

Python implements the function of merging two files

This article mainly introduces the function of merging two files in Python in detail. It is a simple file merging program that has certain reference value. Interested friends can refer to it.
This article will It will analyze a file merging program and point out the issues that need to be paid attention to during the file merging process.
The following is an example of the files that need to be merged:
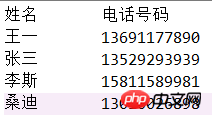

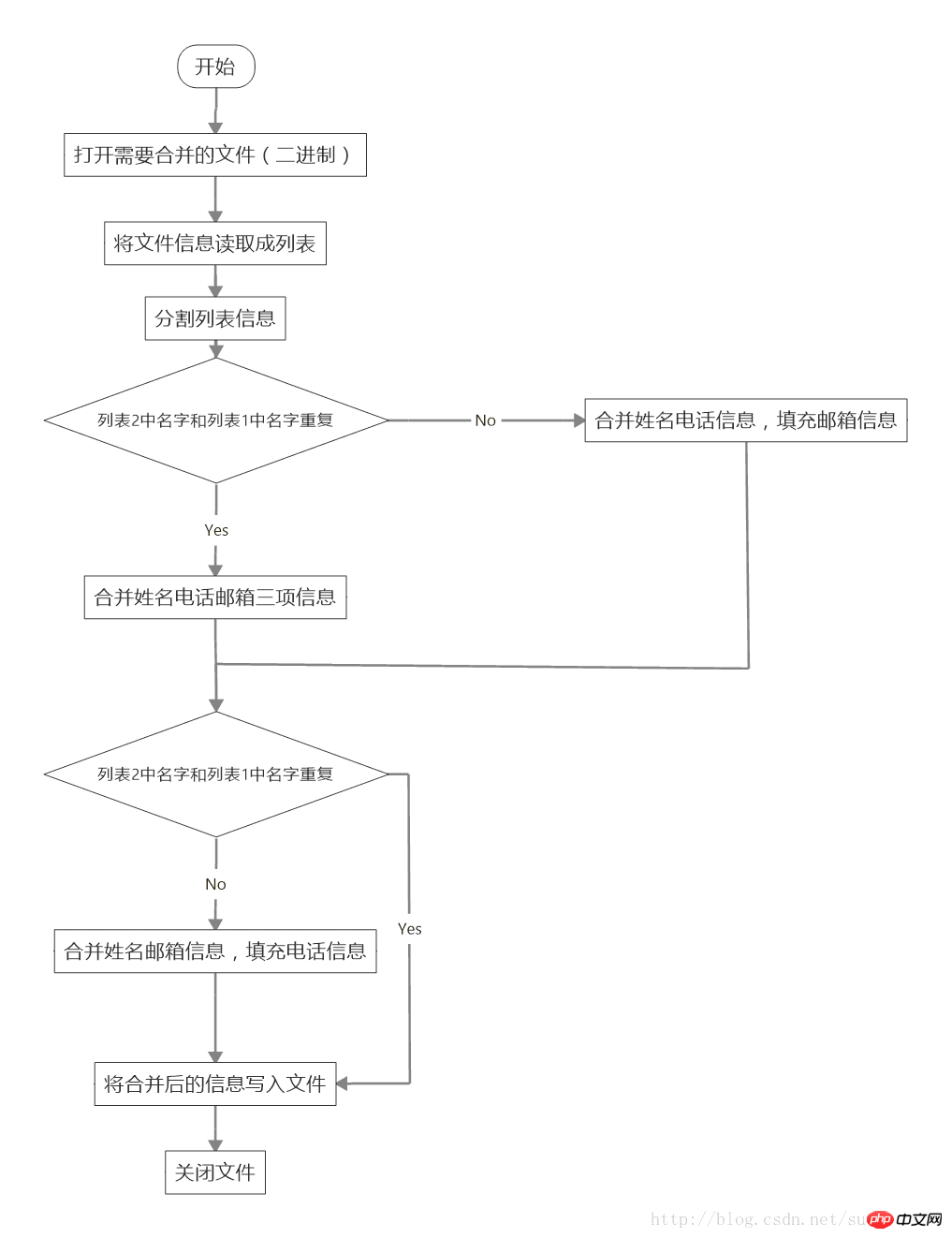
"""
Created on Fri Aug 4 12:59:36 2017
@author: 13323
"""
# This program can combine two or more files into one file.
def main():
#firstly open the files
data1 = open("test_3.txt","rb")
data2 = open("test_4.txt","rb")
# read the data in file into list
data1.readline() #only read one line, skip the first line
data2.readline() #only read one line, skip the first line
file1 = data1.readlines() #read all variable into list file1
file2 = data2.readlines() #read all variable into list file2
#print(file1)
#define particular list to store variable
file1_name = []
file1_tel = []
file2_name = []
file2_email = []
#file3 = []
#split file1 into two part
for line in file1:
element = line.split() #line.split(); devide by ' '
file1_name.append(str(element[0].decode('gbk')))
file1_tel.append(str(element[1].decode('gbk')))
#split file2 into two part
for line in file2:
element = line.split()
file2_name.append(str(element[0].decode('gbk')))
file2_email.append(str(element[1].decode('gbk')))
# pick up the name in the file1 same as the name in the file2 and combine
file3 = []
for i in range(len(file1_name)):
s = ''
if file1_name[i] in file2_name:
j = file2_name.index(file1_name[i])
s = '\t'.join([file1_name[i],file1_tel[i],file2_email[j]])
s += '\n'
else:
s = '\t'.join([file1_name[i],file1_tel[i],str("----")])
s += '\n'
file3.append(s)
#pick up the name in the file1 doesn't same as the name in the file2
for i in range(len(file2_name)):
s = ''
if file2_name[i] not in file1_name:
s = '\t'.join([file2_name[i],str('----'),file2_email[i]])
s += '\n'
file3.append(s)
#write the data into file3
data3 = open("test_5.txt","w")
data3.writelines(file3)
#close the file
data1.close()
data2.close()
data3.close()
main()
Key points:
Encoding and decodingList merging and dismantling
Two pythons implement switching function
Python method to implement management site
The above is the detailed content of Python implements the function of merging two files. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1378
1378
 52
52

 PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python: Code Examples and Comparison
Apr 15, 2025 am 12:07 AM
PHP and Python have their own advantages and disadvantages, and the choice depends on project needs and personal preferences. 1.PHP is suitable for rapid development and maintenance of large-scale web applications. 2. Python dominates the field of data science and machine learning.
 Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Detailed explanation of docker principle
Apr 14, 2025 pm 11:57 PM
Docker uses Linux kernel features to provide an efficient and isolated application running environment. Its working principle is as follows: 1. The mirror is used as a read-only template, which contains everything you need to run the application; 2. The Union File System (UnionFS) stacks multiple file systems, only storing the differences, saving space and speeding up; 3. The daemon manages the mirrors and containers, and the client uses them for interaction; 4. Namespaces and cgroups implement container isolation and resource limitations; 5. Multiple network modes support container interconnection. Only by understanding these core concepts can you better utilize Docker.
 How to train PyTorch model on CentOS
Apr 14, 2025 pm 03:03 PM
How to train PyTorch model on CentOS
Apr 14, 2025 pm 03:03 PM
Efficient training of PyTorch models on CentOS systems requires steps, and this article will provide detailed guides. 1. Environment preparation: Python and dependency installation: CentOS system usually preinstalls Python, but the version may be older. It is recommended to use yum or dnf to install Python 3 and upgrade pip: sudoyumupdatepython3 (or sudodnfupdatepython3), pip3install--upgradepip. CUDA and cuDNN (GPU acceleration): If you use NVIDIAGPU, you need to install CUDATool
 How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
How is the GPU support for PyTorch on CentOS
Apr 14, 2025 pm 06:48 PM
Enable PyTorch GPU acceleration on CentOS system requires the installation of CUDA, cuDNN and GPU versions of PyTorch. The following steps will guide you through the process: CUDA and cuDNN installation determine CUDA version compatibility: Use the nvidia-smi command to view the CUDA version supported by your NVIDIA graphics card. For example, your MX450 graphics card may support CUDA11.1 or higher. Download and install CUDAToolkit: Visit the official website of NVIDIACUDAToolkit and download and install the corresponding version according to the highest CUDA version supported by your graphics card. Install cuDNN library:
 Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python vs. JavaScript: Community, Libraries, and Resources
Apr 15, 2025 am 12:16 AM
Python and JavaScript have their own advantages and disadvantages in terms of community, libraries and resources. 1) The Python community is friendly and suitable for beginners, but the front-end development resources are not as rich as JavaScript. 2) Python is powerful in data science and machine learning libraries, while JavaScript is better in front-end development libraries and frameworks. 3) Both have rich learning resources, but Python is suitable for starting with official documents, while JavaScript is better with MDNWebDocs. The choice should be based on project needs and personal interests.
 How to choose the PyTorch version under CentOS
Apr 14, 2025 pm 02:51 PM
How to choose the PyTorch version under CentOS
Apr 14, 2025 pm 02:51 PM
When selecting a PyTorch version under CentOS, the following key factors need to be considered: 1. CUDA version compatibility GPU support: If you have NVIDIA GPU and want to utilize GPU acceleration, you need to choose PyTorch that supports the corresponding CUDA version. You can view the CUDA version supported by running the nvidia-smi command. CPU version: If you don't have a GPU or don't want to use a GPU, you can choose a CPU version of PyTorch. 2. Python version PyTorch
 How to install nginx in centos
Apr 14, 2025 pm 08:06 PM
How to install nginx in centos
Apr 14, 2025 pm 08:06 PM
CentOS Installing Nginx requires following the following steps: Installing dependencies such as development tools, pcre-devel, and openssl-devel. Download the Nginx source code package, unzip it and compile and install it, and specify the installation path as /usr/local/nginx. Create Nginx users and user groups and set permissions. Modify the configuration file nginx.conf, and configure the listening port and domain name/IP address. Start the Nginx service. Common errors need to be paid attention to, such as dependency issues, port conflicts, and configuration file errors. Performance optimization needs to be adjusted according to the specific situation, such as turning on cache and adjusting the number of worker processes.
 How to do data preprocessing with PyTorch on CentOS
Apr 14, 2025 pm 02:15 PM
How to do data preprocessing with PyTorch on CentOS
Apr 14, 2025 pm 02:15 PM
Efficiently process PyTorch data on CentOS system, the following steps are required: Dependency installation: First update the system and install Python3 and pip: sudoyumupdate-ysudoyuminstallpython3-ysudoyuminstallpython3-pip-y Then, download and install CUDAToolkit and cuDNN from the NVIDIA official website according to your CentOS version and GPU model. Virtual environment configuration (recommended): Use conda to create and activate a new virtual environment, for example: condacreate-n
