

Example sharing of python dynamic crawler
Mar 30, 2018 pm 04:41 PMThis article mainly shares with you examples of python dynamic crawlers. When using Python to crawl conventional static web pages, urllib2 is often used to obtain the entire HTML page, and then the corresponding keywords are searched word for word from the HTML file. As shown below:
#encoding=utf-8
import urllib2 url="http://mm.taobao.com/json/request_top_list.htm?type=0&page=1"up=urllib2.urlopen(url)#打开目标页面,存入变量upcont=up.read()#从up中读入该HTML文件key1='<a href="http'#设置关键字1key2="target"#设置关键字2pa=cont.find(key1)#找出关键字1的位置pt=cont.find(key2,pa)#找出关键字2的位置(从字1后面开始查找)urlx=cont[pa:pt]#得到关键字1与关键字2之间的内容(即想要的数据)print urlx
However, in dynamic pages, the displayed content is often not presented through HTML pages, but data is obtained from the database by calling js and other methods, and echoed to the web page.
Take the "Registration Information" (http://beian.hndrc.gov.cn/) on the National Development and Reform Commission website as an example. We need to capture some of the filing items on this page. For example "http://beian.hndrc.gov.cn/indexinvestment.jsp?id=162518".
Then, open this page in the browser:
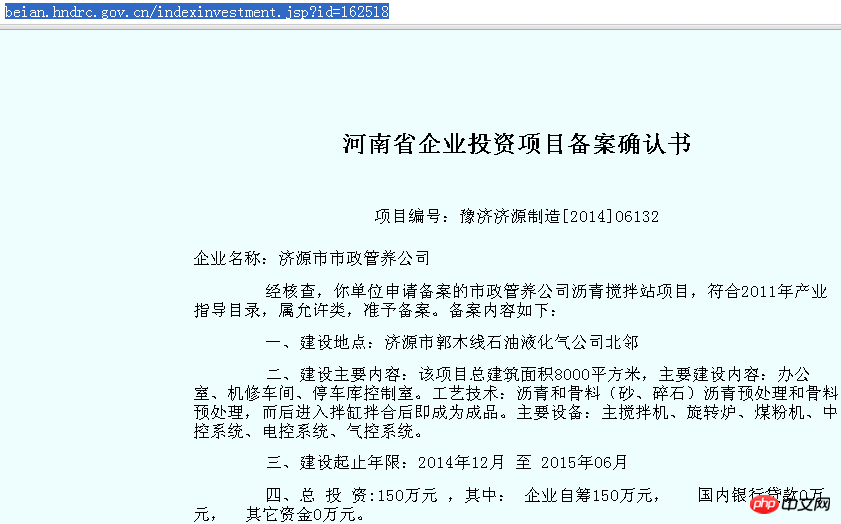
The relevant information is displayed completely, but if you follow the previous method:
up=urllib2.urlopen(url) cont=up.read()
cannot capture the above content.
Let’s check the source code corresponding to this page:

It can be seen from the source code that this "Filing Confirmation Letter" is in the form of "fill in the blanks", HTML A text template is provided, and js provides different variables according to different IDs, which are "filled in" into the text template to form a specific "Filing Confirmation Letter". So simply grabbing this HTML can only get some text templates, but not the specific content.
So, how to find those specific contents? You can use Chrome's "Developer Tools" to find out who the real content provider is.
Open the Chrome browser and press F12 on the keyboard to call out this tool. As shown below:
At this time, select the "Network" label and enter this page "http://beian.hndrc.gov.cn/indexinvestment.jsp?" in the address bar. id=162518", the browser will analyze the entire process of this response, and the files in the red box are all the communications between the browser and the web backend in this response.
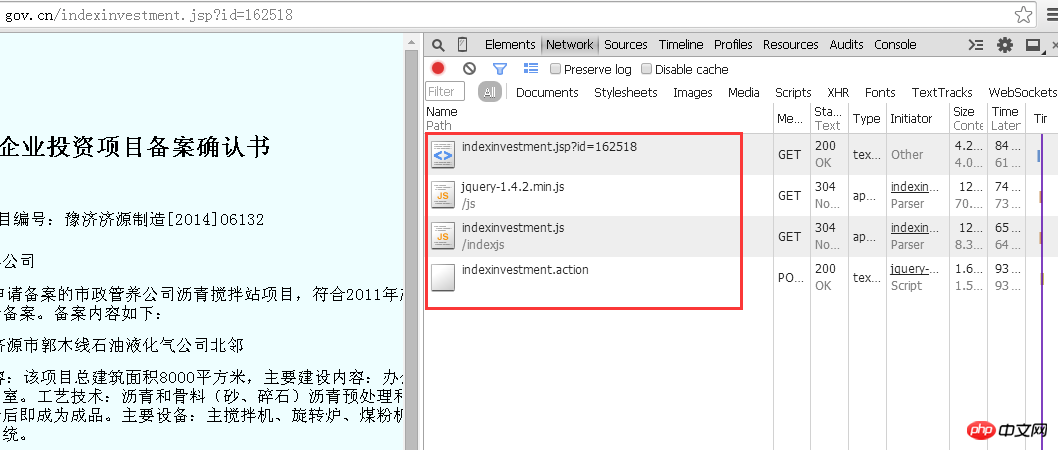
Because you want to obtain different information corresponding to different companies, the request sent by the browser to the server must have a parameter related to the current company ID.
So, what are the parameters? There is "jsp?id=162518" on the URL. The question mark indicates that the parameters are to be called, followed by the id number which is the parameter to be called. Through the analysis of these files, it is obvious that corporate information exists in the "indexinvestment.action" file.
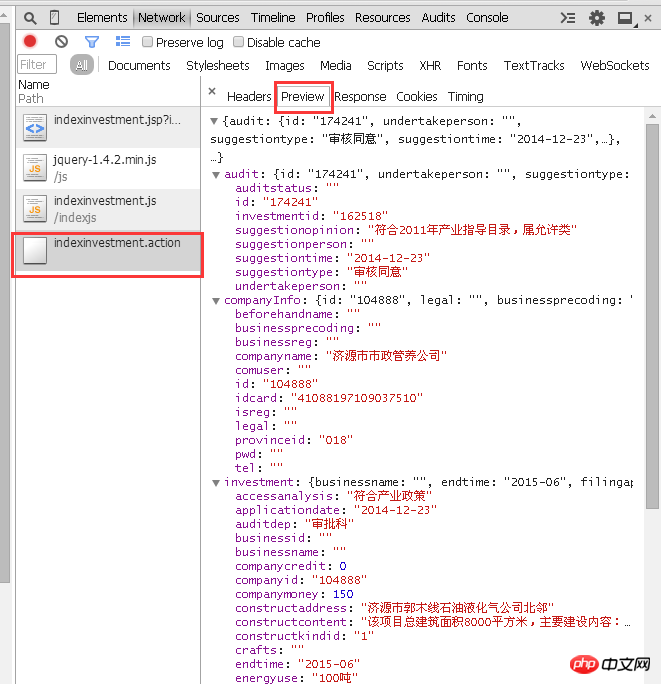
#However, double-clicking to open this file does not obtain corporate information, but a bunch of code. Because there is no corresponding parameter to indicate which number of information to display. As shown in the picture:

So, how should the parameters be passed to it? At this time we are still looking at the F12 window:
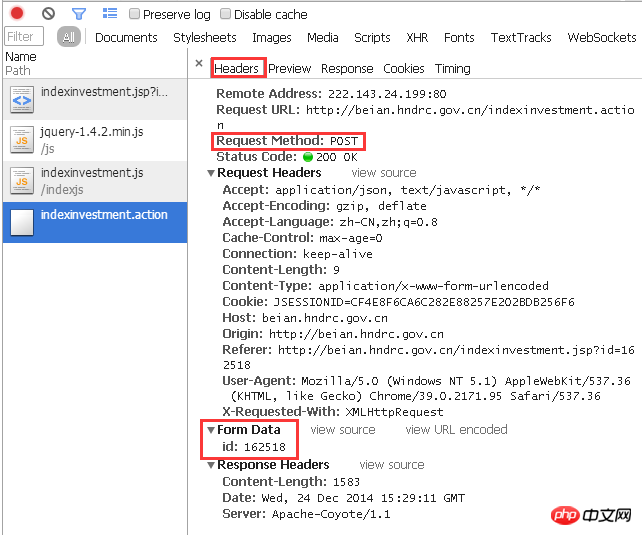
The "Header" column clearly shows the process of this response:
For the target URL, Using POST, a parameter with an ID of 162518 is passed.
Let’s do it manually first. How does js call parameters? Yes, as mentioned above: question mark + variable name + equal sign + number corresponding to the variable. In other words, when submitting the parameter with ID 162518 to the page "http://beian.hndrc.gov.cn/indexinvestment.action", you should add
"?id=162518" after the URL. , namely
"http://beian.hndrc.gov.cn/indexinvestment.action?id=162518".
Let’s paste this URL into the browser to see:

It seems that there is some content, but it is all garbled. How can I break it? Familiar friends may see at a glance that this is an encoding problem. It's because the content returned in the response is different from the browser's default encoding. Just go to the menu in the upper right corner of Chrome - More Tools - Coding - "Automatic Detection". (Actually, this is UTF-8 encoding, and Chrome defaults to simplified Chinese). As shown below:
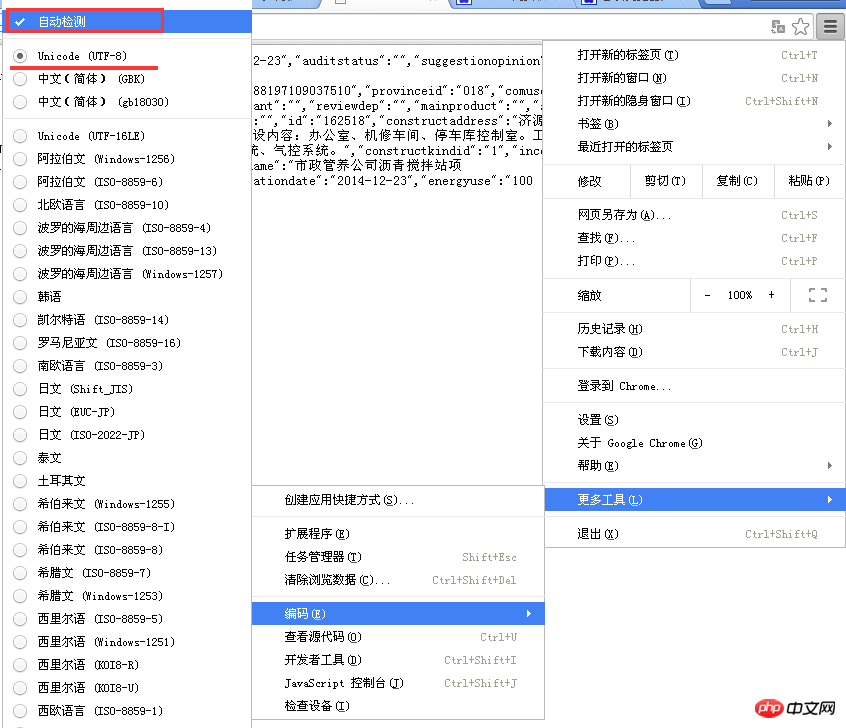
Okay, the real information source has been dug out. All that’s left is to use Python to process the strings on these pages, and then cut and splice them. A new "Project Filing Document" has been reorganized.
Then use for, while and other loops to obtain these "Registration Documents" in batches.
Just as "Whether it is a static web page, a dynamic web page, a simulated login, etc., you must first analyze and understand the logic before writing the code", the programming language is just a tool, and the important thing is the idea of solving the problem. . Once you have an idea, you can then look for tools to solve the problem, and you'll be good to go.
The above is the detailed content of Example sharing of python dynamic crawler. For more information, please follow other related articles on the PHP Chinese website!

Hot Article

Hot tools Tags

Hot Article

Hot Article Tags

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics




 What are the advantages and disadvantages of templating?
May 08, 2024 pm 03:51 PM
What are the advantages and disadvantages of templating?
May 08, 2024 pm 03:51 PM
What are the advantages and disadvantages of templating?
 Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
Jul 01, 2024 am 07:22 AM
Google AI announces Gemini 1.5 Pro and Gemma 2 for developers
 For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
May 06, 2024 pm 03:52 PM
For only $250, Hugging Face's technical director teaches you how to fine-tune Llama 3 step by step
 Share several .NET open source AI and LLM related project frameworks
May 06, 2024 pm 04:43 PM
Share several .NET open source AI and LLM related project frameworks
May 06, 2024 pm 04:43 PM
Share several .NET open source AI and LLM related project frameworks
 A complete guide to golang function debugging and analysis
May 06, 2024 pm 02:00 PM
A complete guide to golang function debugging and analysis
May 06, 2024 pm 02:00 PM
A complete guide to golang function debugging and analysis


