should I do if win11 cannot use ie11 browser? (win11 cannot use IE browser)
Feb 10, 2024 am 10:30 AM
What should I do if win11 cannot use ie11 browser? (win11 cannot use IE browser)
Feb 10, 2024 am 10:30 AM
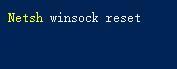
More and more users are starting to upgrade the win11 system. Since each user has different usage habits, many users are still using the ie11 browser. So what should I do if the win11 system cannot use the ie browser? Does windows11 still support ie11? Let’s take a look at the solution. Solution to the problem that win11 cannot use the ie11 browser 1. First, right-click the start menu and select "Command Prompt (Administrator)" to open it. 2. After opening, directly enter "Netshwinsockreset" and press Enter to confirm. 3. After confirmation, enter "netshadvfirewallreset&rdqu
 Internet Explorer opens Edge: How to stop MS Edge redirection
Apr 14, 2023 pm 06:13 PM
Internet Explorer opens Edge: How to stop MS Edge redirection
Apr 14, 2023 pm 06:13 PM
It's no secret that Internet Explorer has fallen out of favor for a long time, but with the arrival of Windows 11, reality sets in. Rather than sometimes replacing IE in the future, Edge is now the default browser in Microsoft's latest operating system. For now, you can still enable Internet Explorer in Windows 11. However, IE11 (the latest version) already has an official retirement date, which is June 15, 2022, and the clock is ticking. With this in mind, you may have noticed that Internet Explorer sometimes opens Edge, and you may not like it. So why is this happening? exist
 Is the number of plays equal to the number of views?
Sep 08, 2023 pm 02:28 PM
Is the number of plays equal to the number of views?
Sep 08, 2023 pm 02:28 PM
The number of views is not the number of views, but two different concepts. The number of views refers to the number of times media content is played. It is usually used to measure the popularity of media content and the interest of the audience. The number of views can be used to measure video websites, music The number of views of content on online platforms such as platforms and social media. Pageviews refer to the number of times a webpage, website or application page is visited. It is usually used to measure the traffic and user activity of a website or application. Pageviews can be used to evaluate website traffic, advertising exposure, and user response to Level of interest in specific content.
 Send HTTP request and handle response using HttpClient in Java 11
Aug 01, 2023 am 11:48 AM
Send HTTP request and handle response using HttpClient in Java 11
Aug 01, 2023 am 11:48 AM
Title: Sending HTTP requests and handling responses using HttpClient in Java11 Introduction: In modern Internet applications, HTTP communication with other servers is a very common task. Java provides some built-in tools that can help us achieve this goal. The latest and recommended one is the HttpClient class introduced in Java11. This article will introduce how to use HttpClient in Java11 to send HTTP requests and process responses,
 How to use http.Client in golang for advanced operations of HTTP requests
Nov 18, 2023 am 11:37 AM
How to use http.Client in golang for advanced operations of HTTP requests
Nov 18, 2023 am 11:37 AM
How to use http.Client in golang for advanced operations of HTTP requests Introduction: In modern development, HTTP requests are an inevitable part. Golang provides a powerful standard library, which includes the http package. The http package provides the http.Client structure for sending HTTP requests and receiving HTTP responses. In this article, we will explore how to use http.Client to perform advanced operations on HTTP requests and provide specific code examples.
 How to compare redirection and request forwarding using httpclient in Java
Apr 21, 2023 pm 11:43 PM
How to compare redirection and request forwarding using httpclient in Java
Apr 21, 2023 pm 11:43 PM
Here is an introduction: In HttpClient4.x version, the get request method will automatically redirect, but the post request method will not automatically redirect. This is something to pay attention to. The last time I made an error was when I used post to submit the form to log in, and there was no automatic redirection at that time. The difference between request forwarding and redirection 1. Redirection is two requests, and forwarding is one request, so the forwarding speed is faster than redirection. 2. After redirection, the address on the address bar will change to the address requested for the second time. After forwarding, the address on the address bar will not change and remains the address requested for the first time. 3. Forwarding is a server behavior, and redirection is a client behavior. When redirecting, the URL on the browser changes; when forwarding, the URL on the browser remains unchanged.
 How to cancel the automatic jump to Edge when opening IE in Win10_Solution to the automatic jump of IE browser page
Mar 20, 2024 pm 09:21 PM
How to cancel the automatic jump to Edge when opening IE in Win10_Solution to the automatic jump of IE browser page
Mar 20, 2024 pm 09:21 PM
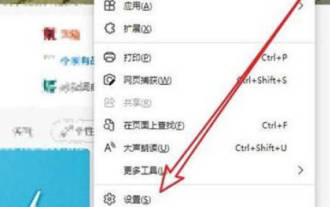
Recently, many win10 users have found that their IE browser always automatically jumps to the edge browser when using computer browsers. So how to turn off the automatic jump to edge when opening IE in win10? Let this site carefully introduce to users how to automatically jump to edge and close when opening IE in win10. 1. We log in to the edge browser, click... in the upper right corner, and look for the drop-down settings option. 2. After we enter the settings, click Default Browser in the left column. 3. Finally, in the compatibility, we check the box to not allow the website to be reloaded in IE mode and restart the IE browser.
