

I always thought that my vue was good, and I always thought that webpack was good. When I was browsing node in MOOC today, I realized that I was still far behind. As we all know, vue-cli is based on webpack, and webpack is based on node. If you don’t know node, how can you understand webpack? So I asked myself a question to crawl Douban data, which is still in its infancy. Today I will briefly talk about the data crawled from Douban and display it in your own way on another page. I will follow up later.
1. Problems that need to be solved
Building services
How to process the crawled data
How to automatically open the default browser
2. Build a service
It’s good to build a service There are several ways. I used http at the beginning, but the disadvantage of http is that it cannot parse URLs of https protocol, so I used express. To parse URLs of https protocol, I used the request package. Douban’s URL is https,
Today I crawled the URL https://movie.douban.com/chart; as shown below, there are three parts I want to get, the picture, the movie name, and the movie link.
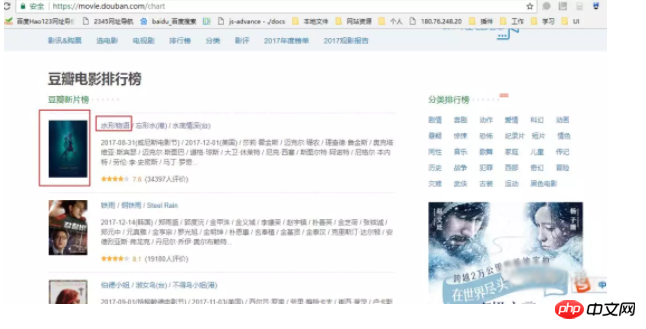

3. How to process the crawled data
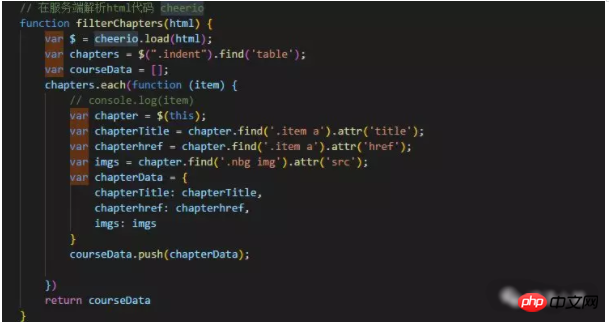
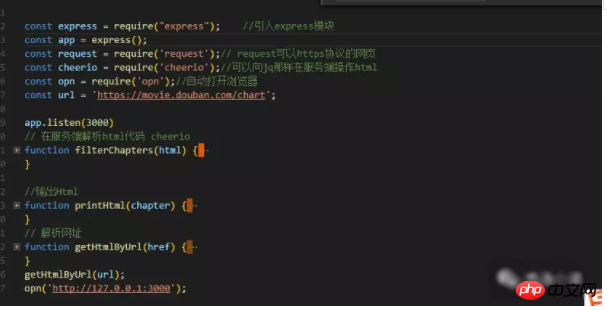
How to process the data we crawled using request? The cheerio package allows us to process crawled html data like Jq.
①. First parse the data and get the html data of the crawled web page;
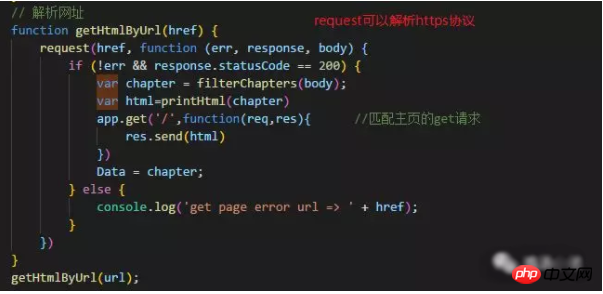
②. Then use the cheerio package to operate the crawled data and get the data you want.
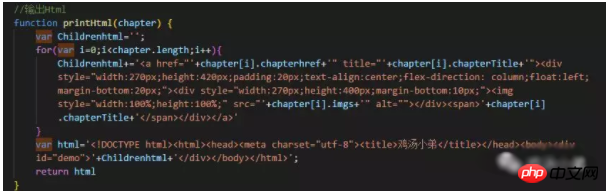
③. Get the data, create html, and output it to the page. As shown below, the string splicing method I used is a bit stupid, and I haven't found a better method yet.
4. How to automatically open the default browser
I don’t know if you have looked at the configuration of webpack in vue-cli. Automatically Open the browser and see the opn package used by vue-cli.
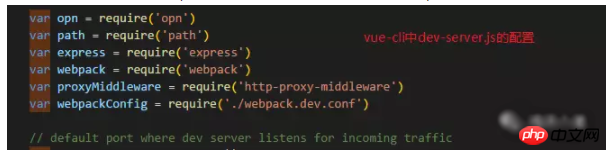
This package is very convenient to use. Just import the package and call opn (url) directly;
5. Display
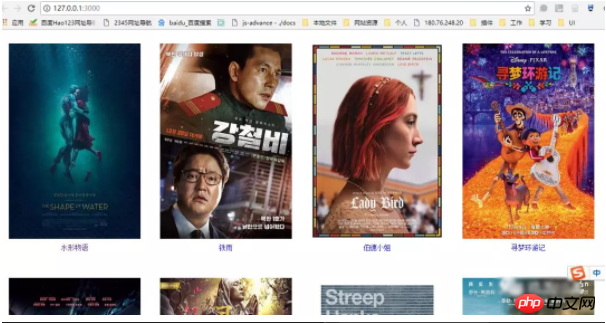
Related recommendations:
How to crawl php Get Tmall and Taobao product data
nodejs implements the function of crawling website images_node.js
Recommended courses on crawling images 5 Chapter
The above is the detailed content of Example sharing of how Node.js crawls Douban data. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



