

Scrapy and scrapy-splash framework quickly load js pages

1. Preface
When we use crawler programs to crawl web pages, crawling static pages is generally relatively simple, and we have written many cases before. But how to crawl pages dynamically loaded using js?
There are several crawling methods for dynamic js pages:
Achieved through selenium+phantomjs.
phantomjs is a headless browser, selenium is an automated testing framework, request the page through the headless browser, wait for js to load, and then obtain the data through automated testing selenium . Because headless browsers consume a lot of resources, they are lacking in performance.
Scrapy-splash framework:
Splash as a js rendering service is lightweight based on Twisted and QT development Browser engine and provides direct http api. The fast and lightweight features make it easy for distributed development.
The splash and scrapy crawler frameworks are integrated. The two are compatible with each other and have better crawling efficiency.
2. Splash environment construction
The Splash service is based on docker containers, so we need to install docker containers first.
2.1 Docker installation (windows 10 home version)
If it is win 10 professional version or other operating systems, it is easier to install. To install docker in windows 10 home version, you need to go through toolbox ( Requires the latest) tools to be installed.
Regarding the installation of docker, refer to the document: Install Docker on WIN10
2.2 splash installation
docker pull scrapinghub/splash
2.3 Start the Splash service
docker run -p 8050:8050 scrapinghub/splash
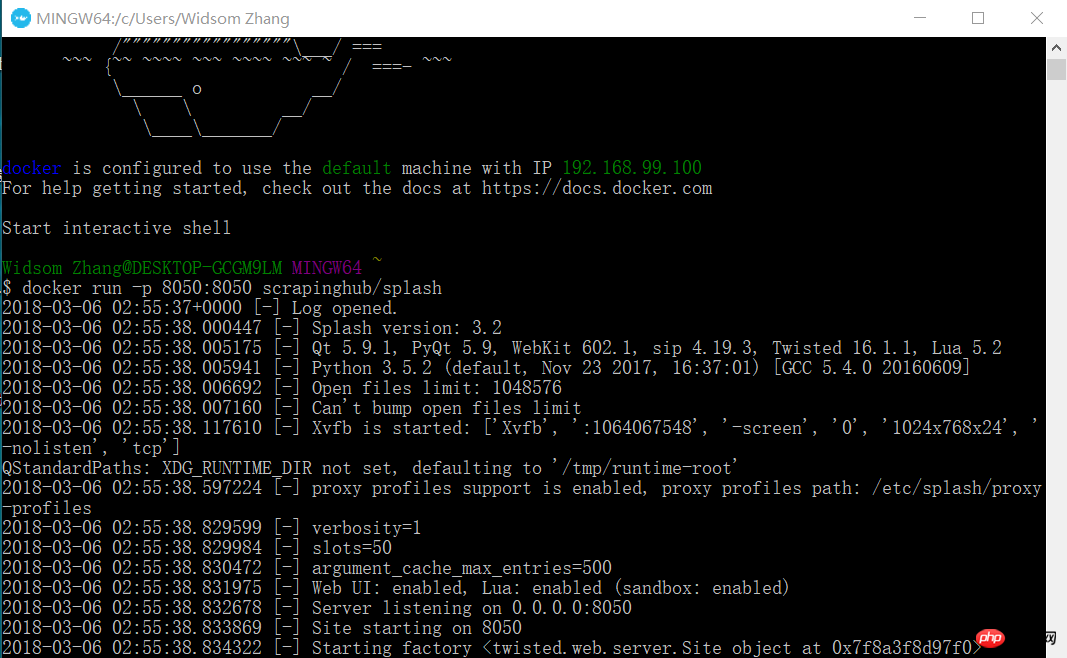
At this time, open your browser and enter 192.168.99.100:8050. You will see an interface like this.
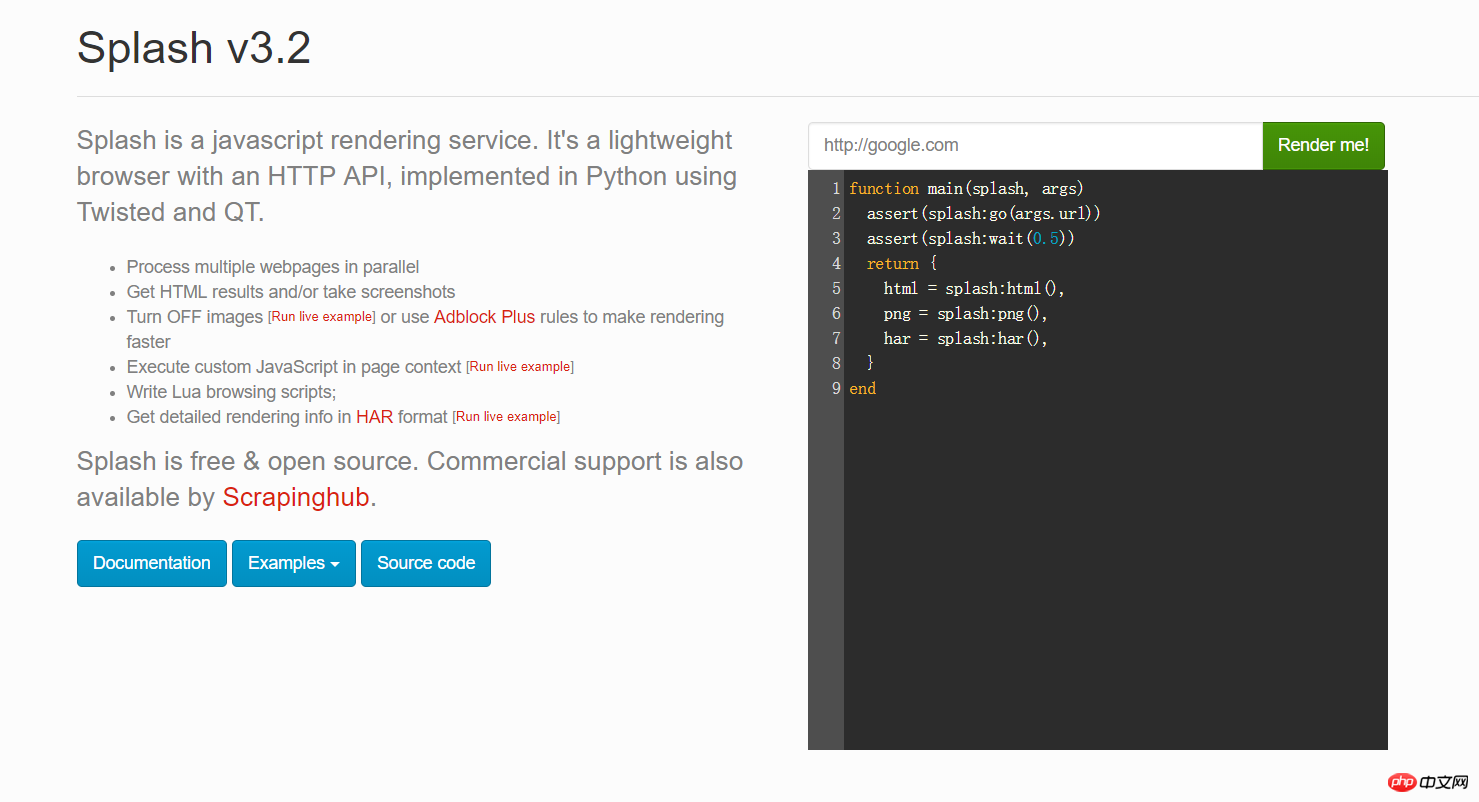
You can enter any URL in the red box in the picture above and click Render me! to see what it will look like after rendering
2.4 Install python Scrapy-splash package
pip install scrapy-splash
3. Scrapy crawler loading js project test, taking google news as an example.
Due to business needs, we crawl some foreign news websites, such as Google News. But I found that it was actually js code. So I started to use the scrapy-splash framework and cooperated with Splash's js rendering service to obtain data. See the following code for details:
3.1 settings.py configuration information
# 渲染服务的urlSPLASH_URL = 'http://192.168.99.100:8050'# 去重过滤器DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'# 使用Splash的Http缓存HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'SPIDER_MIDDLEWARES = { 'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}#下载器中间件DOWNLOADER_MIDDLEWARES = { 'scrapy_splash.SplashCookiesMiddleware': 723, 'scrapy_splash.SplashMiddleware': 725, 'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}# 请求头DEFAULT_REQUEST_HEADERS = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36', 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
}# 管道ITEM_PIPELINES = { 'news.pipelines.NewsPipeline': 300,
}3.2 items field definition
class NewsItem(scrapy.Item): # 标题
title = scrapy.Field() # 图片的url链接
Scrapy and scrapy-splash framework quickly load js pages_url = scrapy.Field() # 新闻来源
source = scrapy.Field() # 点击的url
action_url = scrapy.Field()3.3 Spider code
In the spider directory, create A new_spider.py file, the file content is as follows:
from scrapy import Spiderfrom scrapy_splash import SplashRequestfrom news.items import NewsItemclass GoolgeNewsSpider(Spider):
name = "google_news"
start_urls = ["https://news.google.com/news/headlines?ned=cn&gl=CN&hl=zh-CN"] def start_requests(self):
for url in self.start_urls: # 通过SplashRequest请求等待1秒
yield SplashRequest(url, self.parse, args={'wait': 1}) def parse(self, response):
for element in response.xpath('//p[@class="qx0yFc"]'):
actionUrl = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/@href').extract_first()
title = element.xpath('.//a[@class="nuEeue hzdq5d ME7ew"]/text()').extract_first()
source = element.xpath('.//span[@class="IH8C7b Pc0Wt"]/text()').extract_first()
Scrapy and scrapy-splash framework quickly load js pagesUrl = element.xpath('.//img[@class="lmFAjc"]/@src').extract_first()
item = NewsItem()
item['title'] = title
item['Scrapy and scrapy-splash framework quickly load js pages_url'] = Scrapy and scrapy-splash framework quickly load js pagesUrl
item['action_url'] = actionUrl
item['source'] = source yield item3.4 pipelines.py code
Store the item data in the mysql database.
Create db_news database
CREATE DATABASE db_news
Create tb_news table
CREATE TABLE tb_google_news(
id INT AUTO_INCREMENT,
title VARCHAR(50),
Scrapy and scrapy-splash framework quickly load js pages_url VARCHAR(200),
action_url VARCHAR(200),
source VARCHAR(30), PRIMARY KEY(id)
)ENGINE=INNODB DEFAULT CHARSET=utf8;NewsPipeline class
class NewsPipeline(object):
def __init__(self):
self.conn = pymysql.connect(host='localhost', port=3306, user='root', passwd='root', db='db_news',charset='utf8')
self.cursor = self.conn.cursor() def process_item(self, item, spider):
sql = '''insert into tb_google_news (title,Scrapy and scrapy-splash framework quickly load js pages_url,action_url,source) values(%s,%s,%s,%s)'''
self.cursor.execute(sql, (item["title"], item["Scrapy and scrapy-splash framework quickly load js pages_url"], item["action_url"], item["source"]))
self.conn.commit() return item def close_spider(self):
self.cursor.close()
self.conn.close()3.5 Execute scrapy crawler
Execute on the console:
scrapy crawl google_news
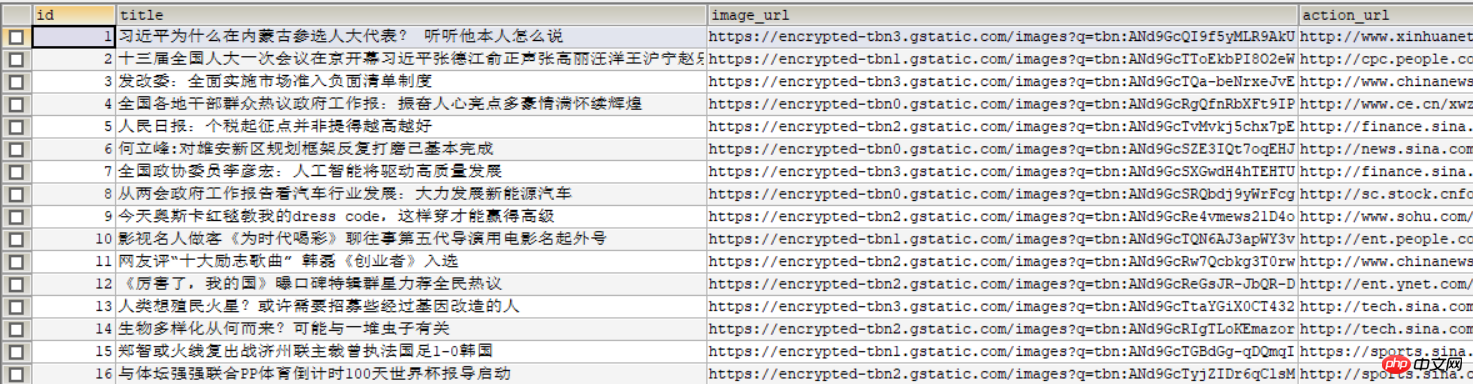
The following picture is displayed in the database:
Related recommendations:
Basic introduction to the scrapy command
scrapy crawler framework Introduction
The above is the detailed content of Scrapy and scrapy-splash framework quickly load js pages. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to implement an online speech recognition system using WebSocket and JavaScript
Dec 17, 2023 pm 02:54 PM
How to use WebSocket and JavaScript to implement an online speech recognition system Introduction: With the continuous development of technology, speech recognition technology has become an important part of the field of artificial intelligence. The online speech recognition system based on WebSocket and JavaScript has the characteristics of low latency, real-time and cross-platform, and has become a widely used solution. This article will introduce how to use WebSocket and JavaScript to implement an online speech recognition system.
 WebSocket and JavaScript: key technologies for implementing real-time monitoring systems
Dec 17, 2023 pm 05:30 PM
WebSocket and JavaScript: key technologies for implementing real-time monitoring systems
Dec 17, 2023 pm 05:30 PM
WebSocket and JavaScript: Key technologies for realizing real-time monitoring systems Introduction: With the rapid development of Internet technology, real-time monitoring systems have been widely used in various fields. One of the key technologies to achieve real-time monitoring is the combination of WebSocket and JavaScript. This article will introduce the application of WebSocket and JavaScript in real-time monitoring systems, give code examples, and explain their implementation principles in detail. 1. WebSocket technology
 How to use JavaScript and WebSocket to implement a real-time online ordering system
Dec 17, 2023 pm 12:09 PM
How to use JavaScript and WebSocket to implement a real-time online ordering system
Dec 17, 2023 pm 12:09 PM
Introduction to how to use JavaScript and WebSocket to implement a real-time online ordering system: With the popularity of the Internet and the advancement of technology, more and more restaurants have begun to provide online ordering services. In order to implement a real-time online ordering system, we can use JavaScript and WebSocket technology. WebSocket is a full-duplex communication protocol based on the TCP protocol, which can realize real-time two-way communication between the client and the server. In the real-time online ordering system, when the user selects dishes and places an order
 How to implement an online reservation system using WebSocket and JavaScript
Dec 17, 2023 am 09:39 AM
How to implement an online reservation system using WebSocket and JavaScript
Dec 17, 2023 am 09:39 AM
How to use WebSocket and JavaScript to implement an online reservation system. In today's digital era, more and more businesses and services need to provide online reservation functions. It is crucial to implement an efficient and real-time online reservation system. This article will introduce how to use WebSocket and JavaScript to implement an online reservation system, and provide specific code examples. 1. What is WebSocket? WebSocket is a full-duplex method on a single TCP connection.
 JavaScript and WebSocket: Building an efficient real-time weather forecasting system
Dec 17, 2023 pm 05:13 PM
JavaScript and WebSocket: Building an efficient real-time weather forecasting system
Dec 17, 2023 pm 05:13 PM
JavaScript and WebSocket: Building an efficient real-time weather forecast system Introduction: Today, the accuracy of weather forecasts is of great significance to daily life and decision-making. As technology develops, we can provide more accurate and reliable weather forecasts by obtaining weather data in real time. In this article, we will learn how to use JavaScript and WebSocket technology to build an efficient real-time weather forecast system. This article will demonstrate the implementation process through specific code examples. We
 Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
Simple JavaScript Tutorial: How to Get HTTP Status Code
Jan 05, 2024 pm 06:08 PM
JavaScript tutorial: How to get HTTP status code, specific code examples are required. Preface: In web development, data interaction with the server is often involved. When communicating with the server, we often need to obtain the returned HTTP status code to determine whether the operation is successful, and perform corresponding processing based on different status codes. This article will teach you how to use JavaScript to obtain HTTP status codes and provide some practical code examples. Using XMLHttpRequest
 How to use insertBefore in javascript
Nov 24, 2023 am 11:56 AM
How to use insertBefore in javascript
Nov 24, 2023 am 11:56 AM
Usage: In JavaScript, the insertBefore() method is used to insert a new node in the DOM tree. This method requires two parameters: the new node to be inserted and the reference node (that is, the node where the new node will be inserted).
 How to get HTTP status code in JavaScript the easy way
Jan 05, 2024 pm 01:37 PM
How to get HTTP status code in JavaScript the easy way
Jan 05, 2024 pm 01:37 PM
Introduction to the method of obtaining HTTP status code in JavaScript: In front-end development, we often need to deal with the interaction with the back-end interface, and HTTP status code is a very important part of it. Understanding and obtaining HTTP status codes helps us better handle the data returned by the interface. This article will introduce how to use JavaScript to obtain HTTP status codes and provide specific code examples. 1. What is HTTP status code? HTTP status code means that when the browser initiates a request to the server, the service
