

How to crawl the content in js using python

The content of this article is to share with you 3. How to use python to crawl the content in js. It has certain reference value. Friends in need can refer to it
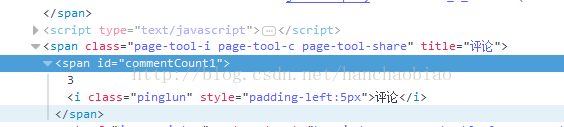
1. When writing crawler software to obtain the required content, you may encounter that the required content is added by javascript and is empty when obtained. For example, when we obtain Sina News The number of comments cannot be obtained using ordinary methods
import requests
from bs4 import BeautifulSoup
res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml')
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
#取评论数
commentCount = soup.select_one('#commentCount1')
print(commentCount.text)
Copy after login
import requests from bs4 import BeautifulSoup res = requests.get('http://news.sina.com.cn/c/nd/2017-06-12/doc-ifyfzhac1650783.shtml') res.encoding = 'utf-8' soup = BeautifulSoup(res.text,'html.parser') #取评论数 commentCount = soup.select_one('#commentCount1') print(commentCount.text)
The result obtained at this time is empty. This is because the content is stored in a js file.
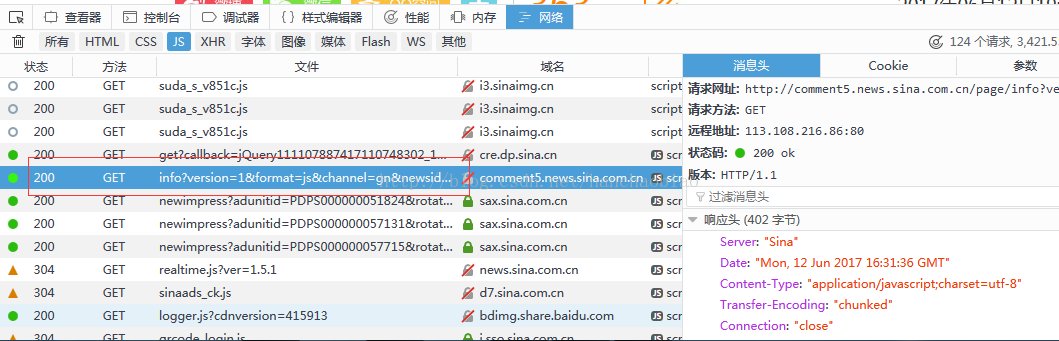
So we need to find the js that stores the comment content. After searching, we found that It is stored in js
Put the corresponding content into the json data viewer and we find that the total number of comments and the content of the comments are both there A json format is stored in the js file
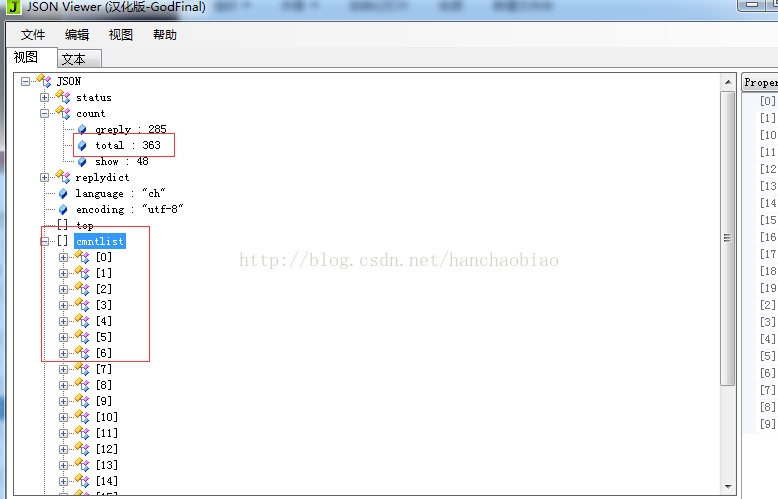
Comment: explained here Why do you need to remove var data=? Because the string prefix includes var data= when getting it, which does not conform to the json data format, so it needs to be removed from the request content during conversion ]['count']['total'] when getting the total number of comments The above is the detailed content of How to crawl the content in js using python. For more information, please follow other related articles on the PHP Chinese website!import json
comments = requests.get('http://comment5.news.sina.com.cn/page/info?version=1&format=js&channel=gn&newsid=comos-fyfzhac1650783')
comments.encoding = 'utf-8'
print(comments)
jd = json.loads(comments.text.strip('var data=')) #移除改var data=将其变为json数据
print(jd['result']['count']['total'])
 Why use jd[
Why use jd[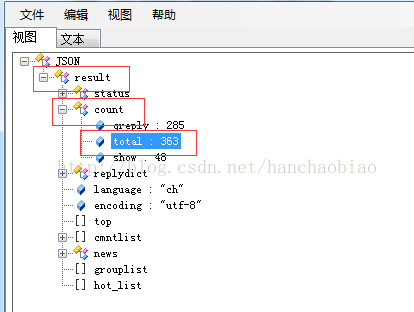

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1386
1386
 52
52

 Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
Is the vscode extension malicious?
Apr 15, 2025 pm 07:57 PM
VS Code extensions pose malicious risks, such as hiding malicious code, exploiting vulnerabilities, and masturbating as legitimate extensions. Methods to identify malicious extensions include: checking publishers, reading comments, checking code, and installing with caution. Security measures also include: security awareness, good habits, regular updates and antivirus software.
 Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
Can vs code run in Windows 8
Apr 15, 2025 pm 07:24 PM
VS Code can run on Windows 8, but the experience may not be great. First make sure the system has been updated to the latest patch, then download the VS Code installation package that matches the system architecture and install it as prompted. After installation, be aware that some extensions may be incompatible with Windows 8 and need to look for alternative extensions or use newer Windows systems in a virtual machine. Install the necessary extensions to check whether they work properly. Although VS Code is feasible on Windows 8, it is recommended to upgrade to a newer Windows system for a better development experience and security.
 How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
How to run programs in terminal vscode
Apr 15, 2025 pm 06:42 PM
In VS Code, you can run the program in the terminal through the following steps: Prepare the code and open the integrated terminal to ensure that the code directory is consistent with the terminal working directory. Select the run command according to the programming language (such as Python's python your_file_name.py) to check whether it runs successfully and resolve errors. Use the debugger to improve debugging efficiency.
 Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
Can visual studio code be used in python
Apr 15, 2025 pm 08:18 PM
VS Code can be used to write Python and provides many features that make it an ideal tool for developing Python applications. It allows users to: install Python extensions to get functions such as code completion, syntax highlighting, and debugging. Use the debugger to track code step by step, find and fix errors. Integrate Git for version control. Use code formatting tools to maintain code consistency. Use the Linting tool to spot potential problems ahead of time.
 Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
Choosing Between PHP and Python: A Guide
Apr 18, 2025 am 12:24 AM
PHP is suitable for web development and rapid prototyping, and Python is suitable for data science and machine learning. 1.PHP is used for dynamic web development, with simple syntax and suitable for rapid development. 2. Python has concise syntax, is suitable for multiple fields, and has a strong library ecosystem.
 Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python vs. JavaScript: The Learning Curve and Ease of Use
Apr 16, 2025 am 12:12 AM
Python is more suitable for beginners, with a smooth learning curve and concise syntax; JavaScript is suitable for front-end development, with a steep learning curve and flexible syntax. 1. Python syntax is intuitive and suitable for data science and back-end development. 2. JavaScript is flexible and widely used in front-end and server-side programming.
 Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang vs. Python: Concurrency and Multithreading
Apr 17, 2025 am 12:20 AM
Golang is more suitable for high concurrency tasks, while Python has more advantages in flexibility. 1.Golang efficiently handles concurrency through goroutine and channel. 2. Python relies on threading and asyncio, which is affected by GIL, but provides multiple concurrency methods. The choice should be based on specific needs.
 What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
What is vscode What is vscode for?
Apr 15, 2025 pm 06:45 PM
VS Code is the full name Visual Studio Code, which is a free and open source cross-platform code editor and development environment developed by Microsoft. It supports a wide range of programming languages and provides syntax highlighting, code automatic completion, code snippets and smart prompts to improve development efficiency. Through a rich extension ecosystem, users can add extensions to specific needs and languages, such as debuggers, code formatting tools, and Git integrations. VS Code also includes an intuitive debugger that helps quickly find and resolve bugs in your code.
