

This article mainly introduces the DataFrame in python to implement excel merging cells in detail. It has a certain reference value. Interested friends can refer to it.
I often encounter the need to merge cells at work. The data is output to excel, and some of the cells need to be merged. For example, in the table below, the corresponding cells in columns B and C need to be merged based on the value of column A

2. Define a my_mergewr_excel method. The parameters are: the path to output excel, the key_cols list used to determine whether it needs to be merged, and the list used to indicate which columns of cells need to be merged.
3. Add MY_DataFrame Encapsulated as a My_Module module for reuse.
2 , if it is judged that CN is greater than 1, the group needs to be merged, otherwise the group (row) does not need to be merged (CN=1 means that the data row of this group is unique and does not need to be merged)
3. Corresponding to the group that needs to be merged, judge the current column Whether it is in the given parameter [Merge Column], if so, use merge to write excel cells, otherwise, just write excel cells normally.
4. In the column that needs to be merged, if RN=1, call merge_range and write CN cells at once. If RN>1, skip the cell because RN=1 At that time, the cell has been merged and written. If erge_range is called repeatedly, an error will be reported when opening the excel document.

# -*- coding: utf-8 -*-
"""
Created on 20170301
@author: ARK-Z
"""
import xlsxwriter
import pandas as pd
class My_DataFrame(pd.DataFrame):
def __init__(self, data=None, index=None, columns=None, dtype=None, copy=False):
pd.DataFrame.__init__(self, data, index, columns, dtype, copy)
def my_mergewr_excel(self,path,key_cols=[],merge_cols=[]):
# sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True):
self_copy=My_DataFrame(self,copy=True)
line_cn=self_copy.index.size
cols=list(self_copy.columns.values)
if all([v in cols for i,v in enumerate(key_cols)])==False: #校验key_cols中各元素 是否都包含与对象的列
print("key_cols is not completely include object's columns")
return False
if all([v in cols for i,v in enumerate(merge_cols)])==False: #校验merge_cols中各元素 是否都包含与对象的列
print("merge_cols is not completely include object's columns")
return False
wb2007 = xlsxwriter.Workbook(path)
worksheet2007 = wb2007.add_worksheet()
format_top = wb2007.add_format({'border':1,'bold':True,'text_wrap':True})
format_other = wb2007.add_format({'border':1,'valign':'vcenter'})
for i,value in enumerate(cols): #写表头
#print(value)
worksheet2007.write(0,i,value,format_top)
#merge_cols=['B','A','C']
#key_cols=['A','B']
if key_cols ==[]: #如果key_cols 参数不传值,则无需合并
self_copy['RN']=1
self_copy['CN']=1
else:
self_copy['RN']=self_copy.groupby(key_cols,as_index=False).rank(method='first').ix[:,0] #以key_cols作为是否合并的依据
self_copy['CN']=self_copy.groupby(key_cols,as_index=False).rank(method='max').ix[:,0]
#print(self)
for i in range(line_cn):
if self_copy.ix[i,'CN']>1:
#print('该行有需要合并的单元格')
for j,col in enumerate(cols):
#print(self_copy.ix[i,col])
if col in (merge_cols): #哪些列需要合并
if self_copy.ix[i,'RN']==1: #合并写第一个单元格,下一个第一个将不再写
worksheet2007.merge_range(i+1,j,i+int(self_copy.ix[i,'CN']),j, self_copy.ix[i,col],format_other) ##合并单元格,根据LINE_SET[7]判断需要合并几个
#worksheet2007.write(i+1,j,df.ix[i,col])
else:
pass
#worksheet2007.write(i+1,j,df.ix[i,j])
else:
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
#print(',')
else:
#print('该行无需要合并的单元格')
for j,col in enumerate(cols):
#print(df.ix[i,col])
worksheet2007.write(i+1,j,self_copy.ix[i,col],format_other)
wb2007.close()
self_copy.drop('CN', axis=1)
self_copy.drop('RN', axis=1)import My_Module
DF=My_DataFrame({'A':[1,2,2,2,3,3],'B':[1,1,1,1,1,1],'C':[1,1,1,1,1,1],'D':[1,1,1,1,1,1]})
DF
Out[120]:
A B C D
0 1 1 1 1
1 2 1 1 1
2 2 1 1 1
3 2 1 1 1
4 3 1 1 1
5 3 1 1 1
DF.my_mergewr_excel('000_2.xlsx',['A'],['B','C'])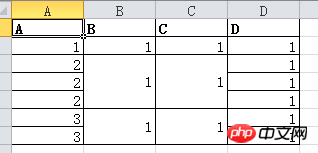
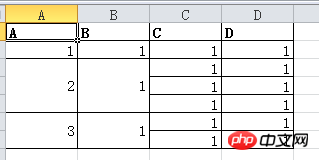
DF.my_mergewr_excel('000_2.xlsx',['A'],['A','B'])
The above is the detailed content of Python's DataFrame implements excel merged cells_python. For more information, please follow other related articles on the PHP Chinese website!
 python development tools
python development tools
 python packaged into executable file
python packaged into executable file
 what python can do
what python can do
 Compare the similarities and differences between two columns of data in excel
Compare the similarities and differences between two columns of data in excel
 excel duplicate item filter color
excel duplicate item filter color
 How to use format in python
How to use format in python
 How to copy an Excel table to make it the same size as the original
How to copy an Excel table to make it the same size as the original
 Excel table slash divided into two
Excel table slash divided into two








![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



