

This article mainly shares with you the detailed explanation of HTTP request headers and request bodies. The study of HTTP mainly includes the four parts of HTTP basics, HTTP request headers and request bodies, HTTP response headers and status codes, and HTTP cache. For HTTP related As for the expansion and extension, we also need to understand the understanding and practice of HTTPS, HTTP/2 basics, and WebSocket basics. The knowledge points in this part are also summarized in the author's review of my road to school recruitment preparation: from Web front-end to server-side application architecture.
HTTP Request
HTTP request message is divided into three parts: request line, request header and request body. The format is as follows: 
A A typical request message header field is as follows:
POST/GET http://download.microtool.de:80/somedata.exe Host: download.microtool.de Accept:*/* Pragma: no-cache Cache-Control: no-cache Referer: http://download.microtool.de/ User-Agent:Mozilla/4.04[en](Win95;I;Nav) Range:bytes=554554-
The request line (Request Line) is divided into three parts: request method, request address and protocol and version , ends with CRLF(rn).
HTTP/1.1 defines 8 request methods: GET, POST, PUT, DELETE, PATCH, HEAD, OPTIONS, TRACE. The two most common ones are GET and POST. If it is a RESTful interface, GET and POST, DELETE, PUT.
Note that only the three verbs POST, PUT and PATCH will contain the request body, while the verbs GET, HEAD, DELETE, CONNECT, TRACE and OPTIONS will contain the request body. Does not contain request body.
| Header | Explanation | Example |
|---|---|---|
| Accept | Specify the content types that the client can receive | Accept: text/plain, text/html,application/json |
| Accept-Charset | The character encoding set that the browser can accept. | Accept-Charset: iso-8859-5 |
| Accept-Encoding | Specifies the content compression encoding type returned by the web server that the browser can support. | Accept-Encoding: compress, gzip |
| Accept-Language | Accept-Language: en,zh | |
| You can request one or more sub-range fields of the web page entity | Accept-Ranges: bytes | |
| HTTP authorization authorization certificate | Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== | ##Cache-Control |
| Cache-Control: no-cache | Connection | |
| Connection: close | Cookie | |
| Cookie: $Version=1; Skin=new; | ||
| Content-Length | Requested content length | Content- Length: 348 |
| Content-Type | The requested MIME information corresponding to the entity | Content-Type: application/x-www-form- urlencoded |
| Date | The date and time the request was sent | Date: Tue, 15 Nov 2010 08:12:31 GMT |
| Expect | Requested specific server behavior | Expect: 100-continue |
| From | Email of the user who made the request | From: user@email.com |
| Host | Specify the domain name and port number of the requested server | Host: www.zcmhi.com |
| If-Match | Only the request content matches the entity is valid | If-Match: "737060cd8c284d8af7ad3082f209582d" |
| If-Modified-Since | If the requested part is modified after the specified time, the request is successful. If it is not modified, a 304 code is returned | If-Modified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| If-None-Match | Return 304 code if the content has not changed , the parameter is the Etag previously sent by the server, compare it with the Etag responded by the server to determine whether it has changed | If-None-Match: “737060cd8c284d8af7ad3082f209582d” |
| If-Range | If the entity has not changed, the server sends the missing part from the client, otherwise the entire entity is sent.The parameter is also Etag | If-Range: “737060cd8c284d8af7ad3082f209582d” |
| If-Unmodified-Since | Only if the entity has not been modified after the specified time The request is successful | If-Unmodified-Since: Sat, 29 Oct 2010 19:43:31 GMT |
| Max-Forwards | Restricted information passed Time sent by proxies and gateways | Max-Forwards: 10 |
| Pragma | Used to contain implementation-specific instructions | Pragma : no-cache |
| Proxy-Authorization | Authorization certificate to connect to the proxy | Proxy-Authorization: Basic QWxhZGRpbjpvcGVuIHNlc2FtZQ== |
| Range | Request only a part of the entity, specify the range | Range: bytes=500-999 |
| Referer | The address of the previous web page, followed by the current requested web page, that is, the source | Referer: http://www.zcmhi.com/archives... |
| TE | The transfer encoding that the client is willing to accept, and notifies the server to accept the tail plus header information | TE: trailers,deflate;q=0.5 |
| Upgrade | Specify a transport protocol to the server for conversion (if supported) | Upgrade: HTTP/2.0, SHTTP/1.3, IRC/6.9, RTA/x11 |
| User-Agent | The content of User-Agent contains information about the user who made the request | User-Agent: Mozilla/5.0 (Linux; X11) |
| Via | Notify the intermediate gateway or proxy server address, communication protocol | Via: 1.0 fred, 1.1 nowhere.com (Apache/1.1) |
| Warning | Warning information about the message entity | Warn: 199 Miscellaneous warning |
根据应用场景的不同,HTTP请求的请求体有三种不同的形式。
移动开发者常见的,请求体是任意类型,服务器不会解析请求体,请求体的处理需要自己解析,如 POST JSON时候就是这类。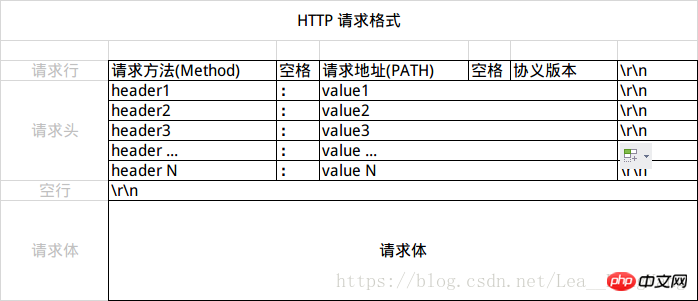
application/json 这个 Content-Type 作为响应头大家肯定不陌生。实际上,现在越来越多的人把它作为请求头,用来告诉服务端消息主体是序列化后的 JSON 字符串。由于 JSON 规范的流行,除了低版本 IE 之外的各大浏览器都原生支持 JSON.stringify,服务端语言也都有处理 JSON 的函数,使用 JSON 不会遇上什么麻烦。
JSON 格式支持比键值对复杂得多的结构化数据,这一点也很有用。记得我几年前做一个项目时,需要提交的数据层次非常深,我就是把数据 JSON 序列化之后来提交的。不过当时我是把 JSON 字符串作为 val,仍然放在键值对里,以 x-www-form-urlencoded 方式提交。
Google 的 AngularJS 中的 Ajax 功能,默认就是提交 JSON 字符串。例如下面这段代码:
JSvar data = {'title':'test', 'sub' : [1,2,3]};$http.post(url, data).success(function(result) {
...
});最终发送的请求是:
BASHPOST http://www.example.com HTTP/1.1 Content-Type: application/json;charset=utf-8{"title":"test","sub":[1,2,3]}这种方案,可以方便的提交复杂的结构化数据,特别适合 RESTful 的接口。各大抓包工具如 Chrome 自带的开发者工具、Firebug、Fiddler,都会以树形结构展示 JSON 数据,非常友好。但也有些服务端语言还没有支持这种方式,例如 php 就无法通过 $_POST 对象从上面的请求中获得内容。这时候,需要自己动手处理下:在请求头中 Content-Type 为 application/json 时,从 php://input 里获得原始输入流,再 json_decode 成对象。一些 php 框架已经开始这么做了。
当然 AngularJS 也可以配置为使用 x-www-form-urlencoded 方式提交数据。如有需要,可以参考这篇文章。
我的博客之前提到过 XML-RPC(XML Remote Procedure Call)。它是一种使用 HTTP 作为传输协议,XML 作为编码方式的远程调用规范。典型的 XML-RPC 请求是这样的:
HTMLPOST http://www.example.com HTTP/1.1
Content-Type: text/xml<?xml version="1.0"?><methodCall>
<methodName>examples.getStateName</methodName>
<params>
<param>
<value><i4>41</i4></value>
</param>
</params></methodCall>XML-RPC 协议简单、功能够用,各种语言的实现都有。它的使用也很广泛,如 WordPress 的 XML-RPC Api,搜索引擎的 ping 服务等等。JavaScript 中,也有现成的库支持以这种方式进行数据交互,能很好的支持已有的 XML-RPC 服务。不过,我个人觉得 XML 结构还是过于臃肿,一般场景用 JSON 会更灵活方便。
This is the most common way to submit data via POST. The browser's native
 http500 solution
http500 solution
 How to solve http request 415 error
How to solve http request 415 error
 HTTP 503 error solution
HTTP 503 error solution
 Recommended flash tools
Recommended flash tools
 what is adobe flash player
what is adobe flash player
 What are the new features of Hongmeng OS 3.0?
What are the new features of Hongmeng OS 3.0?
 How to modify element.style
How to modify element.style
 How to solve Java stack overflow exception
How to solve Java stack overflow exception
 Computer prompts that msvcr110.dll is missing and how to solve it
Computer prompts that msvcr110.dll is missing and how to solve it








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



